

<관계 데이터 모델 시작>
관계 데이터 모델 : E.F.Codd가 1970년 제안 -> 지금까지 제안된 데이터 모델 중 가장 개념이 단순한 모델의 하나
-> 최초의 프로토타입 : System R(relation), 상용제품 : 오라클
- 관계 데이터 모델이 성공을 거둔 요인
1. 바탕이 되는 데이터 구조로서 간단한 테이블(릴레이션) 사용
2. 중첩된 복잡한 구조가 없음 -> 이를 지원하는 것이 객체지향 모델 : 어려움
3. 집합 위주 데이터 처리(Codd가 수학자) -> 성능 good
4. 이론 정립 well, 관계DB 설계와 질의 처리에서 뛰어남.
<관계 데이터 모델 개념>

릴레이션 : 2차원의 테이블
레코드 : 릴레이션의 각 행
튜플 : 레코드의 공식 용어, 행
애트리뷰트 : 릴레이션에서 하나의 이름을 가진 하나의 열 = 컬럼(sql의 표준어)
-> 릴레이션, 튜플, 애트리뷰트
- 관계 데이터 모델 : 동일한 구조(릴레이션)의 관점에서 모든 데이터를 논리적으로 구성
- 선언적인 질의어를 통한 데이터 접근 제공
-> 사용자가 "무엇을 얻고 싶은가? : What"에 중점을 두고, "어떻게 얻을 것인가? : How"에 대한 세부적인 절차를 명시하지 않는 것
- 응용 프로그램은 레코드들의 순서와 무관하게 작성됨
- 논리적으로 연관된 데이터를 연결하기 위해 링크나 포인터를 사용하지 않음

Degree(차수) : 애트리뷰트 들의 수 -> 5 : -> 최소한 하나의 애트리뷰트는 있어야함 -> 없으면 의미 없는 것.
Cardinality(기수) : 레코드(튜플)의 수 -> 4 : 레코드를 집어넣으면 값이 수시로 변화할 수 있음.
도메인 : 한 애트리뷰트에 나타날 수 있는 값들의 집합, 실질적으로 존재하는 것이 아니라 개념적으로 생각.
-> 이 도메인은 여러 애트리뷰트에서 사용될 수 있음.
-> 각각의 컬럼(애트리뷰트)에는 반드시 단일값만 나타낼 수 있음.-> 여러 집합인듯?
임플로이 네임에 들어갈 수 있는 한국사람은 누구나 후보가 될 수 있음.
도메인을 지원하는 dbms는 비슷한 신택스로 선언을 하고, 도메인 이름을 테이블 정의할 때 쓸 수 있음.
꼭 써야하는 것은 아니지만, 여러 테이블에서 같은 역할로 사용되는 컬럼이 있는데 어떤 컬럼에서는 정수형으로 어디서는 문자형으로 이런 케이스를 없앨 수 있음.
도메인은 테이블이 많은 기업에서 컬럼들을 일관성있게 관리할 때 유용하게 사용될 수 있다.
널 값 : 알려지지 않음, 적용할 수 없음, 혹은 모른다는 의미. 주의해서 접근해야함
ex) 신입사원 교육기간 -> DNO가 없거나 DNO를 모름! -> DBMS마다 이를 나타내기 위해 유니코드든 아스키코드는 각자 다른걸 씀

릴레이션 스키마 : 릴레이션의 이름과 애트리뷰트들의 집합 -> 내포(intentsion)라고 함.
스키마는 릴레이션을 위한 틀(framework)임 -> 상세 내용을 숨기며 전체 구조를 명확히 나타내는데 유용.
ex) 릴레이션이름(애트리뷰트1,애트리뷰트2,...,애트리뷰트n) -> 기본키 애트리뷰트에는 밑줄.
경우에따라 애트리뷰트 뒤에 데이터타입을 쓰기도 함.
릴레이션 인스턴스 : 상태, 릴레이션에 어느 시점에 들어있는 투플들의 집합 -> 외연(extension)이라고 함.
-> 계속 데이터를 집어넣으면 레코드가 늘어나지? 특정 시점에 레코드들의 집합을 의미. -> 시간의 흐름에 따라 변화함.

DNO : 중요한 놈! 레코드의 위치가 바뀌어도 값은 영향을 받지 않음
-> 그럼 어떻게 찾느냐? JOIN 메소드를 통해.
DNO가 없으면 김창섭이 어느 부서에 근무하는지 알 수 없음. EMPOLYEE의 DNO를 외래키라고 부름.
-> DEPARTMENT의 DEPTNO는 기본키겠지?
<릴레이션의 특성>
- 각 릴레이션은 오직 하나의 레코드 타입만 포함 -> 각 릴레이션에 오직 한 가지 유형의 정보만 저장됨을 보장
- 한 애트리뷰트 내 값들은 모두 같은 유형
- 애트리뷰트의 순서는 의미 없음 : 왜 ! 테이블이 튜플들의 집합이니까 !
-> 각 열을 하나의 집합으로 정의하면 아무짝에 쓸모가 없음. D={<1,영업,8>,<2,기획,10>...} 뭐 이런식으로 가야함.
테이블을 만들 때는 순서를 명시해야 하기 때문에 실제로 저장될때는 최초에 정의한 순서대로 값들이 들어감.
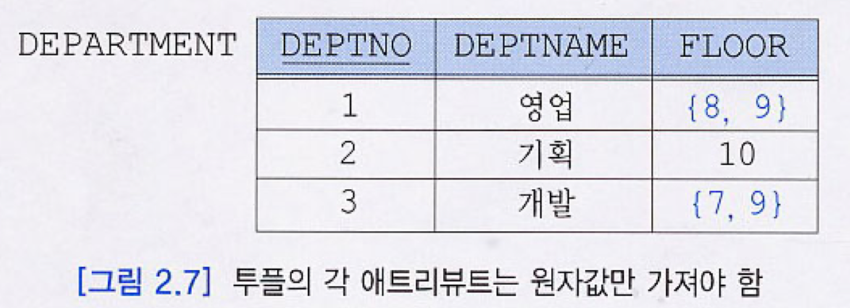
- 동일한 튜플이 두 개 이상 존재하지 않음 -> 오버헤드가 커져 상용 관계 DBMS에서는 일반적으로 시행 X
-> 반드시 키가 존재함. 임의의 튜플을 구분할 수 있는 컬럼이 반드시 존재.
- 한 투플의 각 애트리뷰트는 원자값을 가짐 : 집합을 허용하지 않는다.
<릴레이션의 키>
키 : 각 투플을 고유하게 식별할 수 있는 하나 이상의 애트리뷰트들의 모임
- 수퍼키 : 한 릴레이션 내의 특정 투플을 고유하게 식별하는 하나의 애트리뷰트 또는 그들의 집합.
-> 꼭 필요하지 않는 애트리뷰트(컬럼)을 포함할 수 있음. 너그러운 키
- 후보키 : 각 투플을 고유하게 식별하는 최소한의 애트리뷰트들의 모임 ex) 주민번호, 신용카드번호 등
-> 모든 릴레이션에는 최소 하나 이상의 후보키가 있음.
-> 어떤 시점에 중복된 값이 없다고 해서 미래에도 그러지 않는다고 단정할 수 없음.
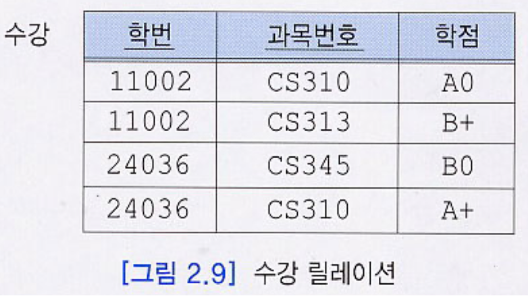
- 복합키 : 1:N, M:N의 관계를 해소하면서 만들어지는 테이블의 두 개 이상의 애트리뷰트가 모여서 키가 되는 경우
-> 한 학생이 여러과목을 수강한다면 학번이나 과목번호만으로는 각 투플을 고유하게 식별할 수 없기에, 두개가 모여 후보키가 됨.
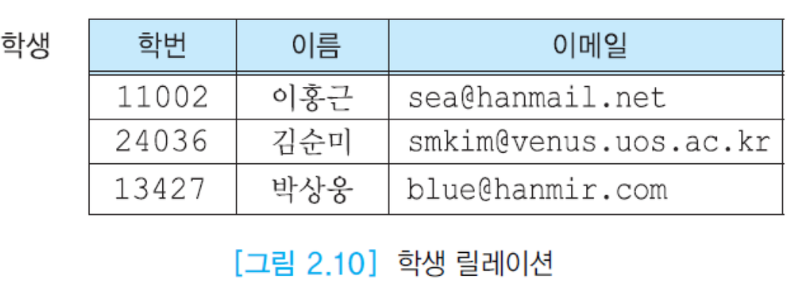
여러명의 레코드가 들어올 때, 이름이 달라야 한다는 것을 학교에서 요구할 수 없음.
-> 이름은 후보 키가 될 수 없다
이메일은 사람마다 다르다!
-> 후보키가 될 수 있으나, 바뀌는 경우가 존재하기에 안하기도 함.
- 기본키 : 한 릴레이션에 후보 키가 두 개 이상 있으면 설계자 또는 관리자가 하나를 기본키로 선정.
-> 모든 투플을 고유하게 식별 가능해야함. 널값, 중복 불가. 변경 가능성도 낮아야함. 가장 작은 정수나 짧은 문자열. 복합 피하기.
ex) 은행에서 계좌와 주민번호가 후보키가 될 수 있지만, 계좌를 자주쓰니까 계좌를 기본키로 설정.
-> 자연스러운 기본키를 찾을 수 없는 경우 인위적인 키 애트리뷰트를 릴레이션에 추가할 수 있음 ex) ISBN, 학번
- 대체키(보조키) : 기본키가 아닌 후보키 ex) 주민번호
- 외래키 : 어떤 릴레이션의 기본키를 참조하는 애트리뷰트 -> 릴레이션들 간의 관계를 나타내기 위함.
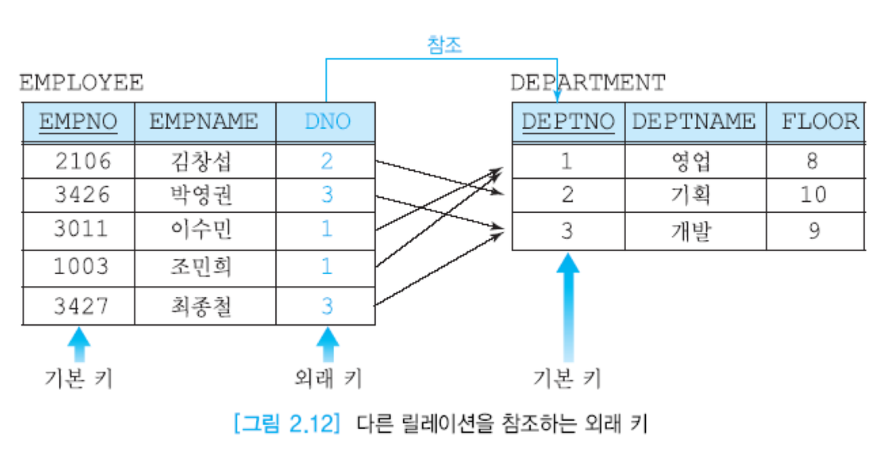
DNO대신 DEPTNO써도 상관 없고, 여러 테이블에서 사용될 수 있음.
부서 번호를 모른다면 널 값 사용, 4와 같이 기본키에 없는 값은 들어올 수 없음.
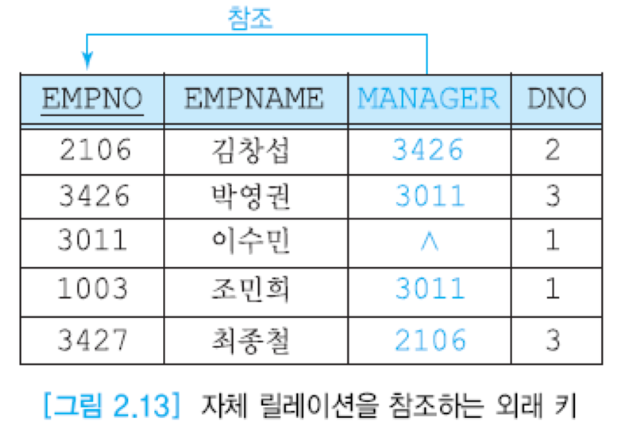
큰 부품 속에 중간, 중간 부품 속에 작은 부품이 들어가고 이러한 포함관계가 있을 때 자신의 기본키를 참조하는 외래키 존재 가능.
ex) 3426이 직속상사인데, 이의 이름 직급 급여 등을 굳이 다 쓸 필요가 없음 -> 3426으로 찾아가면 되는 것.
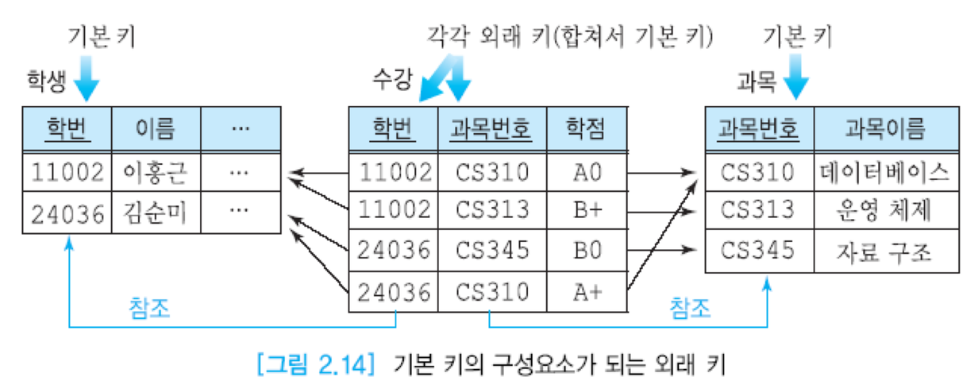
수강 릴레이션의 학번 애트리뷰트(외래키) -> 학생 릴레이션의 학번(기본키) 참조
수강 릴레이션의 과목 번호(외래키) -> 과목 릴레이션의 과목번호(기본키) 참조
-> 수강 릴레이션의 이 두 외래키는 수강 릴레이션의 기본키가 됨.

< 무결성 제약조건 >

데이터 무결성 : 데이터의 정확성 또는 유효성을 의미.
-> 무결성 제약조건의 목적은 일관된 DB상태를 정의하는 규칙들을 묵시적/명시적으로 정의하는 것.
-> 값들의 범위를 정해주고 싶은것. 급여 얼마 이상, 혹은 1~4학년과 같이.
데이터베이스 위에서 돌아가는 응용 프로그램들은 일관성/무결성 검사를 할 필요가 없음 : DBMS가 시행.
- 도메인 제약조건 : 가장 간단한 형태의 제약조건.
1. 각 애트리뷰트 값이 반드시 원자값이어야 함.
2. 애트리뷰트 값의 디폴트값, 가능한 값의 범위를 지정할 수 있음. ex) 사원이 제일 많으니 직급을 지정하지 않으면 사원으로 배정
3. 데이터 형식을 통해 값들의 유형을 제한하고, CHECK 제약 조건을 통해 값들의 범위를 제한 가능.
-> 어느정도의 데이터 무결성을 유지함.
- 키 제약조건 : 키 애트리뷰트에 중복된 값이 존재해서는 안된다.
- 기본키와 엔티티 무결성 제약조건 : 기본키를 구성하는 어떤 애트리뷰트도 널값을 가질 수 없다. 대체키는 가능.
-> 사용자는 어떤 애트리뷰트가 기본키의 구성요소인가를 DBMS에 알려줌.
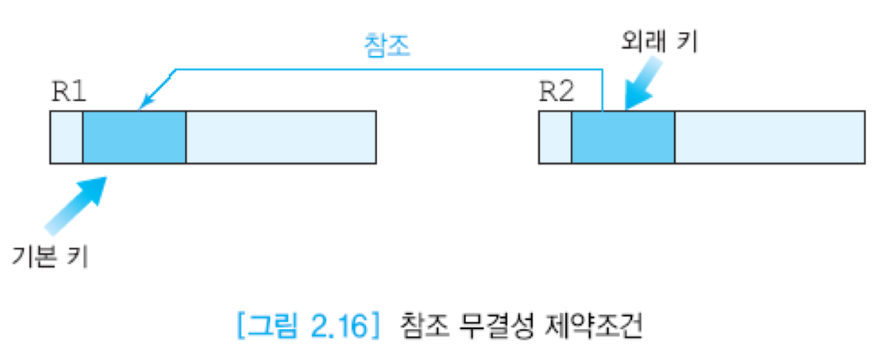
-외래키와 참조 무결성 제약조건 : 두 릴레이션의 연관된 투플들 사이의 일관성을 유지하는데 사용.
-> 외래키는 다른 테이블의 기본키를 참조하는데, 그 상황에서 참조 무결성 제약조건을 반드시 지켜야함.
-> 테이블(릴레이션) R2의 외래키가 R1의 기본키를 참조할 때, 아래 조건중 하나가 만족되면 됨.
1. 외래키의 값은 R1의 어떤 투플의 기본키 값과 같다(기본키에 없는 값을 가질 수 없다)
2. 외래키가 자신을 포함하고 있는(자신의) 릴레이션의 기본 키를 구성하고 있지 않으면 널값을 가진다(가질 수 있다).

- 무결성 제약조건의 유지 : DBMS는 인서트 딜리트 업데이트의 갱신 연산에 대해 데이터베이스가 무결성 제약조건들을 만족하도록 필요한 조치를 취함.
-> 외래 키가 갱신되거나, 참조되는 기본키가 갱신되었을 때 참조 무결성 제약조건이 위배되지 않도록 해야함.
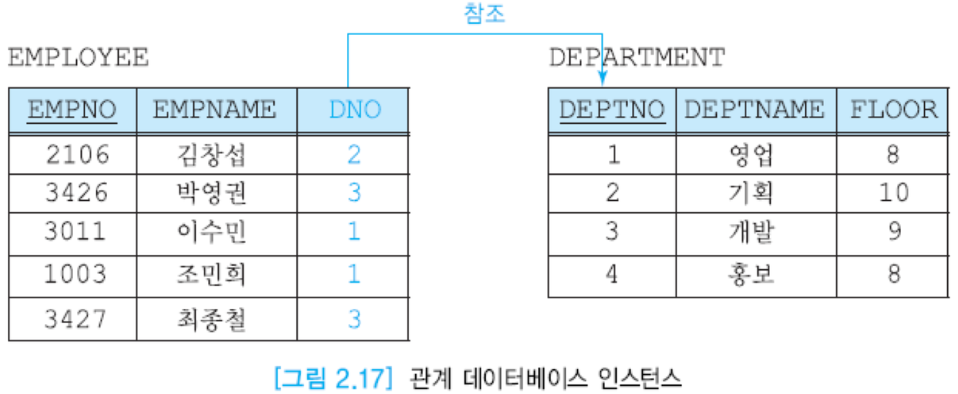
department : 참조된 릴레이션, employee : 참조하는 릴레이션.
INSERT(삽입)시
- 참조되는 릴레이션에 새로운 투플이 삽입되면 참조 무결성 제약조건은 위배되지 않음
BUT 도메인 제약조건, 키 제약조건, 엔티티 무결성 제약조건 등을 위배할 수 있음.
- 참조하는 릴레이션에 새로운 투플이 삽입되면 참조 무결성 제약조건도 위배될 수 있음.
ex) (4325,오해원,6) 이라는 투플을 삽입하면 위배되지?
DELETE(삭제)시
- 참조되는 릴레이션에서 투플이 삭제되면 참조 무결성 제약조건을 위배하는 경우가 생길 수도 있음.
- 참조하는 릴레이션에서 투플이 삭제되면 모든 제약조건을 위배하지 않음.
- 참조 무결성 제약조건을 지키기 위해 DBMS가 제공하는 옵션
1. 제한 : 위배를 야기한 연산을 거절

2. 연쇄 : 참조되는 릴레이션의 투플과 참조하는 릴레이션의 해당되는 모든 투플을 함께 삭제
3. 널값(nullify) : 참조되는 릴레이션에서 투플을 삭제, 참조하는 릴레이션의 외래키에 널값을 삽입
4. 디폴트값 : 널값 대신 디폴트값
UPDATE(수정)시
- DBMS는 해당 애트리뷰트가 기본키인지 외래키인지 검사 -> 둘 다 아니면 해당 없음
- 기본키나 외래키의 경우 삽입 및 삭제와 유사
- 오라클에서는 수정 연산에 대해 제한적으로 참조 무결성 제약조건을 유지
'UOS > UOS@DB' 카테고리의 다른 글
| 4장 관계대수와 SQL ( SQL 개요, 데이터 정의어, SELECT문1/2) (0) | 2023.11.04 |
|---|---|
| 4장 관계대수와 SQL (4.1 관계대수) (0) | 2023.11.04 |
| 3장 오라클 (1) | 2023.11.03 |
| 1장 DB 시스템(2/2) (0) | 2023.10.10 |
| 1장 DB 시스템(1/2) (0) | 2023.10.09 |