

1.3 DBMS 발전 과정
<데이터 모델>
파일시스템 : 70이전
하이브리드 : 80중반까지
관계 모델 : 80후반까지
객체 모델 : 90중반까지
객체관계 모델 : 90후반까지.
- 데이터 모델 : 데이터베이스의 구조를 기술하는데 사용되는 개념들의 집합인 구조(테이터 타입과 관계), 이 구조 위에서 동작하는 연산자들, 무결성 제약조건들
- 고수준 또는 개념적 데이터 모델 : 사람이 인식하는것과 유사하게 DB의 전체적인 논리적 구조를 명시
ex) 앤티티관계(ER모델*) 데이터 모델과 객체지향 데이터 모델 - 표현(구현)데이터 모델 : 최종 사용자가 이해하는 개념이면서 컴퓨터 내에서 데이터가 조직되는 방식과 멀리 떨어져 있진 않음
ex) 계층/네트워크/관계* 데이터 모델 - 저수준 또는 물리적 데이터 모델 : 데이터가 어떻게 저장되는가를 기술
ex) 유니파잉, ISAM, VSAM 등
<DBMS의 발전과정>

- 계층 DBMS : 60년대 후반 최초의 계층 DBMS 등장(IMS 등). 트리 구조 기반. 이는 네트워크 DBMS의 특별한 case

- 어떤 유형의 응용에 대해서는 (데이터가 트리 형태로 모델링 될 수 있을 때) 빠른 속도와 높은 효율성 제공
- 어떻데 접근하는가를 응용 프로그램에 미리 정의해야함, DB가 생성될 때 각각의 관계를 명시적으로 정의해야 함
- 레코드들이 링크로 연결되어 있어 레코드 구조를 변경하기 어려움. 응용 프로그램을 수정하기도 어려움
-> 데이터 독립성이 제한됨
단점 : 사원2가 프로젝트 1(부모)를 가리키는 포인터가 있음. get next하여 한번에 하나씩 찾게 되는데, 자식에서 부모를 올라가서 검색하는게 불가능함. 그런데 사원을 거쳐서 프로젝트를 검색하는게 자주 있더라.
그럼 부모자식 관계를 바꾸고, 응용 프로그램 싹 고치고. 데이터 베이스를 오랜시간동안 못쓰게 됨.
→ 어떻게 데이터를 접근하는가를 정의해야함. 그리고 데이터베이스가 생성될 때 부모자식 관계를 명시해야함 : 매우 어렵다!
- 네트워크 DBMS : 60년대 초 Charles Bachman이 하니웰 사에서 IDS를 최초 개발.

- 레코드들이 노드로, 레코드들 사이의 관계가 간선으로 표현되는 그래프를 기반으로 하는 네트워크 데이터 모델 사용
- 레코드들이 링크로 연결되어 있어 레코드 구조를 변경하기 어려움. 응용 프로그램을 수정하기도 어려움
-> 데이터 독립성이 제한됨
- 절차적 질의어를 사용하여 한 번에 한 개의 레코드를 검색 가능
차이점은 무엇이냐? 부모를 하나 이상 가질 수 있게 됨.
- 관계 DBMS : 70년 E.F. Codd가 IBM연구소에서 제안. System R(이후 SQL로 표준이 됨)과 버클리대의 Ingres 프로젝트
인그리스를 발전 -> 포스트그레스가 됨 → ORDB(객체관계)

- 테이블을 기반으로 한 간단한 모델, 사용자는 원하는 것만 명시하고 데이터가 어디에 있고 어떻게 접근하는지는 DBMS가 결정.
- 관계 데이터모델은 대부분의 DBMS에서 사용되는 중요한 데이터 모델 (ex. SQL server. MySQL, Oracle, DB2 등)
- 객체지향 DBMS : 객체 지향 프로그래밍 패러다임을 기반으로 함. 관계 데이터베이스 매니지 시스템의 약점. 복잡한 구조를 해결해보려고 등장.
- 데이터와 프로그램을 그룹화하고, 복잡한 객체들을 이해하기 쉽고, 유지와 변경에 용이 BUT 회복 기능 미약
(ex. ONTOS, OpenODB, O2, GemStone 등)
- 객체 관계 DBMS : 관계 DBMS에 객체 지향 개념을 짬뽕.
- 관계 DBMS와 객체 지향 DBMS의 단점을 해결 BUT 복잡도 증가 -> 굳이 필요 없을 수 있다! (소나타 -> 제네시스!?)
(ex. Oracle, UniSQL 등)

파일시스템 : 단순, 질의어 없음
객체지향 : 복잡하나 질의어 없음
관계 : 단순한데 질의어 있음 → 표 등에서 유용
객체관계 : 두 장점 잘 지원
1.3.3 후딱지나가버림 → 설명 하긴 했음~

- 단일 사용자 DBMS : 엑셀 등
- 분산 DBMS는 클라우드 쪽으로 발전 -> 많은 서버들이 함께 사용자들의 요청을 받아 응답하는 형태
- 대부분의 DBMS는 범용 DBMS
<DBMS 언어>
직접 DB에 접근하는 목적으로는 C, JAVA와 같은 언어가 아닌 특별한 high level 언어를 사용함.
언어가 갖는 기능을 3가지로 나눌 수 있는데,
1. 데이터 정의어(DDefinitionL) : db를만들고, 테이블 만들고 레코드 집어넣고, 불필요한 테이블 지우는 것. 6장에서 나오는 인덱스를 만들고 지우는것. 8장에서 배우는 뷰를 만들고 지우는 것.
데이터 정의어로 명시된 명령이 입력되면, 사용자가 정의하는 스키마(테이블), 컬럼 정보, 시스템 카탈로그에 넣고 그 테이블에 해당되는 파일을 할당하여 테이블을 정의함.
- create Index : 인덱스를 생성하는 SQL 명령문.
- alter table : 테이블 만들고 컬럼이나 제약조건을 추가할 수도 있음. 그런 동작을 하는 SQL 명령문.
2. 데이터 조작어(DManipulatuonL) : 데이터를 다루는 것. 이를 사용하여 DB에서 원하는 데이터를 검색, 수정, 삽입, 삭제 등을 하게 됨 -> 4장에서
대부분의 데이터 조작어는 SUM, COUNT, AVG와 같은 내장 함수들을 갖고 있음.
- 절차적 언어와 비절차적 언어 : DBMS에 명령을 던질 때 내가 원하는 처리 순서나 방법을 DBMS에 알려주어야 하면 절차적 언어. SQL.

- 테이블을 하나 만들면 레코드가 하나도 없어. 그리고 이 테이블이 이제 카탈로그에 들어간다.
-> 데이터 조작어를 던지면 DB에 접근하게 되는데, select를 던지는데 없는 테이블로부터 검색을 하면 error가 나와야 함.
- 이런 명령어들을 던질 때, DBMS는 참조하는 테이블이 DB에 있는지 확인해야 함.
-> 반드시 스키마(메타데이터)를 훑어보고 있는 테이블로부터 조작어에서 원하는 동작을 수행해야함.
책 : 설명 없었음.

앤시/스파크의 3단계 구조. 개념, 내부, 외부 단계가 있음.
- 개념단계 : 그 조직체에서 사용하는 모든 테이블들의 모임 -> 그러나 모든 테이블을 다 필요로 하는 사용자는 없음. 일부에 관심이 있겠지
- 외부의 사용자들은 이 테이블에 접근하기 위해 sql을 배워야하는가? → 일반 사용자들을 위해서 app을 만들게 됨. 일반 언어와 sql과 같은 언어를 함께 사용.
- 이 테이블들을 어떻게 저장할 것인가가 내부 단계.
3. 데이터 제어어(DControlL) : DB 트랜잭션을 명시하고, 테이블에 대한 권한을 허가/취소하는 역할을 함. -> 매우 중요!
<DBMS 사용자>

- DBA(데이터베이스 관리자) : 데이터베이스에 관한 모든 중요한 정책을 결정. CTO, CIO 바로 아랫사람
1. 일관성 있는 DB 스키마를 생성하고 변경하고 유지.
2. 무결성 제약조건을 명시 : 컬럼의 데이터타입, 값들의 범위 등을 명시
3. 사용자의 권한 및 역할 관리
4. 저장 구조와 접근 방법 정의
5. 백업과 회복
6. 표준화 시행 : 급여지급 할 때 여러 은행을 기업에서 허용한다면
→ 은행의 이름들이 조금씩 바뀌는데, 그냥 문자열로 쓰면 약어를 쓴다던가 하면 여러가지 문자열이 존재하게 됨.
→ 표준화 시행에 중요한 것이 코드. ex)01은 국민 ,02는 신한 뭐 이렇게.
- 응용 프로그래머 : DB 위에서 특정 응용이나 인터페이스를 구현 -> 최종 사용자들이 반복해서 수행하는 APP(기작성 트랜잭션) 등을 만드는 사람(외부단계 하는 사람).
C와 같은 고급 프로그래밍 언어를 통해 개발하면서 DB에 접근하는 부분은 SQL과 같은 내포된 데이터 조작어를 사용.
- 최종 사용자 : 캐주얼 사용자(DB 질의어 사용)와 초보 사용자(기작성 트랜잭션을 반복 수행)로 구분
- DB설계자 : ERWin과 같은 CASE도구(computer-aided software engineering, 툴)들을 이용해서 DB 설계를 책임짐. 정규화도 수행.
- 오퍼레이터 : 특별한 기술이 필요 없는 사람. 컴퓨터 시스템과 전산실 관리 -> DB가 새어나갈 수 있음.
<ANSI/SPARK 아키텍처와 데이터 독립성>
DBMS의 주요 목적은 사용자에게 데이터에 대한 추상적인 뷰를 제공하는 것
-> 데이터가 어떻게 저장되고 유지되는가에 관한 상세한 사항을 숨기는 것이다.
이런 3단계 DB 아키텍처는 DB에 대한 사용자의 관점과 실제 DB가 표현되는 방식을 분리하는 것.
이것이 왜 바람직한가?
1. 독립적인 사용자 맞춤형 뷰 제공
2. 사용자를 위해 상세한 물리적인 저장을 숨김
3. 관리자는 사용자들의 뷰에 영향을 미치치 않으며(뷰를 유지하며) DB저장구조 혹은 개념/전역적인 구조를 변경할 수 있어야 함.
4. DB내부구조는 저장의 물리적인 측면(디스크)이 바뀌어도 영향을 받지 않아야함
외부 단계 : 각 사용자의 뷰 -> 각 사용자가 데이터베이스를 보는 관점
개념 단계 : 사용자 공동체의 뷰 -> 어떤 기업에서 사용하는 모든 테이블을 다 모아둔 것
내부 단계 : 물리적 또는 저장 뷰 -> 각 테이블이 디스크에 어떻게 저장되어 있는가.
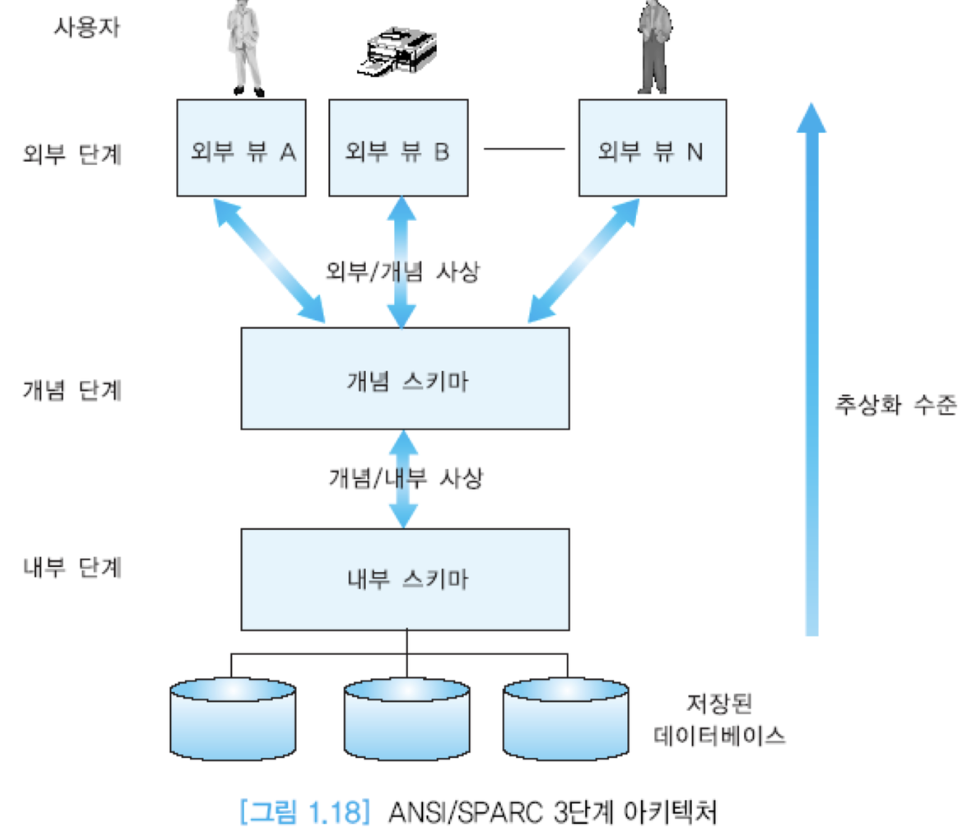
- 각 사용자가 보는 관점이 외부 뷰가 됨 -> 당연히 개념 스키마에 없는 것에 접근할 수 없음.
-> 동일한 개념 단계로부터 서로 다른 뷰가 제공될 수 있음.
ex. 예를 들어, 대학교 데이터베이스에서 한 학과의 학과장은 학과의 예산과 학생들의 수강 정보에는 관심이 있지만 도서관에 관한 정보에는 관심이 없을 수 있다.
- 전체 데이터 베이스의 논리적인 구조(데이터간 관계, 무결성 제약조건 등)를 개념 단계에 기술 -> 공동체의 뷰(하나)를 나타냄.
-> 물리적인 구현은 고려하지 않으며 DB마다 조직체 전체에 관한 하나의 스키마만 존재.
- 내부 단계에서는 효율성을 가장 중요하게 고려하여 데이터 구조가 선택됨. 인덱스, 해싱 등과 같은 접근경로 및 데이터 압축 등을 기술.
내부 단계에서는 물리적인 저장 장치를 직접 다루진 않음(운영체제가 관리). 물리적인 장치가 물리적인 페이지들의 모임으로 이루어진다고 가정하고, 논리적인 페이지들의 관점에서 공간을 할당.
-> 인덱스와 달리 해싱을 허용하는 DBMS는 거의 없음.
-> 인덱스를 얼마든지 추가하고 지워도 개념스키마가 영향을 받지 않음. -> 최소로 영향을 미치게 한다가 3단계 아키텍처의 최고의 장점임.-> 어떤 데이터가 어떻게 저장되어 잇는가를 기술함.
위로 올라갈수록(내부->개념->외부) 상세한 것을 배제 -> 추상화 수준이 높아짐.

개념스키마로, 관계db에서 테이블 3개 -> 임플로이, 프로젝트, 웤스로 구성되어있음.
기본키는 ENO, PNO, ENO. RESP : 역할. DUR : 기간
이때 사용자 EMP_NAME는 3개를 다 보는게 아니라, EMP_NAME(2개 컬럼으로 이루어진 뷰)이라는 관점에서 볼 수 있음.
어사인먼트도 여기 없는데, 개념스키마에 있는 두 개의 테이블로부터 필요한 컬럼들을 골라서 외부 뷰를 만들 수도 있음.
- EMP라는 놈이 디스크에 어떻게 저장되어있는가, 기본키에 대해서는 dbms가 내부스키마에서 알아서 인덱스를 정의해준다.
디스크상에서 이 EMP, PROJ, WORK 3개의 테이블이 이렇게 조직되고, 이런것들을 설명해는게 내부스키마.
일반 사용자는 외부 뷰를 통해 db에 접근한다. → 데이터베이스는 끊임없이 변화하니까 개념스키마든 내부스키마든 변화할 수 있다.


- 노선도 -> 시민들이 보는 관점을 모두 합쳐놓은 개념 스카마에 해당.
- 각 사람들이 관심을 갖는 각각의 역들이 외부 단계에 해당.
- 전철이 교류를 사용하는지 직류를 사용하는지, 에스컬레이터가 있는지, 각 전철이 몇 량으로 구성되었는지 등이 내부 단계에 비유됨.
- 외부 단계의 뷰를 사용해서 개념 단계에 없는 질의를 던지면, 해당되는 테이블에 대한 SELECT문으로 바꿔서 질의를 수행해야 함
-> 외부/개념 매핑(사상)은 이를 변환시킴.
- 이 SELECT문을 처리하다 보면, 디스크상에 어떤 파일에 저장한 것인지 접근해야 함
-> 개념/내부 매핑(사상)을 통해 개념 스키마 내의 한 논리적 레코드를 구성하는 물리적 저장장치 내의 실 레코드 또는 그들의 집합을 찾을 수 있음.
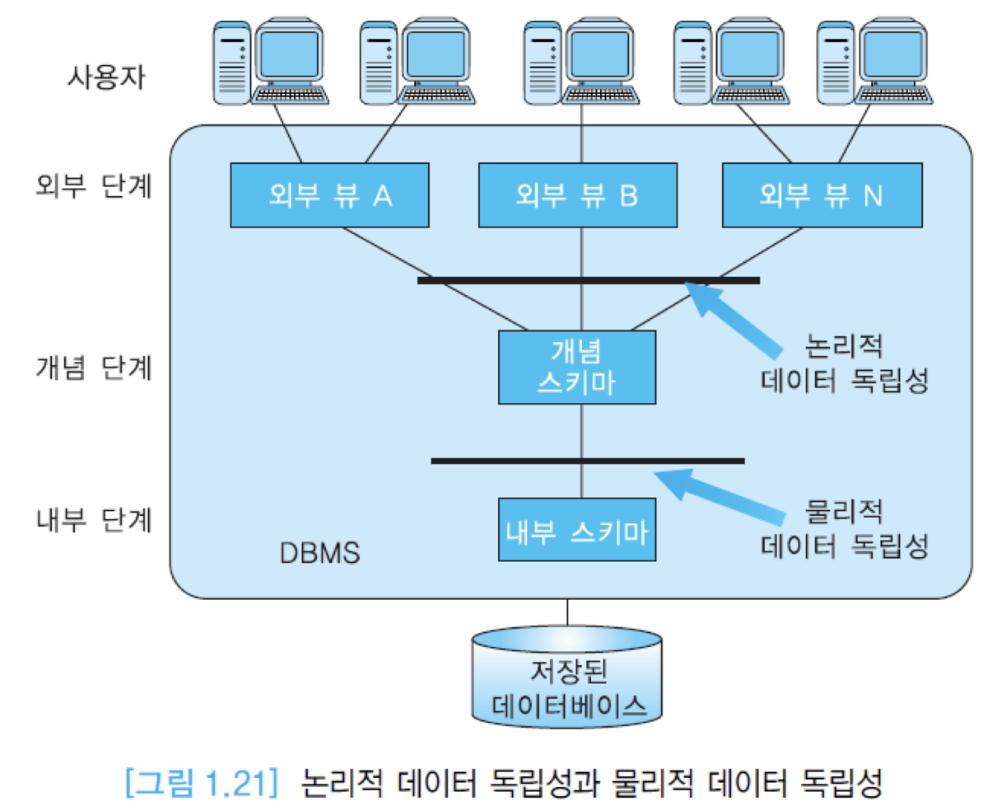
- 데이터 독립성 : 상위 단계 스키마 정의에 영향을 주지 않으면서 어떤 단계의 스키마 정의를 변경할 수 있음을 의미.
-> ANSI/SPARK 아키텍처의 주 목적. DBMS를 쓸 때의 큰 장점.
논리적 데이터 독립성 : 개념 스키마에 데이터를 추가 하든 뭘 하든 외부 스키마가 영향을 받지 않음.
물리적 데이터 독립성 : 내부 스키마를 건드려도 개념 스키마에 영향을 주지 않는 것(ex. 화일의 저장구조를 바꾸거나 인덱스 생성 삭제)
-> 이 덕분에 응용 프로그램들은 데이터가 어떻게 물리적인 구조를 갖고 저장되었는가를 신경 쓸 필요가 없음. DBMS에 맡김.
<데이터베이스 시스템 아키텍처>

1. DB관리자가 DDL을 사용하여 테이블 생성을 요청하면, DDL 컴파일러가 이를 번역하여 테이블이 화일 형태로 DB에 만들어지고, 명세(컬럼들의 데이터타입 등)가 시스템 카탈로그에 저장됨.
-> 시스템카탈로그와 데이터베이스는 같은 디스크에 있어도 상관없음.
2. 최종사용자or응용 프로그래머가 DML을 사용하여 접근하려하면 DBMS의 질의처리기(쿼리 프로세서=쿼리 옵티마이저=질의 최적화 모듈 -> DML을 수행하는 최적의, 최적에 가까운 방법을 찾는 모듈)를 통해 기계어 코드로 번역
2.5. DBMS의 런타임 데이터베이스 관리기에 의해 DB가 접근됨.
-> 이 과정에서 사용자가 원하는 테이블이 DB에 존재하는가, DML을 입력한 사용자가 권한이 있는가, 어떤 접근경로가 존재하는가 등을 시스템 카탈로그에 접근하여 확인.
3. 데이터 불일치 혹은 DB에 접근하다 다운되는 경우를 해결하기 위해 = 일관성을 보장하기 위해 동시성 제어 모듈 + 회복 모듈 = 트랜잭션 관리 모듈이 사용됨.
-> 트랜잭션 관리가 실무적으로도 이론적으로도 중요함.

-pre 컴파일러 : 고급언어 안에 sql을 내장하여 프로그램을 만들 때 먼저 골라서 번역하는 컴파일러
-> C코드 사이에 SQL문이 들어오면 번역 불가 -> SQL문만 꺼내어 먼저 번역 함.
-> C에서 허용하는 함수 호출문을 대신 넣어주고(대치 시켜주고), 이후 C컴파일러가 동작하면 쭉 번역을 진행할 수 있음.
< 데이터베이스 API >

- API : 공통적으로 사용되는 데이터베이스 접근 유형을 위한 라이브러리 함수들의 모임. -> 각 제품에 고유한 DB API를 가짐.
- ODBC : MS 주도 개발, 산업계의 표준 -> 응용들 간에 사용
- JDBC : 자바를 위한 드라이버 -> 자바 프로그래머가 관계DB에 접근할 때 사용
-> 두 표준 데이터베이스 API의 목적 : DB에 대한 접근을 간단히 하며 DB간 차이점을 숨김.
-> 표준 데이터베이스 API를 지원하는 DBMS간에는 서로 상대방의 데이터베이스에 접근할 수 있음. ODBC를 통해 데이터를 교환함.


- 중앙 집중식 : DB시스템이 하나의 컴퓨터 시스템에서 운영됨. 이에 여러 단말기에서 접근. -> 흩어진 DB 접근 요청 처리 가능
- 분산 : 네트워크로 연결된 여러 사이트에 DB가 분산되어 있으며, DB시스템도 여러 컴퓨터 시스템에서 운영됨.
-> 사용자에겐 분산되지 않은 것처럼 느끼게 만드는 것이 필요함.
우측 이미지 좌하단의 한 묶음이 하나의 세트 -> 핵심은 데이터베이스가 여러 서버 내지는 사이트에 분산되어서 저장이 된다.
저 번개표시는 끊어졌다가 아니라, 왔다갔다 한다는 것.
중요한 것은 오라클이 ordb도 제공하고 분산db도 제공하는데, 분산 기능이 없는 오라클을 3개로 분산해봤자 의미없겠지?
-> 분산db옵션이 있는 오라클을 깔아서 타 데이터베이스 테이블에 접근하는게 가능해짐.

동질적(homegeneous) : 같은 회사의 DBMS만 사용
이질적(heterogeneous) : 오라클도 사용하고 인포믹스도 사용하고 여러 DBMS를 이용해서 분산 DB를 구축 -> 난이도가 높음
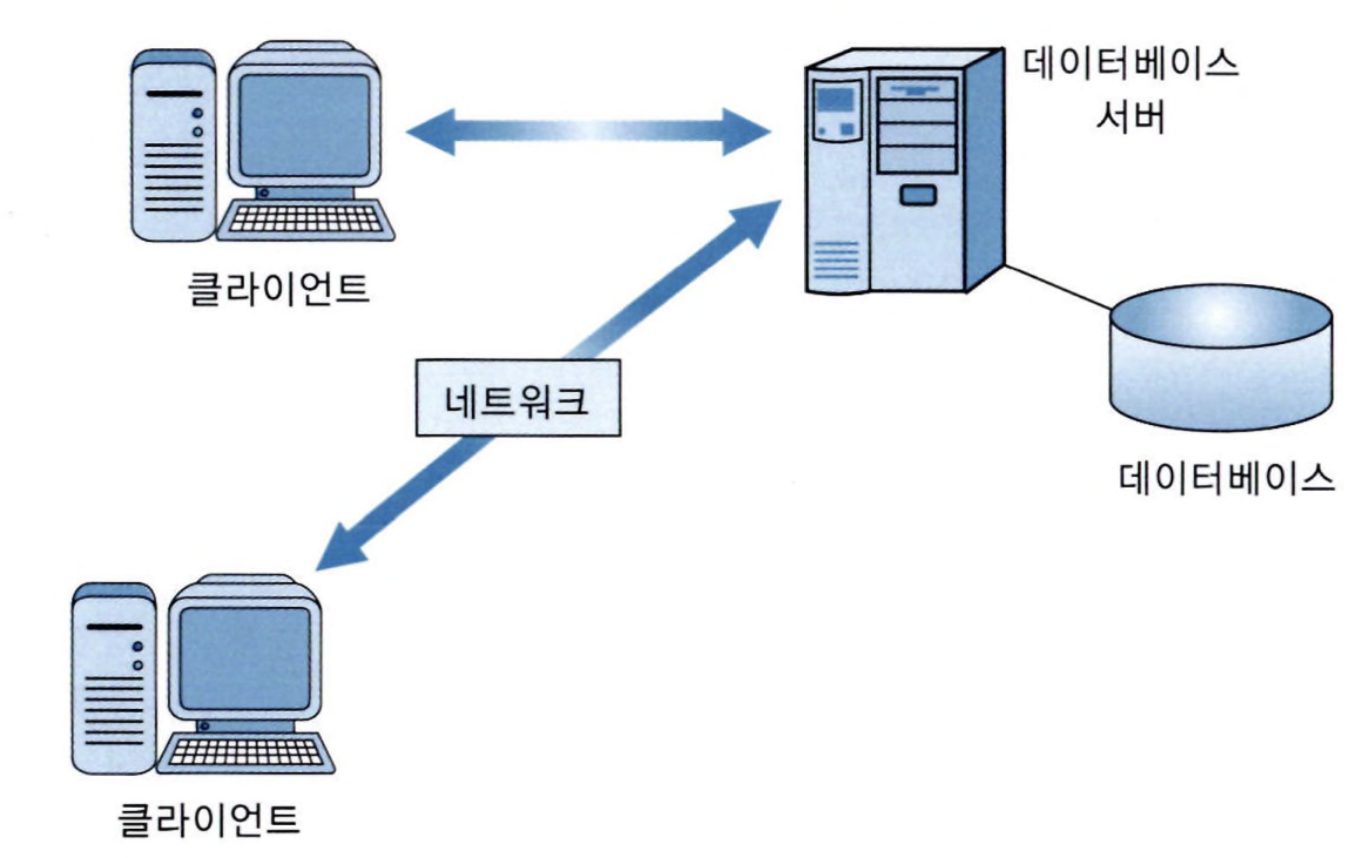
- 클라이언트-서버 데이터베이스 시스템 : 자체 컴퓨팅 능력을 가진 클라이언트를 통해 DB 서버를 접근함. 지금의 스마트폰과 가까움.
서버 : DB 저장, DBMS 운영하며 클라이언트부터로의 질의 최적화, 권한 검사, 동시성 제어 및 회복, 데이터 무결성 유지, 데이터 접근 관리
-> 오라클이나 db2 같은 데이터베이스 엔진이 돌아감.
클라이언트 : 입출력 및 UI관리, 응용 수행
-> 클라이언트 프로그램이 돌아감.


- 2층 모델 : 클라이언트와 DB서버가 직접 연결 -> 응용의 논리가 업무가 위 아래로 분산되어 서버가 하는 일이 많아짐
- 3층 모델 : 클라이언트와 데이터베이스 서버 사이에 응용 서버가 추가됨. -> 사용자가 많은 환경에서. 응용의 논리를 분리.
-> 서비스 요청과 응답이 클라이언트-응용서버 간에만 전송되기에 성능이 향상되고, 응용서버 덕분에 구현 및 유지보수에 용이.
3층 모델에서
클라이언트 : 프레젠테이션 기능 수행, GUI 관리, 네트워크 접근을 제공하는 통신 SW 실행.
응용 서버 : 비즈니스와 데이터 논리 처리
데이터베이스 서버 : 데이터베이스를 관리
프레젠테이션 로직 : gui를 잘 만들수록 좋은 것.
-> 키보드 마우스 또는 화면의 반절로 나타나는 키보드 등을 통해서 원하는 작업을 어떻게 입력할 것인가. 아웃풋은 결과를 보여주는것
처리 로직의 비지니스 룰 : 은 기업이 업무를 수행해나가는 어떤 일종의 규칙 ex)뭐 렌트카 늦게 반납하면 어떡할거냐 그런 것들.

파일 서버 아키텍처 : 중앙 파일 서버가 있고, 클라이언트 컴퓨터는 파일을 요청하고 공유된 파일을 이용
데이터베이스 서버 아키텍처 : 데이터베이스 관리 시스템 (DBMS)을 사용하여 데이터를 관리하는 데 중점
삼계층 아키텍처 (Three-Tier Architecture) : 사용자 인터페이스(클라이언트 계층), 비즈니스 로직(애플리케이션 계층) 및 데이터 관리(데이터베이스 계층)를 분리하여 관리하고 확장성을 향상
-> 클라이언트가 아주 적은 일만 수행.

씬 클라이언트 : 3계층 모델에서 클라이언트가 하는 일이 적다.
-> UI 동작시키는 정도만 함. 응용의 처리로직은 아주 조금만 떠맡음. 저장공간은 없어도 되고 조금만 있어도 됨.
-> 많이 사용되는데, 모든 사용자에게 새로운 버전을 강제하는 것이 어려움. 업데이트를 안하면 그만이라서.


비즈니스 룰이 돌아가는 응용서버, dbms가 돌아가는 db서버.
비즈니스룰 담당하는 서버가 있으니까 db서버의 역할이 줄어들지
또한 클라이언트가 하는 일도 그만큼 적을 것이고
클라이언트의 성능이 떨어져도 인터페이스를 돌리는게 별 무리가 없다.

db서버에 dbms가 돌아가는데,
웹 서버=응용서버가, 비즈니스룰 같은거 담담하고 클라이언트는 웹브라우저, gui를 통해 요청을 하고 결과를 받아보게 됨.
- 클-서버 데베 시스템 장점 : 보다 넓은 지역에서 DB에 접근 가능. 다양한 컴퓨터 시스템을 사용 가능.
- 클-서버 데베 시스템 단점 : 보안이 다소 취약. 또한 업데이트 하는데 시간이 걸림
-> 순간적으로 모든 클라이언트의 프로그램을 바꾸는 것이 불가능하기 때문
'UOS@DB' 카테고리의 다른 글
| 4장 관계대수와 SQL ( SQL 개요, 데이터 정의어, SELECT문1/2) (0) | 2023.11.04 |
|---|---|
| 4장 관계대수와 SQL (4.1 관계대수) (0) | 2023.11.04 |
| 3장 오라클 (1) | 2023.11.03 |
| 2장 관계 데이터 모델과 제약조건 (1) | 2023.10.16 |
| 1장 DB 시스템(1/2) (0) | 2023.10.09 |