

- 관계 해석 : 데이터만 명시, 질의 수행 방법은 명시 X : 선언적 언어
- 관계 대수 : 질의 수행 방법도 명시 : 절차적 언어
-> DBMS에서 널리 사용되는 SQL의 이론적 기초, SQL의 구현과 최적화를 위해 DBMS의 내부언어로도 사용.

- 쿼리트리 : 브랜치에서 무언가를 골라내고 조인, 최상위에서는 customer name만 뽑아냄.
-> 연산자들의 수행 순서가 정해져 있다!
-> 내부적으로 SQL을 이런식으로 표현함.
ex) 어카운트 테이블에서 잔액이 1000이상인 것을 골라낸다 : 브랜치의 개수를 줄이는 것 -> 이후 조인하면 실행시간이 빨라짐.

- 관계 대수의 특징
1. 기존의 릴레이션들로부터 새로운 릴레이션 생성 -> 관계대수 적용시 새 릴레이션이 만들어짐
2. 릴레이션or관계대수식에 연산자를 적용하여 복잡한 관계대수식을 점차적으로 만들 수 있다 : 절차적
3. 기본적인 연산자들의 집합
4. 하나의 릴레이션 or 두 개의 릴레이션을 입력으로 받아 하나의 결과 릴레이션 -> 이건 또 입력으로 사용가능


- 필수연산자 5개로 모든 연산 가능
- 세미조인(분산), 디비전을 제외하고는 모두 이항연산자 -> 실무에서 쓸모없음
- 실렉션 : 조건에 맞는 레코드를 통째로 골라냄 ex) 우리은행 계좌 중 전농동지점 계좌만
- 프로젝션 : 일부 컬럼을 골라낸다
- 합집합 : 공통된게 있어도 결과에 한 번만 나타나야함
- 교집합 : 릴레이션의 공통부분
- 차집합 : 겹치는 부분 제외
- 카티션 곱 : 굉장히 덩치가 크다. 주기억장치에 유지 못하는 경우 왕왕있음 -> 사용자가 원하는건 이 중에 극히 일부 -> 만들면 안됨
- 디비전 : 통상적으로 컬럼 1개. 하나 갖고 나눔. 하늘색과 하늘색 부분이 대응되어 작은거 하나가 나옴.
<필수 연산자>


- 실렉션 조건을 만족하는 투플들의 부분집합 = 새 릴레이션
- 실렉션시 모든 컬럼을 그대로 유지 = 차수가 그대로다
- 릴레이션에 속하는 임의의 컬럼과 수 및 문자열 상수와 비교연산, 부울 연산 가능
우측 이미지에서, 실렉션을 명령하는데 데이터가 많다면 4KB짜리 수백만개 블럭을 읽어야함
-> DNO같은데에 인덱스를 만들어서 해결.


- 프로젝션 : 한 릴레이션의 투플(애트리뷰트)들의 부분집합을 구함
-> 오리지널 릴레이션엔 중복 투플이 없지만, 일부 컬럼만 골라내면 중복 문제가 발생 가능
-> 지워서 중복 제거해야함


- 관계 대수에서의 집합은 수학에서의 합집합과 다르다.
- 합집합 호환의 필요충분조건 : 1. 컬럼 수가 같아야함 2. 도메인이 같아야함
-> 우측 이미지에서, 합집합 호환이 안되므로 DNO,DEPTNO를 각각 프로젝션 하면 합집합 가능.


- 합집합 연산자 : 합집합은 R or S or 모두에 속한 투플로 이루어진 릴레이션, 중복 제외
- 결과 : 차수는 R or S의 차수와 같고, 애트리뷰트의 이름들은 R or S의 애트리뷰트들의 이름과 같음.
- 해석 : 김창섭이 2번 -> 임플로이를 봐야하고, 디파트먼트도 봐야함. 실렉션하고 프로젝션 한다.
-> 리절트 1,2의 도메인이 같으니까 합집합 적용! -> 리절트 3!


- 교집합 연산자 : 교집합은 R과 S 모두에 속한 투플들로 이루어진 릴레이션
- 결과 : 차수는 R or S의 차수와 같고, 애트리뷰트들의 이름들은 R or S의 애트리뷰트들의 이름과 같음
여기서, or에서 empname을 생략하면 안됨. 김창섭 최종철 둘 다 EMPNAME='어쩌구' 해줘야함.
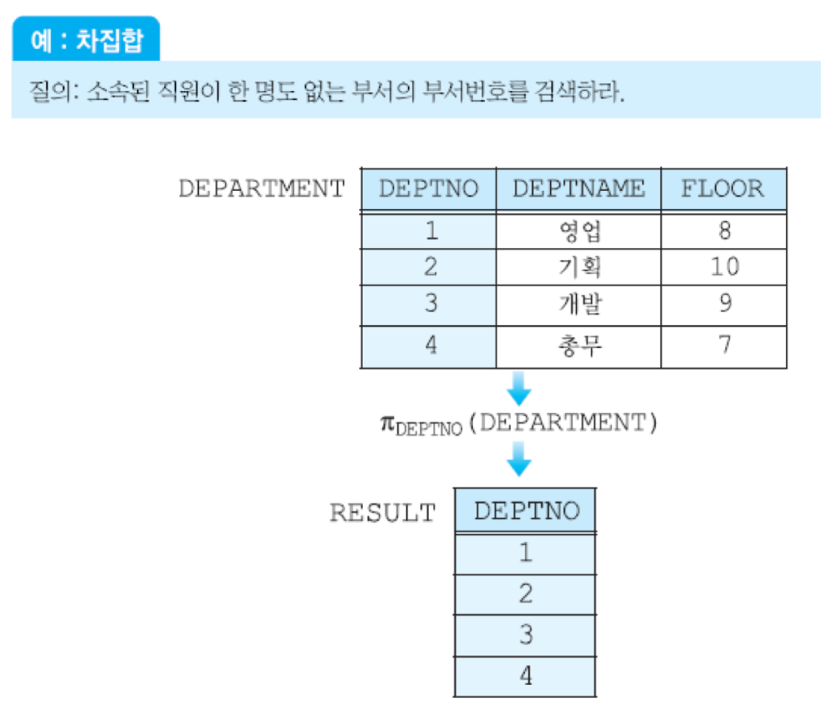

- 차집합 연산자 : 차집합은 R에는 속하지만 S에는 속하지 않은 투플들로 이루어진 릴레이션
- 결과 : 차수는 R or S의 차수와 같고, 애트리뷰트들의 이름은 R or S의 애트리뷰트들의 이름과 같음.
-> 임플로이 테이블에는 4번 부스 근무자가 없음. 따라서 뺴면 4만 남음.

- 카디날리티 : 한 테이블에 들어있는 레코드의 수
- X : 카디션 곱의 기호. *은 JOIN의 기호임.
- 카디션 곱 연산자 : R과 S의 차수의 합(=두 릴레이션의 컬럼(=애트리뷰트)을 모두 갖는다), R과 S의 투플들의 모든 가능한 조합으로 이루어진 릴레이션
-> 크기가 ㅈㄴ 클 수 있고, 사용자는 결과의 일부만 필요하므로 딱히 유용하지 않음
- 관계 대수의 필수 연산자 : 지금까지의 실렉션, 프로젝션, 합집합, 차집합, 카티션 곱
-> 이들을 지원하면 그 언어는 관계적으로 완전하다.
<추가 연산자>
- 조인 연산자 : 두 릴레이션으로부터 연관된 투플을 결합
ex) 세타, 동등, 자연, 외부, 세미 조인 등


- 세타조인 : 카티션 곱과 동일하게 흘러가는데, 조건에 맞는 것들을 골라냄.
세타는 = <, >, <=, >=, =, <> 중에 하나 이 때 비교 연산자가 =인 조인을 동등조인이라고 함.
- 동등조인 : 나비넥타이 조인기호에 비교 연산자가 =로 연결되어있음.
ex) 김창섭 2번 -> DEPT 릴레이션의 모든 행을 훑으면서 비교 -> 비교 횟수가 많아서 시간이 많이 걸림
-> 기본키와 외래키 관계이기에 매치된걸 찾으면 더 없는상황인데, 얘는 멍청해서 다 훑음
-> 인덱스로 해결 가능(6장)


- 자연 조인 : 동등 조인에서 조인 컬럼 하나만 결과에 보이는 것이 자연조인(가장 많이 사용)
ex) 별표 기호 자체가 동등조인을 함축, 둘 사이 관계를 쉼표로 작성
이 때 부서가 안정해져서 DNO에 null이 있을 수도 있지, 부서번호 4는 나타나지 못했지
-> 이걸 나타내면서 빈자리에 null로 채우면 외부조인


- 디비전 연산자 : R / S 하는데, R의 차수(m+n)에서 S가 가진것(m)들을 모두 뺀 차수(n)를 가짐.
A#B# / B#(C)으로 이루어졌다.
ex) b1하나만 있지. → 결과로 b1으로 나누어지는놈 a1, a4가 나간다. : T,U가 있으면 결과에는 이 T부분만 나간다.
ex2) 나누는놈이 b2(u1),b4(u2)가 있다면 u1u2에 대해서 a1(t1)이 있고, u1u2에 대해서 a2(t2)가 있지
→ 따라서 t1,t2가 뽀로록~ 하고 결과로 나감.
point : a4는 b2하곤 대응되는데 b4하고 대응되지 않아서 탈락임.
-> 둘 다 중복되는 녀석(T)만 결과로 나가게 됨.
→ 이 연산은 내년 즈음 졸업요건을 만족했는가 점검하는 과정을 거칠 때.
B123이 전공필수라면. a4학생은 다 들었네? 하는 느낌.

첫 번째 질의 : 실렉션을 먼저 한 후 이름과 급여를 프로젝션 함.
두 번째 질의 : 개발부서는 디파트먼트에, 사원 넘버는 임플로이에 흩어져있음 -> 조인이 필수적!
부서이름이 개발인 것을 실렉션 하고, 임플로이 테이블에서 이름을 마지막에 프로젝션 하니까
-> 개발부서에 근무하는 사원의 이름을 짝지어줘야함
여기서 포인트는 순서에 따라서 속도가 달라질 수 있음. 실렉션이 아닌 조인을 먼저 한다면, 모든 부서를 다 체크해야함. -> 조인 전에 실렉션으로 디파트먼트의 레코드 수를 줄이면 수행시간이 적게 걸리게 됨.

관계 대수의 한계 : 산술 연산, count max 등 집단 함수, 정렬, DB수정, 중복 허용도 못함
-> 추후 몇가지 관계 대수 연산자가 추가되었음.


- AVG_컬럼(릴레이션) : 평균
- G : 그룹화 : DNO G : 릴레이션의 샐러리 컬럼의 평균을 DNO별로 그룹화 하겠다!


- 외부조인 : JOIN 컬럼에 null값이 들어있거나, 대응되는 투플이 없는 것들을 다루기 위한 것!
- 왼쪽 외부 조인 : R의 모든 투플을 포함시키고, S에 대응되는게 없는 애트리뷰트들은 null로 채움
- 오른쪽 외부 조인 : S의 모든 투플을 포함시키고, R에 관련된 투플이 없는 R의 애트리뷰트들은 널값으로 채움


- 왼쪽 외부 조인 : R의 모든 튜플을 포함, S에 관련된 투플이 없는 S의 애트리뷰트들은 널로 채움.
- 완전 외부 조인 : 둘 다 합친 것. 상대 릴레이션에 관련된 투플이 없으면 결과 릴레이션에서 상대 릴레이션의 애트리뷰트들은 널값을 채움
'UOS@DB' 카테고리의 다른 글
| 4장 관계대수와 SQL(SELECT 및 삽입 삭제 수정문) (0) | 2023.11.05 |
|---|---|
| 4장 관계대수와 SQL ( SQL 개요, 데이터 정의어, SELECT문1/2) (0) | 2023.11.04 |
| 3장 오라클 (1) | 2023.11.03 |
| 2장 관계 데이터 모델과 제약조건 (1) | 2023.10.16 |
| 1장 DB 시스템(2/2) (0) | 2023.10.10 |