

- 집합연산 : UNION, EXCEPT, INTERSECT, UNION ALL, EXCEPT ALL, INTERSECT ALL
-> 합집합 호환성을 가져야 집합 연산 가능
-> ALL : 중복 허용, UNION : 중복 비허용
- 중복이 없어야한다 : 릴레이션의 투플들의 집합에서나 제한된 것. 테이블에 레코드를 집어넣을 때 막을 필요가 없다. -> 오히려 성능저하가 일어날 수 있음 : bag이라고 함. 중복된 값이 여러 테이블에 존재 가능.

김창섭의 부서번호 : 2, 개발부의 부서번호 3
-> 두 릴레이션의 컬럼 수가 같고, 도메인이 같으니까 합집합 가능.
- 조인 : 관계 데이터 모델의 핵심 연산 -> 이걸 쓰지 않고는 못배긴다!
- FROM절에서 보통 2~3개 정도의 릴레이션을 JOIN함.
- WHERE절에서 보통 기본키와 외래키 관계(도메인이 같음)를 갖는 컬럼을 조인, 비교연산자로 연결
- C가 둘 중 한 테이블에서 기본키일텐데, 참조 무결성 제약조건이 깨지고 있음 : 잘못된 예시
- 조인 조건을 생략하거나, 잘못 표현하면 카티션 곱이 생성
- 과정 : 조건에 만족하는 투플 찾기 -> SELECT절에 명시된 애트리뷰트 프로젝션 -> 중복 배제(선택)
- 두 릴레이션의 조인 애트리뷰트 이름이 같다면 애트리 뷰트 이름 앞에 릴레이션 이름이나 투플 변수를 사용해야함.
-> 구분해줘야 한다!


- 보통 외래키를 가진 릴레이션의 투플 수 만큼 결과값이 생기게 됨.
- EMPLOYEE : outer relation, DEPARTMENT : inner relation
- 하나씩 비교해서 매칭되는 것을 끄집어내면, 사용자가 원하는 것을 프로젝션 하여 생성함.
- DNO는 외래키니까 인덱스가 없지만, 반드시 추가하라고 권장함.
- 외래키는 중복될 수 있고, 기본키는 중복 없으면서 인덱스가 있지?
-> 아우터에서 이너로 찾으면 7*1번 찾는데, 디팥먼트가 아우터라면 1~4 가지고 7번 찾아야해서 4*7번 찾아야함.
-> 어느 것을 아우터로 두느냐가 성능에 큰 영향을 준다!

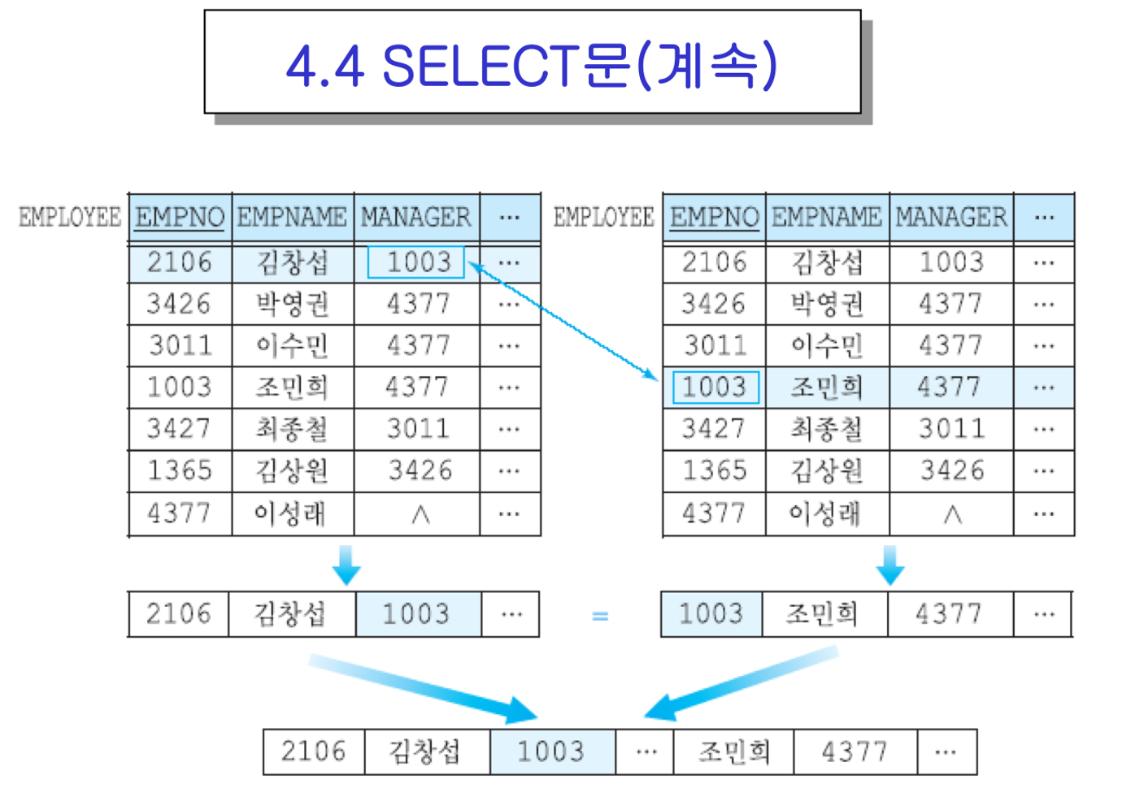
- 자체 조인 : 동일 릴레이션에 속하는 투플들끼리 조인하는 것
- POINT : 실제로는 한 릴레이션에 접근하지만, FROM절에서는 두 릴레이션이 참조되는 것처럼 별칭을 정해줘야함.
- 이성래의 경우 직속상사가 없어 조인 불가 -> 이런걸 나타내기 위해 외부조인이 도입됨.

이렇게, 조인하면서 ORDER BY 할 수 있음. 오름차순은 디폴트지만, 명시하는게 명확하니 꼭 나쁘진 않음.

- 조인 방법은 크게보면 3가지 -> DBMS마다 다 구현하고 상황에 따라 선택하거나, 안되는건 빼곤 함.

- Nested : 하나씩 다 비교 -> 튜플 수 만큼 비교함.
- Merge : 오름차순으로 정렬 한 후 두 테이블을 한번씩만 훑으면 조인이 끝남
-> 정렬 비용은 안따지지만, 주기억장치의 버퍼에 몇 개의 블록이 있냐에 따라 성능 좌우
- Hash : 해시함수를 적용해서 나머지를 가운데 넣자는 것. + 가운데 블록이 2개여야함.
-> 키 값이 다르지만 해시함수의 결과가 같아지는 충돌이 있을 수 있음. 그럼 그 안에서만 비교하면 됨.

- 소트할 때 블록에 들어온게 같은지 nasty하게 비교해야하지만, 주기억장치에서 하기에 무시한다는것.
- 기본키(Deptno)를 오름차순으로 -> EOF만나면 끝. 남아도 조인에 참여 못함.


- Nesty 조인을 보완해주는 시퀀셜 스캔 : 셋업 과정(비용)이 없음 -> 작은 테이블에서 사용
- 인덱스 스캔 : 네스티 조인은 aag에 대해 7개 레코드를 다 읽어야하는데, 이걸 줄이기 위해 인덱스 스캔을 사용함.
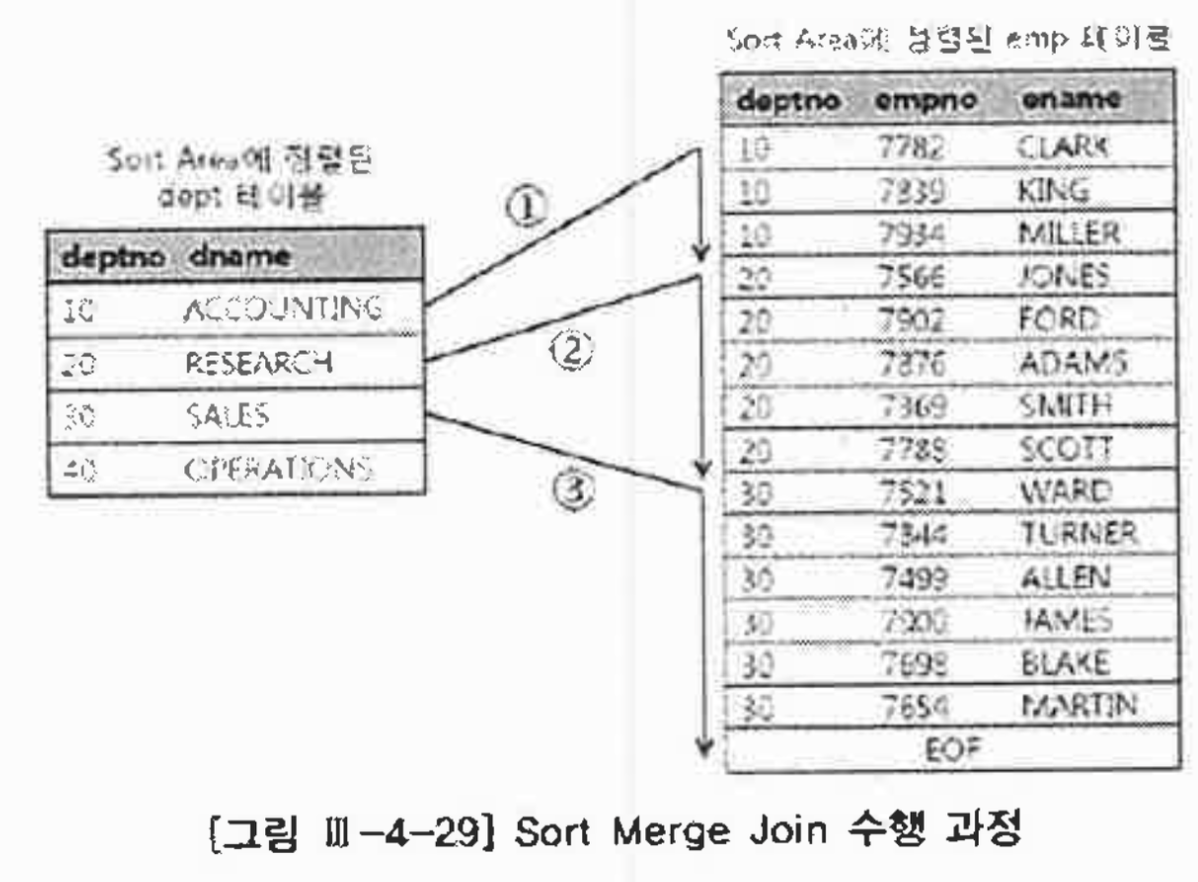
1번 : 10쭉 찾고 20 나오니까 멈춤
2번 : 멈춘 지점부터 20 쭉 찾고 30나오면 멈춤 뭐 이런식!

- 이런식으로 해시 조인이 진행됨. 나머지에따라 잘 나눠 담음.
POINT : 나누는 수를 잘 찾도록 해야함 -> 동적 해싱도 있음.


- 중첩질의(부질의) : 외부 실렉트문 안에 WHERE절에 중첩 질의문이 포함되어있음
결과는 3가지 케이스
1) 컬럼 1개, 레코드 1개
2) 컬럼 1개, 레코드 여러개
3) 컬럼 여러개, 레코드 여러개
-> 기본키 값이 어떤 케이스와 같은지 확인해볼 수 있다(?)


박영권의 타이틀을 구해줘 -> 과장이 프로젝션되어 외부 실렉트문으로 가게 됨.
- EMPNAME을 unique로 지정(대체키)했기에 단일 값이 나올 것을 알 수 있다. 그래서 = 연산자 쓴 것.
-> 값이 여러개 나올거라면 비교연산자 in을 사용하면 가능해질 수 있음.
이미지에 있는 것 처럼,
- IN : 한 애트리뷰트가 값들의 집합에 속하는지를 볼 때
- ANY : 한 컬럼의 값들의 집합에서 하나 이상의 값과 관계를 갖는지를 볼 때
- ALL : 한 컬럼의 값들의 집합에서 모든 값들과 관계를 갖는가를 볼 때

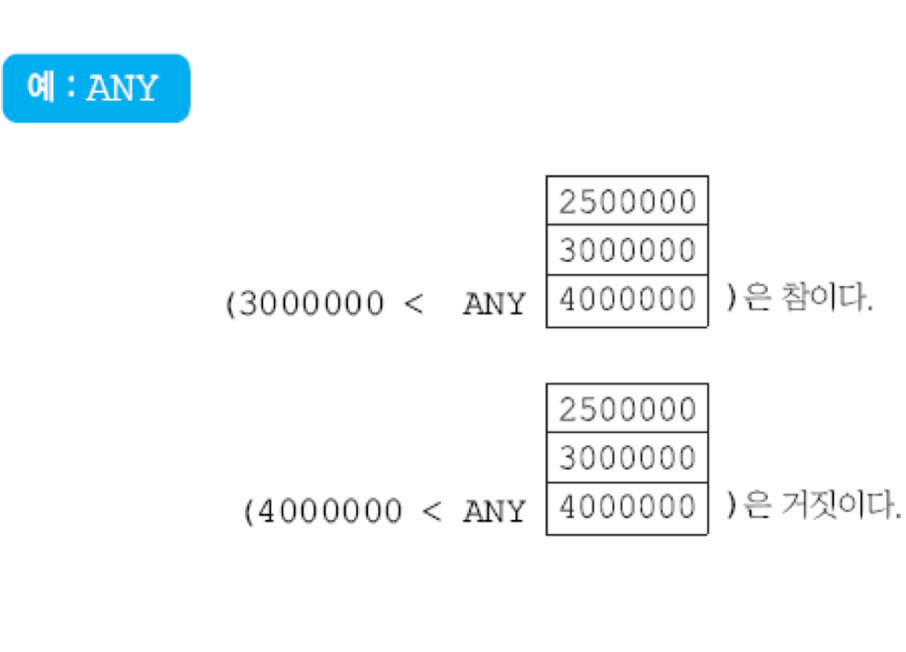

- IN : 3426이 저 3개 값 중에 존재하면 참
- ANY : 3개 값 중 적어도 하나가 조건을 만족하면 참
- ALL : 3개 값 모두 만족하면 참


- 좌측에서, IN이 아닌 =면 오류가 날 것. 왜 ? (1, 3)이 리턴될거니까.
- 우측에서, 중첩질의를 사용한 질의는 대부분 없앨 수 있음. JOIN 질의로 표현 가능.
-> DBMS는 중첩질의 아닌 것을 선호함.

- 중첩질의 결과로 여러 애트리뷰트로 이루어진 릴레이션이 반환된다면, EXISTS 연산자를 통해 빈 릴레이션인지 검사함 -> 비었다면 거짓

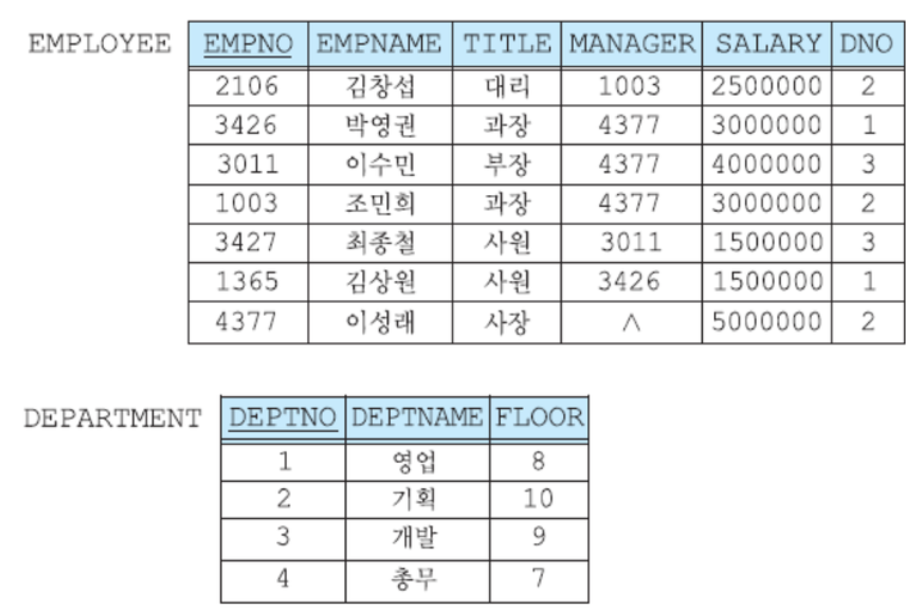
- 외부 질의의 E가 중첩 질의에 사용(E와 D를 JOIN)
-> 김창섭은 빈 릴레이션이 나옴. 박영권은 1,영업,8 이런 3개짜리 레코드 하나가 반환됨
-> 존재하니까 EXISTS에서 참이고 사원 이름만 골라서 사용자에게 고지하게 됨.
- 이 질의는 중첩질의를 바깥쪽 릴레이션의 투플 수 만큼 불러와야함 -> 굉장히 비효율적이다!!


- 상관 중첩 질의 : 중첩질의의 WHERE절에 있는 프레디키트에서 외부 질의에 선언된 릴레이션의 애트리뷰트를 참조하는 질의
-> 외부 질의로 한 번만 결과를 반환하면 상관 중첩 질의가 아니다.
- 상관 중첩 질의는 외부 질의를 만족하는 투플을 구한다음 중첩 질의가 수행되기에, 외부 질의를 만족하는 투플 수 만큼 질의가 반복하여 수행될 수 있음.
ex) 김창섭 : 250만원인데 이게 250만원보다 크지 않기에 탈락
-> 결과적으로 중첩질의(sub query)가 7번 호출될 것임.
<INSERT, DELETE, UPDATE>

- INSERT : 기존의 릴레이션에 투플을 삽입 -> 참조하는 릴레이션에 삽입시 참조 무결성 제약조건 위배 가능
-> 한 번에 한 투플씩 삽입할 수도 있고, 한번에 모든 투플을 삽입할 수도 있음.
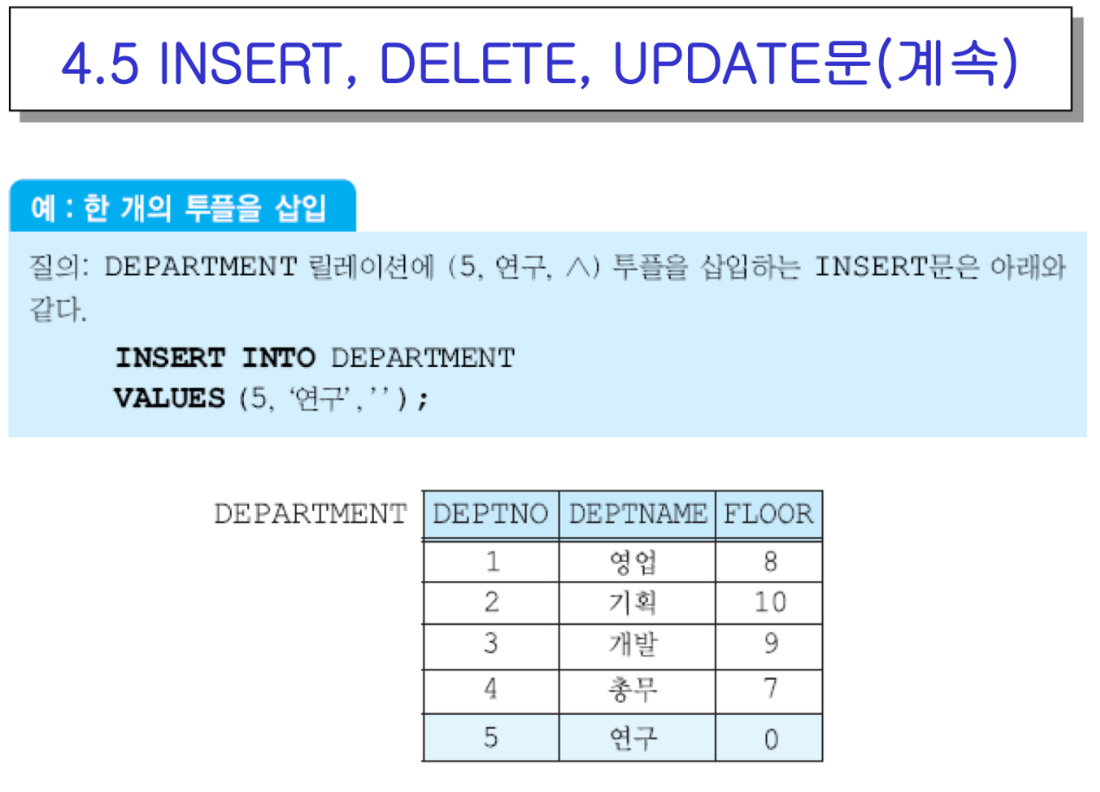

- 0이 아니라 널 값이 채워지는게 맞음(?)
- 여러개의 경우 0개 이상의 레코드가 발견되면 차례로 넣는다.


- 참조되는 릴레이션에서 투플을 삭제하면 참조 무결성 제약조건이 위배될 수 있음

- UPDATE : 레코드를 늘리거나 줄이는게 아닌, 하나 이상의 컬럼의 값을 수정함
'UOS > UOS@DB' 카테고리의 다른 글
| 5장 데이터베이스 설계와 ER모델(DB설계 개요, ER모델) (0) | 2023.11.27 |
|---|---|
| 4장 관계대수와 SQL(트리거, 내포된 SQL) (1) | 2023.11.05 |
| 4장 관계대수와 SQL ( SQL 개요, 데이터 정의어, SELECT문1/2) (0) | 2023.11.04 |
| 4장 관계대수와 SQL (4.1 관계대수) (0) | 2023.11.04 |
| 3장 오라클 (1) | 2023.11.03 |