


- 논리설계의 결과로 릴레이션들의 모임이 정해지면, 그걸 채우는 레코드들이 디스크에 저장됨.
어떻게 릴레이션에 해당하는 파일의 구조를 디스크에 표현할 것인가 -> 인덱스(저장구조)



- 기록 : 즉시 < 나중 → RAM에서 데이터가 변경될 때 마다 디스크에 기록한다?
→ 디스크 접근 시간은 많이 걸리기 때문에 최대한 늦췄다가 한번 기록하는게 좋음.
- 디스크에서 블록을 읽어오는데는 seek time, rotation delay, transfer time(거의 무시)


- 버퍼는 디스크블록들을 저장하는데 사용하는 주기억장치 공간.
- 버퍼 관리자(매니저) : 운영체제의 구성요소.
- LRU : 랜덤 접근할 땐 괜찮은데, 데이터베이스에서는 순차로 읽고 바로 버려도 됨.
→ LRU는 또 읽을지 모르니까 버퍼에 두게 되는데, 데이터베이스에서는 한번 읽으면 바로 버려도 됨. 읽고 나면 땡.
- 우측 이미지는 위가 Ram, 아래가 HDD 버퍼를 할당하고, 거기에 24개의 페이지가 있음.
- 수강신청시 느려짐(동시접속) : 수많은 다른 데이터에 대한 요청을 함 → 다양한 조각들을 버퍼에 가져와야하지 → 기다려야 함.
- 꽉 차면 비워줘야 새 블록을 읽을 수 있음. → 시간을 따진다. 혹은 뭐 참조 빈도를 따진다(?)
- 주기억장치에 올라와있는 프레임 넘버, 페이지 id 등을 유지한다. → 참조하려는게 이미 버퍼에 있는지 디스크에만 있는지를 구분하고, 뭐 누굴 올려보내고 누굴 내려보내고 하는 것들을 DBMS의 버퍼 관리자가 이런 역할을 함. OS는 LRU를 많이 쓰니까 성능에 부정적일때가 많음.


- OS가 관리하는 파일에서는 한 블록에 한 파일에 속하는 데이터만 저장함.
- DBMS가 관리하는 블록에서는, 한 블록안에 임플로이와 디파트먼트를 섞을 수도 있음.
→ 함께 접근하는 경우가 많을 때를 고려하는 취지임. 이런걸 지원하는 DBMS도 있음.
- 인접하면 시크타임, 로테이션딜레이가 없으니까. DBMS는 가능하면 한 파일을 구성하는 블록들을 인접지역에 구성하려고 노력을 함!

- 오라클에서 블롭 크기 : 4GB
- 채우기인수 : 각 블롭의 최초의 레코드를 채우는 비율(?) → 새 레코드가 기존의 블롭의 빈자리에 들어갈 수 있음.

- 2번째 레코드를 지운다 → 빈공간이 됨 → 블롭 안에 빈 공간이 흩어져있음
→ 새 레코드를 수용하기 위해 빈 공간을 모으는 것이 좋음. 메모리 관리에 불편하니까.
→ 위의 케이스에서는 36바이트(2레코드)가 이동. 주기억장치 내에서의 이동이니까 시간이 많이 걸리는 것은 아님.
-> 아래 케이스에서는 순서가 오름차순은 아니지만, 18바이트만 이동하면 됨. BUT 항상 가능한 것은 아니다.


한 블록 안에 레코드가 2,3개 있는데. 그림엔 표현이 안되었지만 빈공간도 있을 것.
- 이렇게 1번 이미지 처럼 모아놓으면 group by할 때 도움되겠지.
->한 화일 내의 레코드들을 연관성이 높은 것 끼리 모아서 저장하는게 intra-file clustering.
2개 이상의 연관된 다른 파일의, 릴레이션의 레코드들 레코드들을 함께 저장하는게 inter-file clustrering.

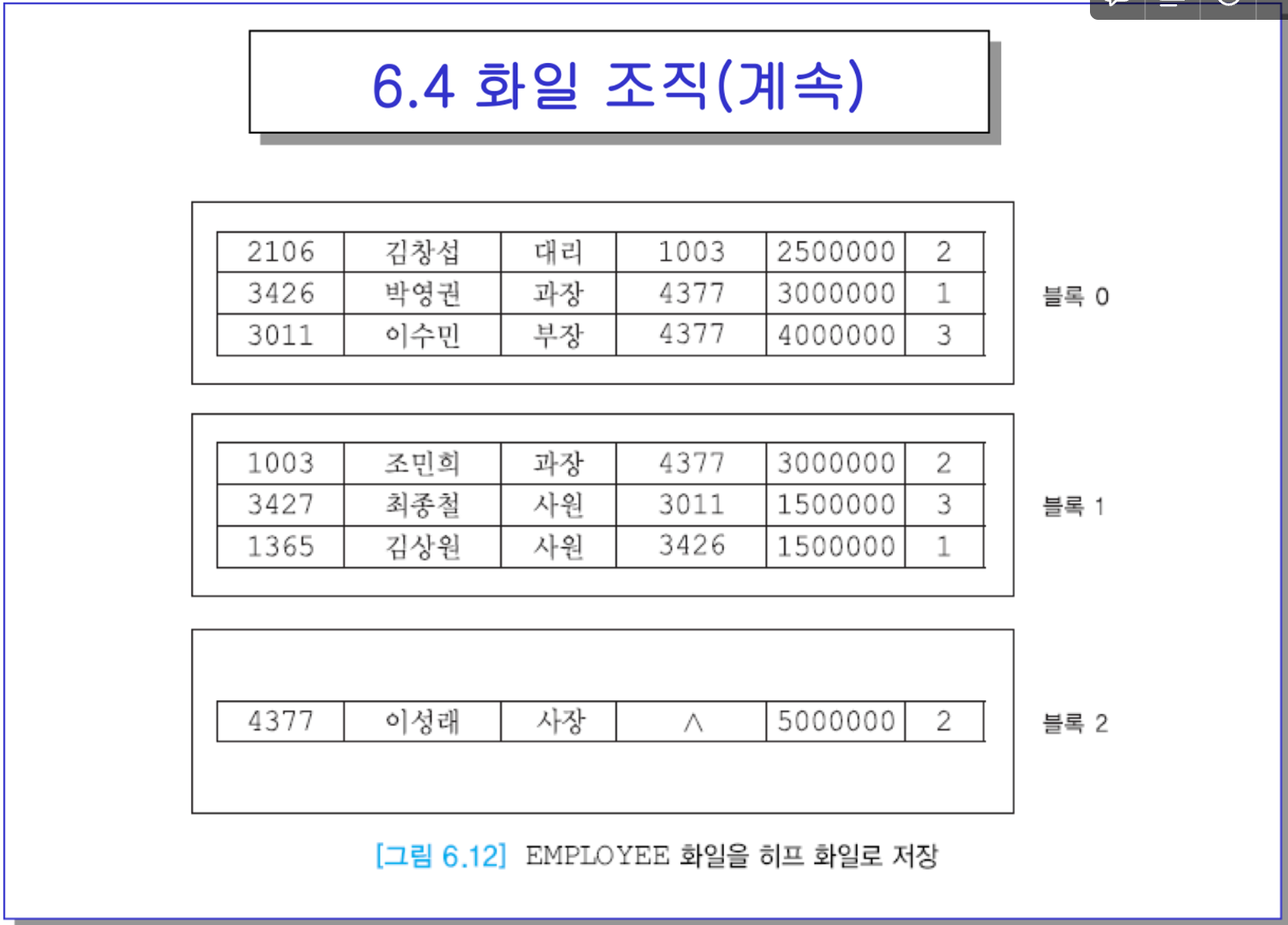
- 히프 화일 : 아~무 순서가 없음. 그냥 삽입순. 평균적으로 존재하는 레코드를 찾을 때는 절반을 읽으면 될 것.
-> 삭제하면 순차적으로 찾아서, 지움. 그 공간은 재사용 하지 않음 → 삭제된 게 흩어져 있으면 성능에 안좋겠지?
→ 삽입 연산에서 굉장히 유리. 그냥 빈자리가 있으면 채우자 하는 것.
->그냥 한 블록만 읽어서 빈자리에 넣고 기록하면 끝이니까 두번만 디스크에 접근하면 됨.


- 모든 레코드를 읽되 순서가 중요하지 않을 때 좋다~ ->그러나 이런 경우는 거의 없겠지?
- 특정 레코드를 검색하는 경우엔 비효율적이다~
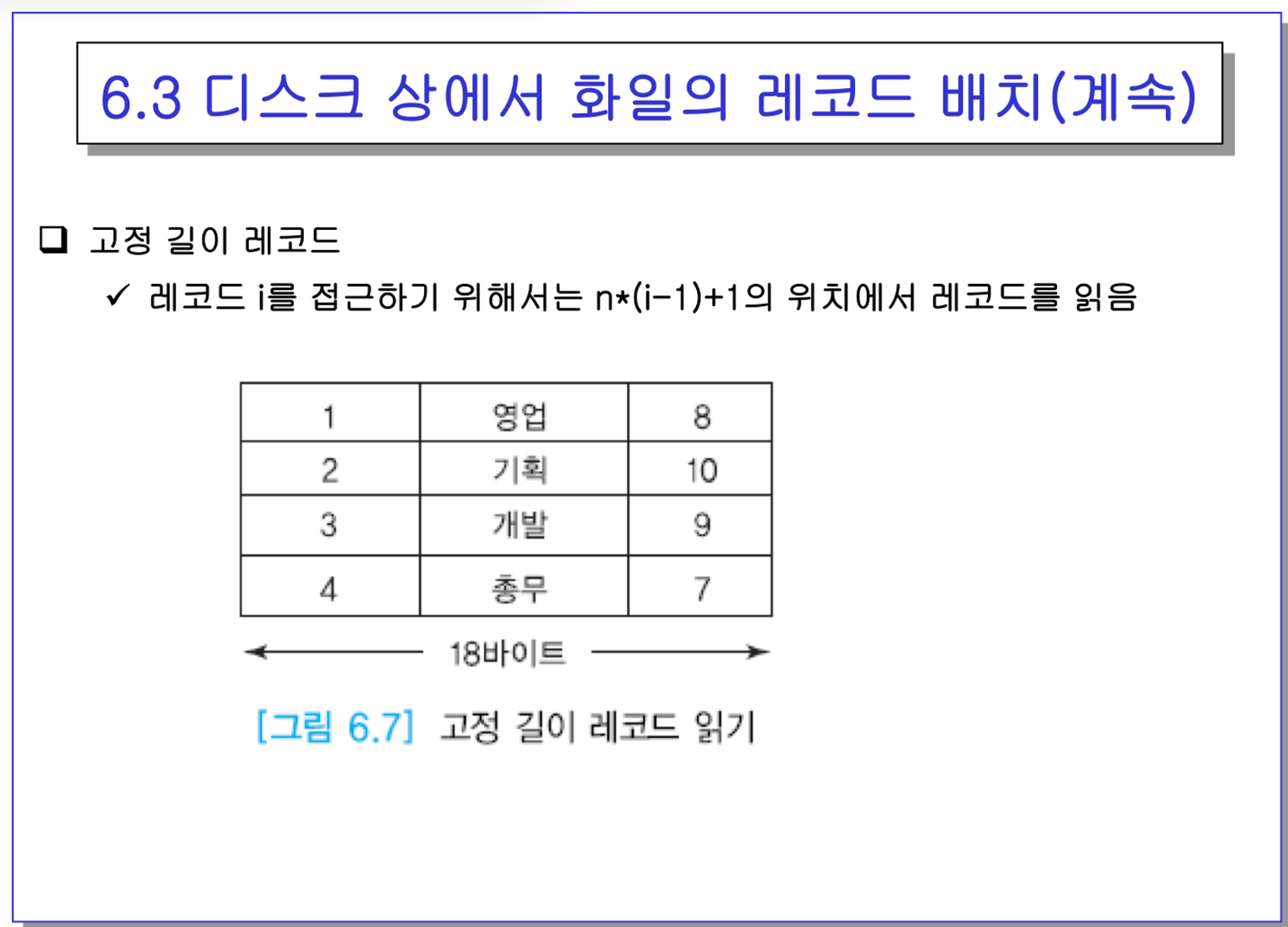
ex) 블록의 크기가 정해져 있으니까, 레코드가 20개 들어가겠지?
한 블록에 한 레코드가 온전히 들어가야한다고 하면 → 96바이트가 남음. → 레코드를 낑겨서 쪼개서 넣는 경우도 있다.
- 1000만 레코드를 넣으려면 블록 몇개가 필요하니? 50만개가 필요함. 저 기호는 ceil 천장함수.
-> 특정 레코드를 찾으려면 50만/2 = 25만개 블록 읽어야함. → 시크타임+로테이션딜레이+트랜스퍼타임 합치면 10ms → ㅈㄴ오래걸림


- 히프 화일은 클러스터링 되어 있지 않다! 모든 블록을 다 봐야함.


- 순차 화일은 레코드들이 컬럼 값에 따라서 순서대로 오름차순 내림차순 해서 저장됨.
-> 기본 인덱스가 순차 화일에 정의되지 않는 한 거의 사용되지 않음.
(다른책에서는 또 뭐 순서까진 요구하지 않음. 히프파일처럼 차례대로 쌓여있다고 정의하기도 함.)
- 탐색 키 : 고유 식별 능력은 없음. 그냥 정렬하는데 사용되는 필드. 기본키같은 능력은 있든 없든 무방
- 삽입 → 순서를 고려해야해서 오래 걸림.
- 삭제 연산 → 정렬되어 있어서 이진 탐색이 가능해지니까 조금 나을 것
→ 삭제하고 빈 공간으로 남기니까 주기적으로 재조직 해줘야함.


- 1365찾으려면, 이진탐색을 하기에 순차탐색보다는 블록 접근 수가 줄어듦.
BUT 이름이나 샐러리 하고는 상관없으니까, 탐색 키(EMPNO) 말고 다른 걸 사용하는 질의가 들어오면 히프화일이랑 똑같음. 파일 전체를 탐색해야 함.

n(레코드 수)천만
R(레코드길이) 200
B(블록 크기) 4K
Bf(블록킹 인수) 20
b(총 블록수) = 50만
HEAP는 25만개의 블록을 읽어야 하는데, 순차 화일은 19개만 읽으면 됨. 탐색 속도가 엄청나게 향상이 된 것임.


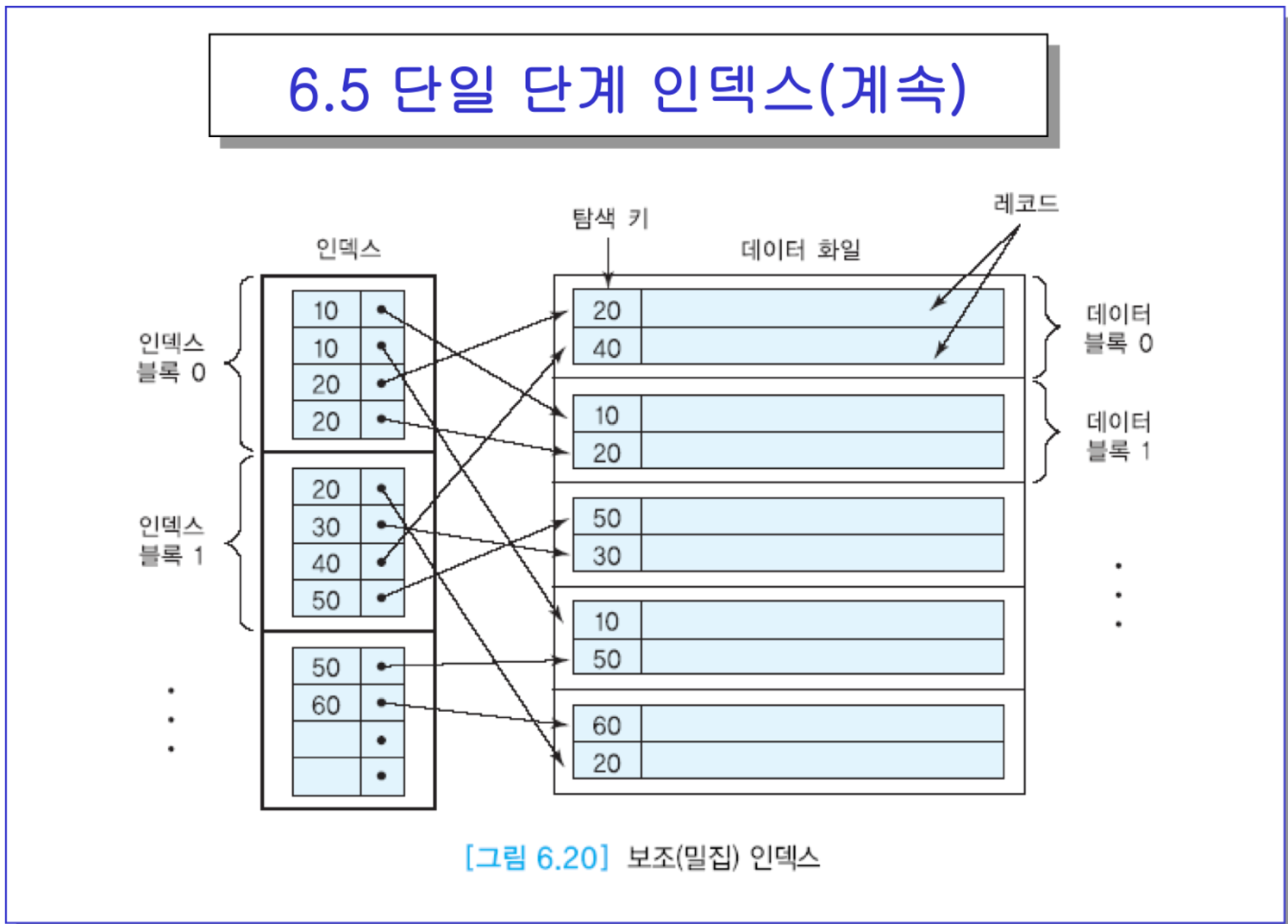
- 인덱스는 별도의 화일!
- 인덱스의 엔트리는 키와 RID. 딱 두개임. RID는 대게(먹고싶다) 4 or 6바이트. 키는 키 따라 다를 것.
ex) 계좌번호는 길면 15바이트. 카드번호는 16바이트.
- 한 블록당 그냥 있는대로 레코드 3개씩 들어가있다고 하자. EMPLOYEE가 데이터 화일임.
-> 인덱스에는 사원번호(키) 오름차순으로 정렬되어있음. + 포인터가 RID → 총 8바이트 밖에 안됨.


- 탐색키 : 키지만, 고유 식별 능력은 없음. 보통은 주소같이 긴 필드는 사용 X
- 기본키로 선정한 컬럼은 자동으로 인덱스를 만들어준다! -> 그래서 탐색키가 기본키면 그 인덱스를 기본 인덱스라고 부름. 기본인덱스는 한개만 가질 수 있음.
- 유니크는 대체 키를 지정한 것이기에, 유니크도 인덱스를 만들어줌
→ 사용자가 만들지 않아도 인덱스가 벌써 두개나 만들어 진 것
희소인덱스 ↔ 밀집인덱스


- 탐색키가 기본키
- 정렬되어있으면 대표값만 뽑아도 됨. 각 블록에서 제일 작은값 등… → 이런식으로 하는게 희소 인덱스!
→ 기본키에 만들어지는 인덱스가 희소 인덱스로 유지가 됨.
- 밀집 인덱스는 데이터 레코드 마다 반드시 탐색키 값이 인덱스에 반영이 되는 것(?)
-> 즉 모든 레코드의 탐색키값을 인덱스에 갖고 있는 것!
n 천만 b 50만 B 4096 b_f 20
- 각 블록마다 인덱스 엔트리가 하나가 있다 = 희소 인덱스
(키 20바이트 이상되는 놈 = 별로)
- 인덱스블록에 엔트리가 몇개가 들어갈까~ 한 인덱스블록에 엔트리 170개가 들어감
- 엔트리 수는 50만개지, 따라서 천장함수로 계산하면 2942개의 블록이 필요하다.
- 이걸 순차탐색하면, 1471번 비교해야함. 여기에 10ms곱하면, 14초 : 용서불가!!!
- 이진 탐색하면, 12번에다가 +1번 : 발견하고나면 그놈이 가리키는 데이터블록을 가져와야하니까, 그 접근 횟수임.
13번 접근하니까, 130ms이 걸림. 드라마틱하게 줄진 않음.

- 클러스터링 인덱스 : 이진 탐색 시간을 줄이자!(앞장의 로그2)
-> 일반적으로는 기본키에대해 정렬함. 기본키의 인덱스가 클러스터링인덱스.
- 범위의 시작 값에 해당하는 인덱스 엔트리(박영권) 먼저 찾고, 범위에 속하는 엔트리를 쭉 따라감
→ 디스크에서 읽어오는 블록수가 최소화됨.
→ 특정 데이터블록을 여러번 읽을 일이 없다!

- 인덱스 세트 : B-tree : 루트 to 리프가 동일
- 순차세트까지 모은 것 : B+tree : 루트 to 리프가 동일 x -> 한쪽에 몰릴 수 있음(비균형)
- 인덱스 세트가 엔트리로 가득찬 인덱스 블록이 쭉 있는데, 루트에서부터 내려오게 됨.
- 중간이 인덱스 블록, 하단이 데이터 블록임.
사원의 이름에 대해서 둘 다 정렬되어있음 → 이성래 어딨니? 위에서부터 쭉 내려와서 블록을 주기억장치로 읽어와서 4번으로 가서 이성래를 가져옴.

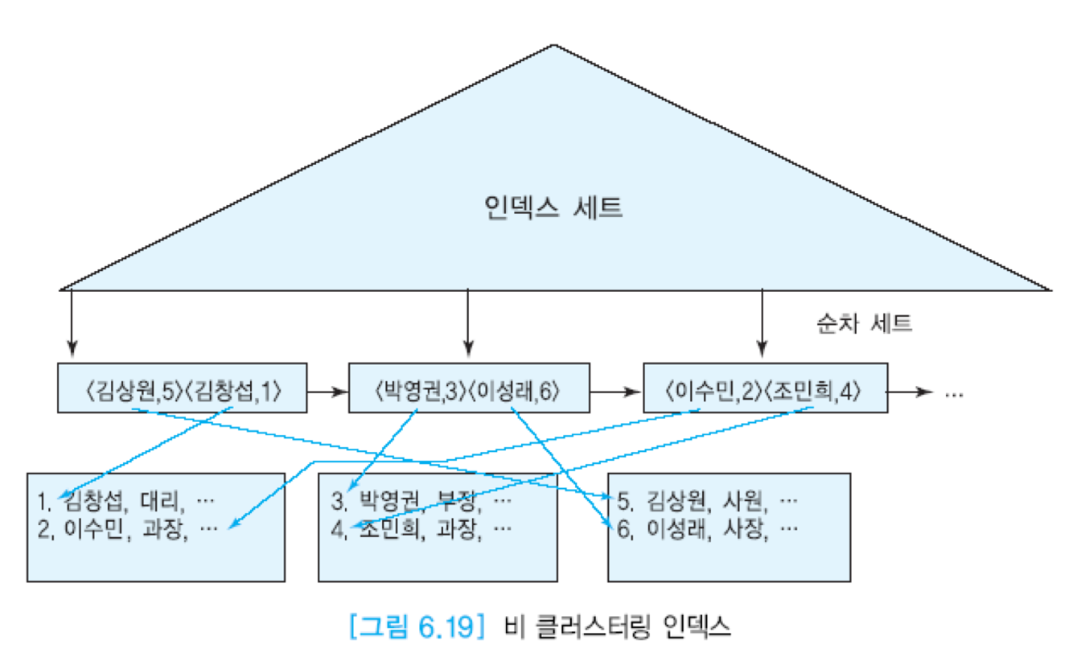
- 비 클러스터링 인덱스 : 데이터 레코드가 랜덤하게 저장되어있음.
- 비클러스터링이나 클러스터링이나 디스크 접근 횟수는 앞과 똑같음. → 찾는덴 똑같다. 그럼 뭐가 다르냐 ? 박응봉?
if where절에서 empname이 ≥박영권 and ≤이수민 을 준다면
여기서는 박영권이를 발견하고, 그 블록을 가져와서 박영권을 끄집어낸다음, 이성래는 또 다른 블록으로 가서 끄집어내고, 이수민이껀 또 다른블록에서 끄집어내야함.
→ 이후에 공간이 모자라면 있는걸 내보내고 가져와야 하는데, 아주 재수가 없는 경우엔
조민희껄 가져오라하면 이미 박영권이껄 내보냈으니까, 방금 내쫓은 블럭을 또 다시 불러와야함.
→ 최대로 나쁜 케이스엔 한 블럭에 있는 레코드 개수만큼 읽어야 할 수 있음.
그러나 클러스터링 인덱스는 하나만 만들 수 있고, 나머지는 비클러스터링 될 수 밖에 없다.

- 키가 아닌 탐색 키 필드 : 중복 가능할 것이다!
- 클러스터링 인덱스 : 기본 인덱스에 비해 겨우 하나 늘어남.

- 인덱스를 여러개 만들 수도 있음. 하나가 기본인덱스면, 나머지가 보조 인덱스.
- 보조 인덱스는 정렬되지 않는 데이터화일 정의 → 밀집인덱스가 될 수 밖에 없음. 즉 대표값을 뽑아올 수 없음.
→ 엔트리 수가 많아짐. 엔트리 수는 레코드 수 만큼 됨. 반드시 기말시험에 낸다! 33p(?)
인덱스의 블록 개수가 몇 개 필요한지, 엔트리가 몇 개 필요한지 이런걸 잘 계산할 수 있어야함.
엔트리가 늘어나서 디스크 접근횟수가 하나 정도 늘어날 수 있음.
- 대표값을 빼내는게 의미가 없음.. 탐색키는 고유하지 않으니까 중복값이 나올 수 있다.


- 정렬되어 있으니 대표값만 뽑을 수 있겠지만, 모든 레코드에 대해 엔트리로 들어가면 밀집 인덱스라고 할 수 있음.
예) 엔트리가 좀 더 많아질 수 있음. 레코드가 천만, 블록이 50만개.
밀집인덱스라면 총 엔트리 개수가 천만개 → 58824블록 -> 이진탐색하면 17번 → 이진탐색하는 것을 줄여야함.


- 단계수 1만큼 차이난다. 나머지는 이미지 참조



- 다단계 인덱스 : 단일 단계 인덱스를 다시 디스크 상의 순서 화일로 간주하고, 그 위에 인덱스를 정의하는 것.
- 언제까지? 가장 윗단계의 엔트리들이 한 블록에 담길 때 까지
- 마스터 인덱스 상주? : 자주 사용되니까 희생자가 될 확률이 낮으니까.
- 1단계 인덱스는 지금 희소 인덱스인데, 밀집이어도 상관없는데, 2단계 부터는 무조건 희소 인덱스가 구성될 것.
- 40을 찾는다면, 마스터 인덱스부터 순서대로 주기억장치의 버퍼에 가져옴.
- 실제로는 이렇게 꽉 채워서 인덱스블록을 만들진 않음. → 평균 채우기 비율은 50-100 사이를 왔다갔다함. 실제로는 2942블록보다 더 많은 블록이 필요할 것.

- LRU를 쓴다고 했을 때, 마스터 블록은 자주 참조될 것. 2~3단계는 뭐 1/150, 1/2942 뭐 이런 확률이니까.
-> 따라서 마스터블록은 주기억장치에 늘 있을 확률이 높음 → 디스크 접근을 3번만 하면 되겠지?
- 인덱스에서 블록이 순서대로 다음 블록을 가리킴. 순차 세트 역할을 하는 것.
- 밀집이냐 희소냐에 따라 하나정도 차이
ex) 대표값 하나만 뽑기 때문에, 데이터 블록에 레코드가 100개가 있다 : 데이터 길이가 40바이트.
-> 희소일때는 엔트리가 하나, 밀집일때는 엔트리가 100개.
-> 100배나 되는데? : 2단계 인덱스를 구축할 땐 보통 100개중에 하나만 반영되니까, 크게 줄어듦.
- 1단계에서 밀집이나 희소의 엔트리 개수는 1:10, 1:100하더라도 가다보면 단계 수가 많아야 하나 정도 차이가 난다.
- 50만개 적용해보면 1단계 인덱스가 2942개가 있는데, 대표값을 뽑아내면 2단계 인덱스가 몇 블럭 필요하냐? 18개. 엄청나게 줄어듦. 3단계는 1.
- 시스템카탈로그(8장) : 어떤 컬럼의 인덱스가 있는지 관리

- 자동으로 인덱스를 만들지 않는 필드에 대해 인덱스를 만드려면 이 구문을 사용해야함.


중요한 사항!
- ON EMPLOYEE (A,B,C) → 인덱스는 어디에 동작하느냐, where절에서 A만 사용해도 인덱스를 쓸 수 있음. 그러나 B,C만 주면 못 씀.
ON EMPLOYEE (A,B,C) 에서, A+B 모두에 대해 질의 → 가능
A에 대해 질의 → 가능
B에 대해 질의 → 불가 왜? 샐러리에 대해서는 아무 순서가 없는 것.

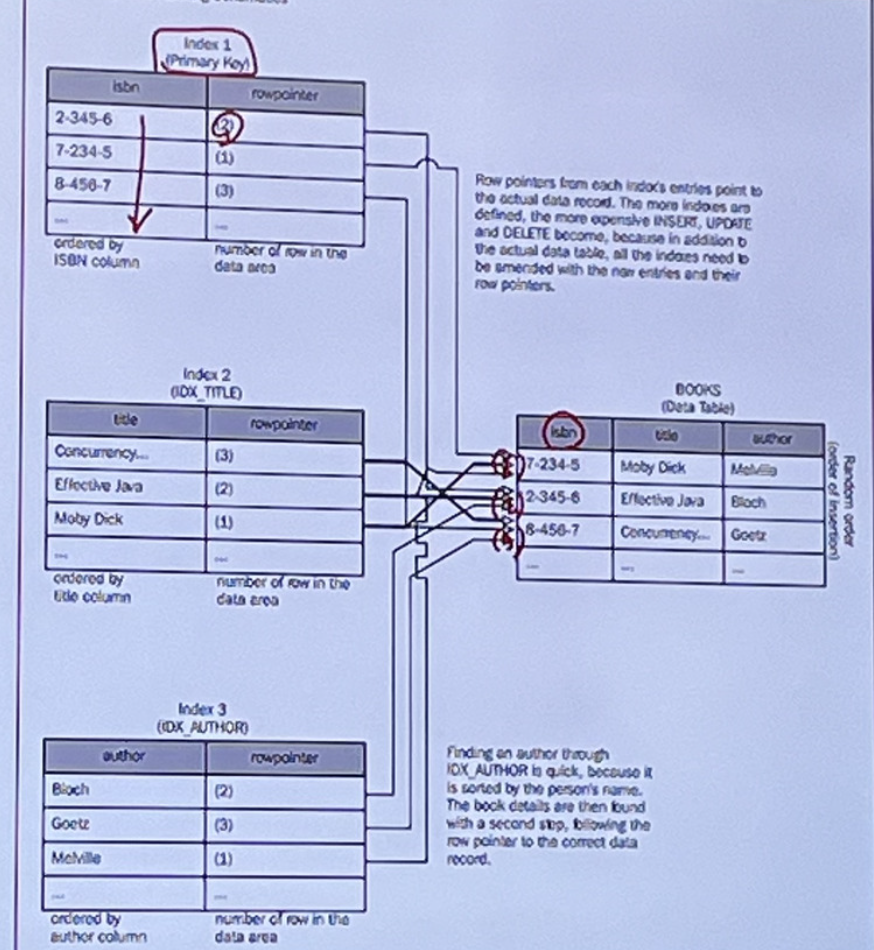
- 인덱스는 속도는 빠르지만, 저장공간이 좀 더 든다. 이미지의 2~4퍼는 의미 없음.
인덱스를 여러개 만들면 이렇게 장점이 있지만, 단점도 있음.
- 우측 이미지를 예시로, 새 책을 넣으려면 데이터파일에만 넣고 끝나는게 아니라, 인덱스를 다 고쳐줘야함. 책을 지우겠다! 그럼 다 지워줘야함. 그래서 통상적으로 5개 이하 또는 미만을 유지하라고 함.


- 조건들의 선별력 : 성별 남 녀를 지정하면 50%밖에 못줄임. 학번을 사용해서 지정하면 1/8000로 줄음. → 선별력이 클수록 잘 골라낸다.
- 이 고려사항들을 따르면 대부분 기본키가 아닌 다른 컬럼을 지정하는게 어려울 것!


추가 팁
지침 2 : 외래키에 인덱스를 꼭 만들어야함! 다른 릴레이션의 기본키하고 자주 조인에 사용되니까. 외래키에는 인덱스를 DBMS가 안만들어주니까 꼭 만들어서 유지를 하자.
지침 3 : 상이한 값들의 개수가 많다 : 값을 지정했을 때 그 값을 갖는 레코드가 전체 레코드 중에 하나일 가능성이 크다
지침 4 : 숫자는 ㄴㄴ. 학과면 1/40이니까 2.5%정도.
지침 5 6 : 갱신이 빈번하다 : 레코드가 계속 삽입, 삭제되는 케이스. 인덱스가 수정되는 빈도가 잦다
지침 8 : 3과 중복(?)
지침 9 : 실수형 만들면 안된다 : 다르게 표현되는 예가 많음
지침 10 : 가변길이 인덱스 ㄴㄴ
지침 11 : 굳이? 주기억장치 가져와서 순차탐색해도 크게 상관없음
지침 12 : 인덱스 새로 만드는게 나을 수 있다.
지침 13 : 오더바이 그룹바이절에 사용되는 컬럼에 인덱스 만드는걸 고려해봐라!


- 인덱스가 있다고 해서 DBMS가 무조건 그 인덱스를 써야하는 의무가 있진 않음 (8장)
-> 실렉트문이 들어오면 조인도 하고 조건들을 적용할텐데, 이 질의를 수행하는 좋은 방법을 찾아내야하는데. 질츼 최적화기가 이걸 담당하는데, 의존할 수 있는게 오직 시스템카탈로그밖에 없음.
- 어느 컬럼이 있는지 없는지, 레코드수가 어떤지, 뭐 이런걸 DBMS가 앎. 그런데 레코드수가 적으면 굳이 인덱스를 써도 성능이 나을 것 같지 않다 하면 무시하고 그냥 순차탐색. 혹은 수식을 적용하게 되면 인덱스를 못 씀
→ SUBSTRING(EMPNAME, 1, 1(2)) : 성을 잘라내라 이런걸 하면 인덱스가 있다 하더라도 못씀
이런 내장함수들을 제공하는데, EMPNAME에 인덱스가 있어도 내장함수 적용하면 인덱스를 못 씀
-> 널값엔 인덱스가 쓰이지 않는다.
매니저가 없는 사람이 누구냐. 매니저가 외래키니까 인덱스를 만들었다 하더라도, IS NULL로 비교하면 인덱스를 못씀.

- 디스팅트 : 정렬 해야함 수행시간 오래 걸림 → 필요할때만 써라
- 그룹바이 해빙 : 이것도 필요할 때만 써라
- 임시 릴레이션 생성을 피해라 : 실렉트 결과를 임시 테이블에 담아두고 쓰는데, 안 만들 수 있으면 그렇게 해라
- 실렉트 * 대신에 원하는걸 구체적으로 열거하자
'UOS@DB' 카테고리의 다른 글
| 8장 뷰와 시스템 카탈로그 (0) | 2023.12.16 |
|---|---|
| 7장 릴레이션 정규화 (0) | 2023.12.15 |
| 5장 데이터베이스 설계와 ER모델(설계 사례 분석 및 릴레이션으로의 사상) (4) | 2023.12.03 |
| 5장 데이터베이스 설계와 ER모델(DB설계 개요, ER모델) (0) | 2023.11.27 |
| 4장 관계대수와 SQL(트리거, 내포된 SQL) (1) | 2023.11.05 |