

<개요>
데이터베이스 설계 : 개념적 설계와 물리적 설계로 구분
- 개념적 : 실제로 데이터베이스를 어떻게 구현할 것인가와는 별개로 독립적으로 정보 사용의 모델을 개발하는 과정
-> 전체 업무에 관련된 엔티티와 릴레이션십(관계)으로 이루어진 설계 도면을 만드는 것
- 물리적 : 물리적인 저장 장치와 접근 방식을 다룸
-> 적절한 인덱스를 만들거나 불필요한 인덱스를 지우는 것
- 엔티티 : 서로 구분되는 데이터베이스에 나타나는 객체
- 개념적 수준의 모델 : 특정 데이터 모델(ex. 객체 데이터모델)과 독립적으로 응용세계를 모델링
-> DB 구조나 스키마를 탑-다운 방식으로 개발할 수 있는 틀을 제공
-> ER 모델과 같은 개념적 데이터 모델을 다수의 구현 데이터 모델로 사상(관계 구현단계에서)시킴.


설계 단계 : 하는 일을 세분
DBMS의 선정 : 더 앞 단계에서 할 수도 있음
논리적 설계 : 스키마로 변환 -> DBMS에 의존적으로 진행, 결과로 관계 DB 스키마를 완성
스키마 정제 : 정규화
물리적 설계 : 각각의 릴레이션에 적절한 인덱스를 만듦
보안 설계 : 권한 설정
-> 논리적 설계를 잘 하면 아래의 것들은 할 게 별로 없음
-> 한 번이 끝이 아니라, 앞 뒤 단계로 왔다갔다
할 필요가 있음.

- 개념적 설계 : ANSI SPARC 3단계 아키텍처에서 개념 단계에 해당함. 개념 단계의 구성요소를 만듦. 테이블들의 모임을 만들어내고, 물리적인 구조는 신경쓰지 않음
-> 엔티티 타입, 컬럼 등을 나타내는 기호가 다 다름 -> 이런것들을 식별, 도메인 결정, 후보키 기본키를 결정
- ER 모델 : 관계 데이터 모델보다 추상화 수준이 높음 -> 완성된 개념적 스키마는 ER다이어그램으로 표현
- DMBS 선정 요인 : 기술적 요인(구조, 질의어, 도구, 서비스), 정치적 요인, 경제적 요인

- 논리적 설계 : 개념적 스키마에 7단계 알고리즘을 하나씩 적용하면, 릴레이션들의 모임(논리적 스키마)이 만들어짐
-> 관계 데이터 모델 사용시 ER 모델로 표현된 개념적 스키마를 관계 DB 스키마로 사상
-> 개선하기 위해 정규화 과정 적용, 앞을 건너뛰고 논리적 설계 단계로 가면 좋은 스키마가 새성되지 않음

- 물리적 설계 : 저장 구조와 접근 경로 결정 -> 인덱스가 주 대상
- 성능상의 기준 : 응답 시간(질의와 갱신이 평균과 피크 시간 때 얼마나 걸리는가), 트랜잭션 처리율(같은 때에 초당 얼마의 트랜잭션을 처리), 전에 DB에 대한 보고서를 생성하는 데 얼마나 걸리는가

- 트랜잭션 설계 : 응용 프로그램을 설계. 요구사항 수집과 분석 후 혹은 설계 중이나 끝난 후 진행
- 기작선 트랜잭션 : DB에서 동작하는 응용 프로그램. 개발자가 만들어 최종 사용자가 반복 사용
- 데이터베이스 스키마는 트랜잭션에서 요구하는 모든 정보(테이블, 컬럼)를 가지고 있어야 함.
<ER모델>


- System R 프로젝트가 진행중이던 시기 피터 첸이 제안 -> 현재는 EER 모델이 설계 과정에 널리 사용
-> 궁극적으로는 릴레이션으로 변환해야 하여, 이 것으로 모델링 하는 것은 크게 의미 없음
- 높은 수준의 추상화, 이해가 쉬움, 구문 표현력 뛰어남, 응용에 대한 사람의 생각 방식과 가까움, 많은 CASE 도구에서 지원 -> 인기 짱~
- 실세계를 엔티티, 애트리뷰트, 엔티티 간 관계로 표현 -> 쉽계 관계 데이터 모델로 사상됨
- 기본 구문 : 엔티티(직사각형), 관계(다이아몬드), 컬럼(타원)
- 기타 구문 : 카디날리티 비율, 참여 제약조건
-> 표기법이 쉽다! 자연어보다 formal하고, DBMS와는 독립적임
- 이를 바탕으로 만들어진 ERWin, DA# 같은 CASE 도구들은 타겟 DBMS를 선택하여 테이블 정의로 변환
-> DDL or XML로 변환


- 엔티티 : 독립적으로 존재하며 고유히 식별 가능한 실세계의 객체
- 엔티티 타입 : 설명 보면 됨. 하나의 엔티티는 여러 엔티티 집합에 중복해서 속할 수 있음.

- 엔티티 타입 : 직사각형, 그 안에 이름을 씀
-> 이 안에 엔티티들이 인서트문으로 들어오게 됨.
엔티티 타입과 엔티티 집합은 다르나, 엄격히 구분할 필요는 없음. 문맥상으로 이해한다!

- 강한 엔타입 : 대부분의 엔타입. 독자적으로 존재, 키 애트리뷰트를 사용하여 고유하게 엔티티들을 식별함.
- 약한 엔타입 : 키를 형성하기에 충분한 컬럼을 갖지 못함 -> 릴레이션이라 말 할 수 없음.
-> 6장의 알고리즘의 7단계 중 특정 단계를 적용하면 릴레이션으로 만들 수 있음
- 소유 엔타입or식별 엔타입 : 약한 엔타입에 키 컬럼을 제공 -> 얘들은 강한 엔타입
- ER다이어그램에서는 약한 엔타입을 이중선 직사각형으로, 강한 엔타입을 하나의 실선 직사각형으로
- ER다이어그램에서 부분키 : 점선 밑줄로 표시
ex) 사원이 있으면, 부양가족이 있을 것. 한 집안의 구성원들의 이름을 똑같이 하진 않지만, 다른 사원의 가족과 이름이 같을 수 있음
→ 한 가족 내에서는 식별 가능하기 = 키 역할 가능 → 부양가족 테이블 다 모아놓으면, 중복될 수 있음(=키역할불가)


- 애트리뷰트 : 어느 엔티티를 설명하는 역할을 함.
- 애트리뷰트가 동일한 도메인을 공유할 수 있음.
-> 키 애트리뷰트는 컬럼 하나, 혹은 몇 개를 모아서 한 엔타입에 들어올 각 엔티티를 고유하게 식별
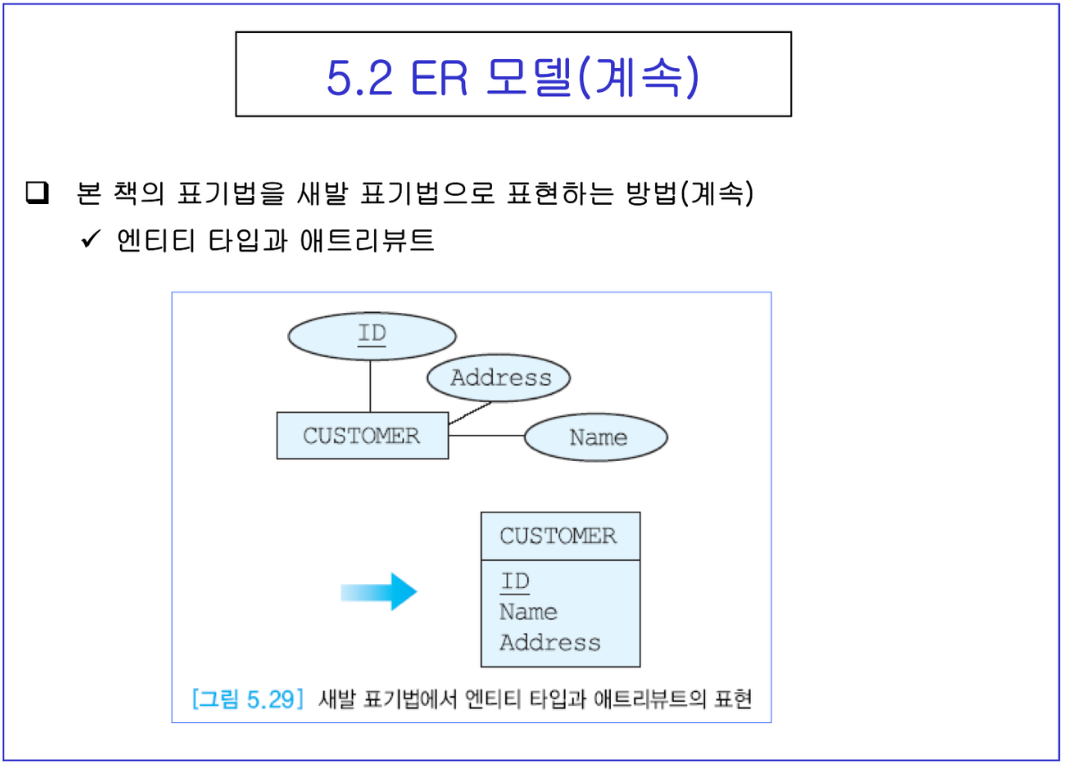
- 애트리뷰트는 대부분 명사로 표현, ER다이어그램에서 타원으로 나타냄


- 커스터머가 강한 엔타입. 이 엔타입을 설명하는 컬럼이 3개고 ID가 기본키겠지?
- Address를 시 구 동 우편번호로 쪼갬 -> 주소는 복합 애트리뷰트.


- 단일 값 애트리뷰트 : 대부분의 애트리뷰트. 각 컬럼에 원자값(단일값)이 와야함.
- 다치 애트리뷰트 : 각 엔티티마다 여러 개의 값을 가질 수 있는 애트리뷰트. 관계 데이터 모델에서 허용되지 않음.
-> 관계 모델의 릴레이션으로 변환되려면 알고리즘의 7단계 중 한 단계를 거쳐야함.


- 대부분의 애트리뷰트는 저장된 애트리뷰트
-> 단순 + 단일값 + 저장 애트리뷰트가 일반적인 애트리뷰트
- 유도된 애트리뷰트도 저장되긴 함. 다른 컬럼의 값으로부터 구할 수 있음. 일반적으로 관계모델에서 포함X.

- Empno : 기본값
- Age : 유도된 애트리뷰트
- Address : 복합 애트리뷰트
- Hobby : 다치 애트리뷰트
- Name : 평범한 일반적인 애트리뷰트


- 약한 엔티티 타입 : 키를 형성하기에 충분한 애트리뷰트들을 갖지 못한 엔타입
-> EMPLOYEE가 소유 엔타입 또는 식별 엔타입
-> EMPLOYEE의 기본키를 외래키로 빌려줌 -> 그 외래키와 원래 있던 부분키를 합치면 DEPENDENT의 기본키가 됨.

- 관계는 엔티티 사이에 존재하는 연관이나 연결로 두 엔타입 사이의 사상으로 생각할 수 있음
- 관계 타입이 연관시키는 엔타입들을 관계 타입에 실선으로 연결함


EMPLOYEE(명사) - WORKS_FOR(동사) - DEPARTMENT(명사)
- 관계는 동사로, 엔티티나 컬럼은 명사로 나타낸다. 더이상 쪼갤 수 없으면 애트리뷰트, 설명이 필요한 명사는 엔티티.
- 관계도 관계의 특징을 기술하는 컬럼을 가질 수 있고, 키 애트리뷰트는 가지지 않음

관계 타입에 붙어있는 엔타입의 개수에 따라,
- 1진 관계 : 순환 관계 or 포함 관계 / 2진 관계 : 가장 많음 / 3진 관계 : 2진 관계 2개로 나눌 수 없음


- 제일 흔한게 1:N 관계
- M:N 관계는 관계 모델에서 나타낼 수 없지만, 실세계에 존재하여 ER다이어그램으로 그릴 수 있음
-> 알고리즘의 한 단계를 통해 해결해야함


- M:N 관계는 수강을 생각하면 가장 좋음


- 어떤 관계 타입에 참여하는 각 엔타입에 대해 min은 적어도 min번, max는 최대 max번을 의미
- min이 0이면 반드시 관계에 참여할 필요 없다 = 부분 참여, max = n이면 n만큼 참여할 수 있다.
- 우측 표가 헷갈릴 수 있음. 1:1 에서 (0,1)은 관계에 참여를 안하거나 최대1개 -> 부분참여 + 참여시 1:1 관계
-> 1:N 에서 (0,*)이니까 참여를 안하거나 최대 *개 -> 부분참여 + 참여시 1:N 관계
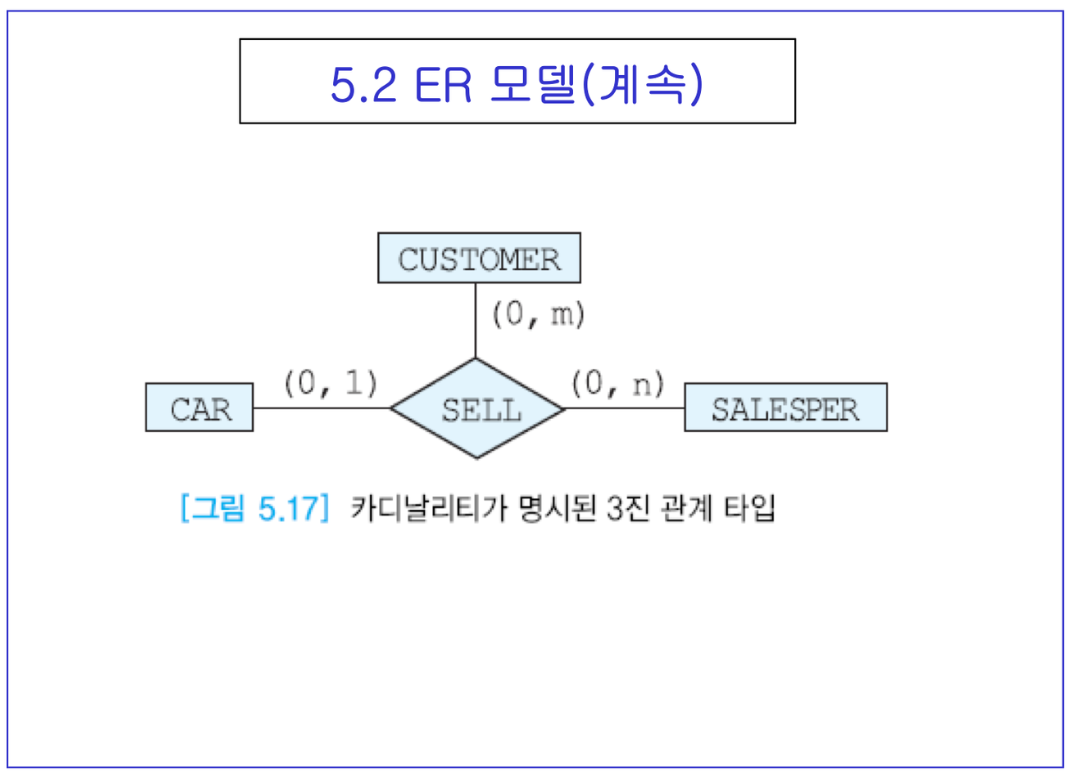
- 커스토머 : 차를 안 살 수도, m대 살 수도 있음
- 세일즈퍼 : 어떤 날은 못 팔고, 어떤 날은 n대 까지 팔고
- car : 특정 차를 여러대 팔 순 없음. 0 : 안팔림, 1 : 팔림
-> SELL이라는 관계를 통해 3진 관계를 이룰 수 있음

- 역할은 보통 필요없고, 관계 데이터 모델에 넣는 것도 어려움
-> EMPLOYEE에서 한 명의 대리가 여러 사원을 거느린다면, 1:N으로 관계를 참여하는데, 역할을 표시해줘야함
-> 의미를 명확히 하기 위해 사용

- 사원과 디파트먼트가 매니지스(책임자)로 연결
ex) D1부서에 사원ABCD, D2부서에 사원EFGH가 있고 사원코드는 1234,5678,...
부서의 책임자를 맡는 사람이 더 적으니까 그걸 EMP 테이블 내부에서 나타내면 null값이 많이 나타남
-> DEPT에 두고, 부서마다 책임자가 있어야 하니까 DEPT와 매니지스의 관계는 전체 참여, EMP와 매니지스 관계는 부분참여가 됨.


- 다중 관계 : EMP와 PROJ가 두 관계 타입을 사용해서 연결
- 순환적 관계 : PART에서 관계에 두 번 이상 참여 -> EMP에서, 직속 상사와 부하직원 같은 것(1:N)


- ER 스키마를 작성하는 가이드라인
- 다치 애트리뷰트는 관계 모델에서 허용하지 않기에, 엔티티로 독립시켜야함 -> 알고리즘이 해결해줌
- 가능한 단일 키 컬럼으로
- 관계에 컬럼이 붙음 -> 키컬럼을 가지고 엔타입으로 모델링 될 수 있음


- 엔타입 : 명사, 관계 타입 : 동사
- ER 표기법은 진부하지만 표준의 의미를 가짐
-> 공간을 너무 많이 차지함. 실용성 없음(DBMS없던 76년도 개발)


- 새발 표기법 : 특정 상용 시스템에 사용하는 표기법 -> 시험에 낼 수 없음



- 대충 이미지 참고. 부분 참여와 전체 참여도 고려

- 짝대기에서 바깥쪽 : 1:N 의미
- 짝대기에서 안쪽 : 전체참여와 완전참여 -> 실제 모델링시 엄격히 그리진 않음. 연산에 오류가 많이 발생함
'UOS@DB' 카테고리의 다른 글
| 6장 물리적 DB 설계(버퍼,디스크,인덱스 등) (0) | 2023.12.07 |
|---|---|
| 5장 데이터베이스 설계와 ER모델(설계 사례 분석 및 릴레이션으로의 사상) (4) | 2023.12.03 |
| 4장 관계대수와 SQL(트리거, 내포된 SQL) (1) | 2023.11.05 |
| 4장 관계대수와 SQL(SELECT 및 삽입 삭제 수정문) (0) | 2023.11.05 |
| 4장 관계대수와 SQL ( SQL 개요, 데이터 정의어, SELECT문1/2) (0) | 2023.11.04 |