



- 트랜잭션 : 하나의 단위로 취급하는 SQL 문장들의 모임.
-> 많은 사람들이 동시에 DB에 접근해서 사용하는데 번호표를 다 지정해줘.
-한 번에 하나씩 하면 ㅈㄴ오래걸리겠지. 동시에 트랜잭션을 허용해야함.
- DB를 쓰는 도중에 죽었따 살아났따 어떡할거냐! 절대로 데이터베이스에 뭔가가 깨지는걸 냅둬서는 안된다.


- 500명이 재직. 급여협상.
- 500명의 레코드가 한 블록에 다 들어가느냐? 4,8kb잡아도 500명분이 다 들어갈 순 없겠지.
- 한 블록에 20개, 25개의 블록을 디스크에서 주기억장치 버퍼로 가져와서 모두 버퍼에 읽어서 급여를 6% 올려서 하다가, 25개를 다 버퍼에 올릴 수 있으면 다 올리면 되지.
- 뭐 그랬다 치더라도 이걸 디스크에 동시에 기록하는건 불가능하지. 16번째 블록 기록하다가 죽은거야. 그래서 다시 부팅을 했다. -> 17번째 들어있는 사람들부터는 인상이 되지 않았음. 2가지 옵션이 있다.
- 걍 오류때부터 다시 시작? → 불가능함.
- all or 나씽 해야함. 나씽으로 돌리려면 이미 6% 인상 된 애들은 어떡해? 돌아갈 수 가 없어!
-> 그래서 로그를 반드시 유지한다. 로그는 히스토리.
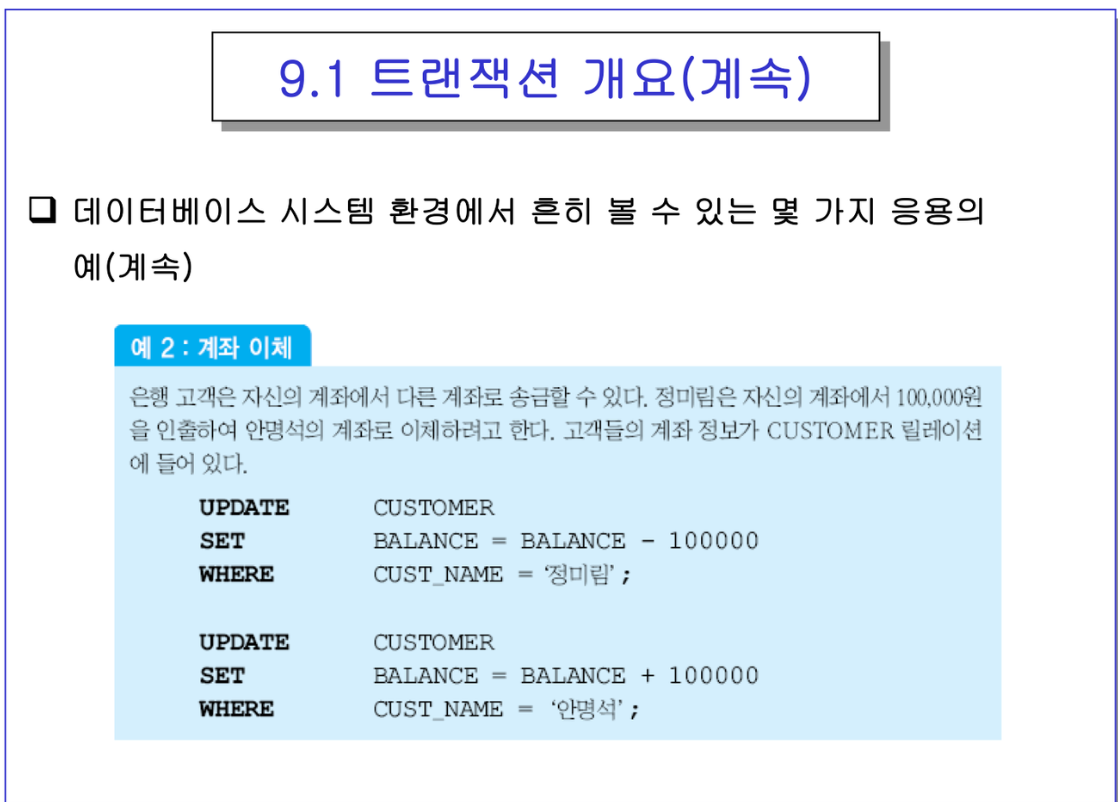

- 정미림에서 빼고, 안명석에 올려줘야함. 이 두개는 하나의 단위로 취급해야함.
- 각각의 sql문장을 하나의 트랜잭션으로 취급하기 때문에, 다른 키워드를 써줘야함.
- 고객이 천만명이라면, 블록 하나에 계좌가 20개 들어간다. 그럼 50만블럭이 필요함. 안명석과 정미림이 같은 블럭에 있을 확률이 몹시 낮음.
→ 디스크에서 정미림 블럭, 안명석 블럭 → 주기억장치 버퍼에 가져와서, 두 블록을 동시에 롸이트하는건 불가능함. 하나를 먼저 롸이트 해야함. 근데 중간에 기계가 죽었다면?
- 완전하게 all or 하나도 noting. dbms가 하나의 트랜잭션 처럼 보장해야함.


홈페이지에서 비행기 조회하고 빈자리 있으면 예약하고. 결제하고 할텐데
- 비긴 → 트랜잭션이 시작.
- 비긴 인풋 → sql은 키보드에서 문자열이나 숫자 받아들이는 기능이 없으니, scanf 같은데서 받아들이는 것.
→ 이그젝 sql → C문 사이에 sql문. 총좌석수와 팔린 좌석수를 변수에 담음. 그럼 플라이트 릴레이션에서 떠나는 날짜, 플라이트 넘버를 입력해서, 리턴해줌.
- if 절 → 없다면 트랜잭션이 죽음. Abort → noting으로 돌아감
- else = temp1 <temp2
→ 팔린 좌석을 하나 늘려줌. 그 요일의 빌행편의 좌석수를 하나 늘려줌.
→ 예약자 명단에 리저브드에 FNO, 날짜, 커스터머이름, 스페셜(특이사항)를 밸류즈에 있는 값으로 넣어줌.
- 그럼, SOLD + 1 하고 시스템이 죽으면 어떡할것이냐? 비행기 못탈텐데
→ 회사에서도 팔린좌석은 늘었는데 사람은 못태우고,,,
-> 그래서 이 123을 모두 수행하던가 하나도 수행안시키던가 보장해야함. 끝나면 커밋. 엔드까지 한 단위로 취급

- A 원자성 : 한 트랜잭션은 all or nothing을 보장. 회복 모듈은 중간에 죽으면, nothing으로 되돌려야함.
- 트랜잭션이 할 일을 다 끝내고 디스크에 저장중이다?
→ 회복에서 자세히 볼건데, 디스크에 반영이 완전히 안됐을 수 있음 → 재수행 해서 all을 보장.
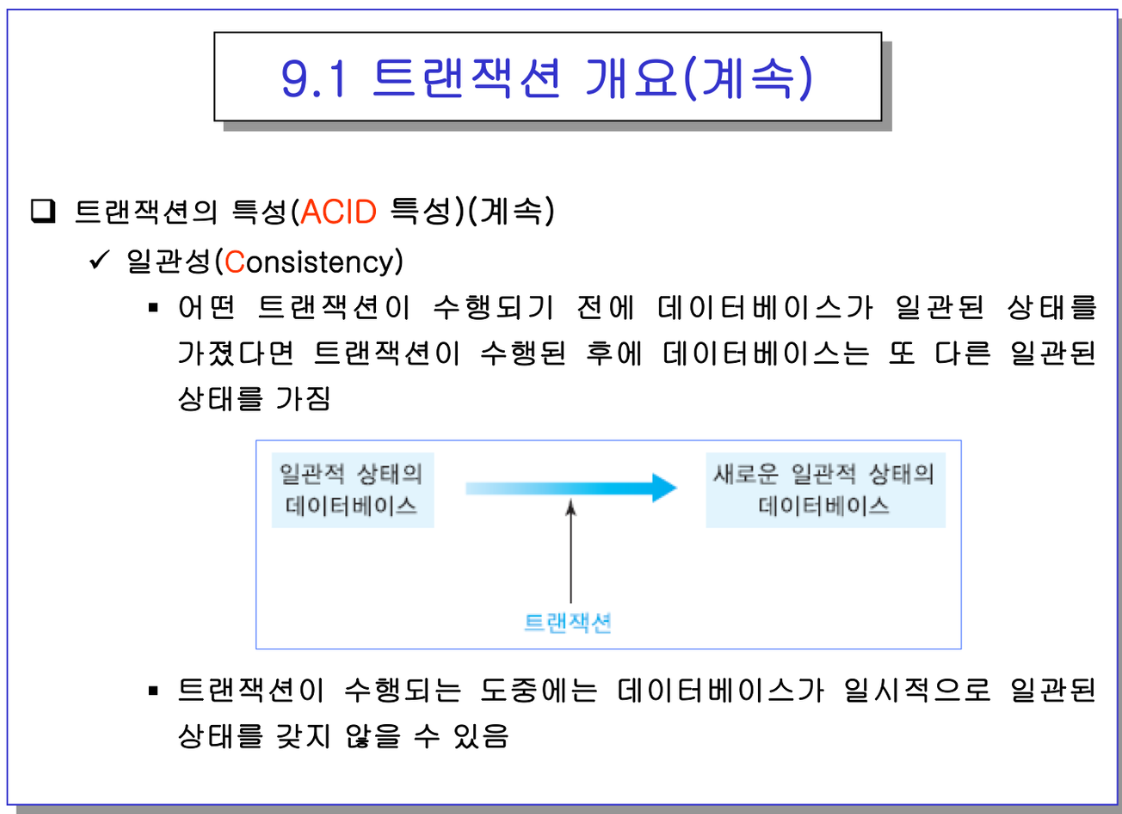
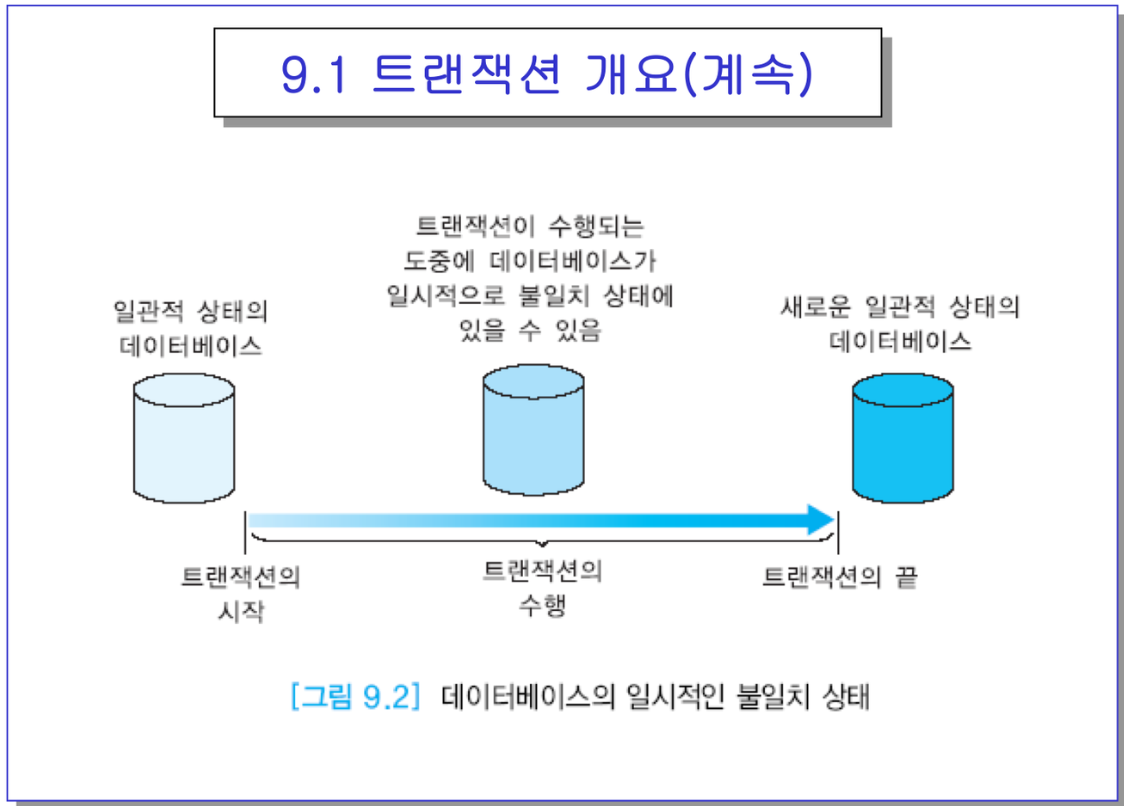
- C 일관성 : 일관적 상태를 유지해야함. → 각 테이블을 정의할 때 사용자가 명시한 제약조건 등,,
- 일관된 DB → 새 일관된 DB로 바꿔주는게 트랜잭션의 역할. 찰나에 일시적으로 불일치 상태에 있을 순 있음


- I 고립성 : 한 트랜잭션이 갱신중인 데이터를 다른 트랜잭션이 읽지 못함. 막아준다. → 순차 수행 or 직렬 스케줄
-> DBMS의 동시성 제어 모듈이 트랜잭션의 고립성 보장.
- D 지속성 : 따운되었다가 재시동되어도 날라가지않는다. -> 로그

- 일관성은 테이블 정의할 때 사용자가 지정한 무결성 제약조건도 한 몫함.
- 동시성제어 : 일관성과 고립성을 제공하는 역할

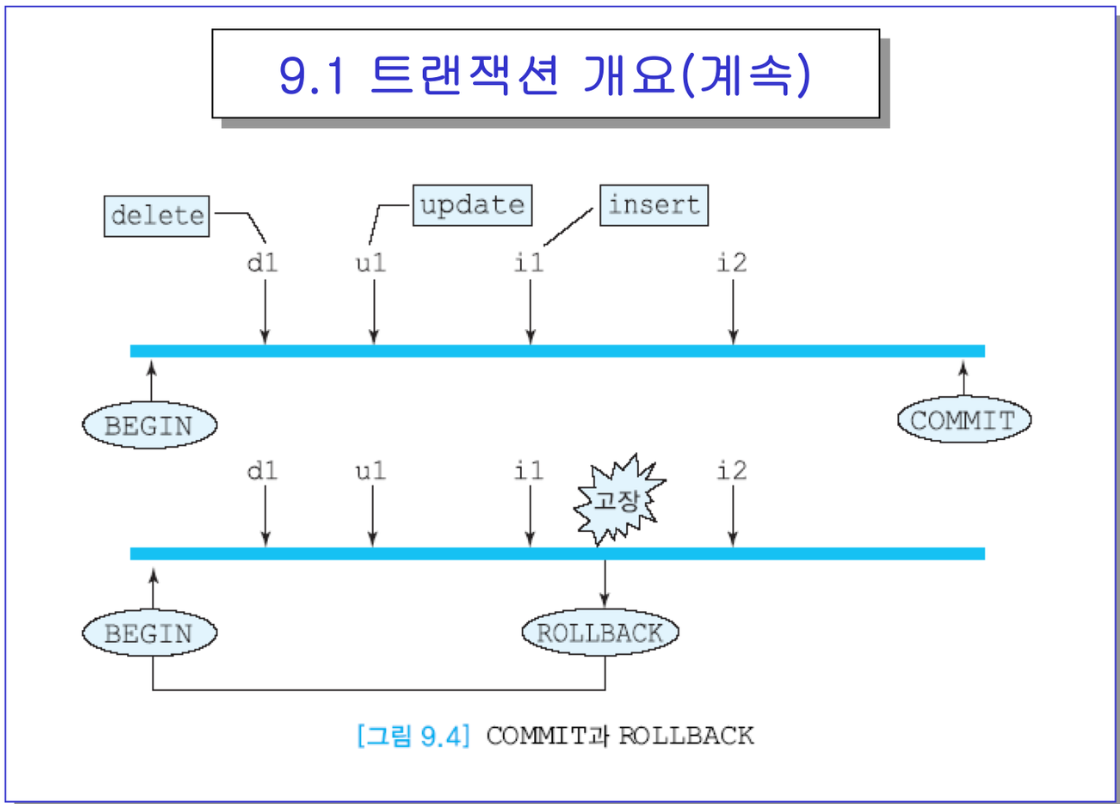
보면됨~

- 트랜잭션이 죽는 이유는 많다
ex) 데드락, 사용자 요청 → 희생자 트랜잭션 죽이고 걔가 가진걸 다른 트랜잭션에게 나눠줘야함.
ex2) 매체 고장은 대응 불가
<동시성 제어>

- 트랜잭션은 4가지 성질을 만족해야하는데 A C I D, 그 중 동시성제어 : 일관성과 고립성을 제공하는 역할
if 한 명이 끝나고 다음. 그 다음이 끝나고 다음이면 CPU는 계속 쉬잖아.
-> 프로세스 내지 트랜잭션 하나가 CPU를 배정 받았고, I/O도 해야함
→ 기다리게 하면 뒤의 트랜잭션들이 쉬고 있어야함. CPU도 쉬고
- 동시성을 제공 해야함
→ 그러나 여러 사용자들이 다수의 트랜잭션을 동시에 수행하는 환경에서 부정확한 결과를 생성할 수 있음. 부정확한 결과를 생성할 수 있는 간섭이 생기지 않도록 해야함.

- 직렬 → 일이 3가지면 3! = 6가지.
- 비직렬을 임의로 허용하면 DB에 심각한 문제가 생길 수 있음
→ n!만큼 가능한 직렬스케줄하고 동등한 결과를 내도록 하는 것만 가능하게 하자.
→ 모든 비직렬 스케줄을 무한정 푸는게 아니라, 그 중에서 직렬 스케줄하고 동일한 결과를 내는 놈만 허용하자.
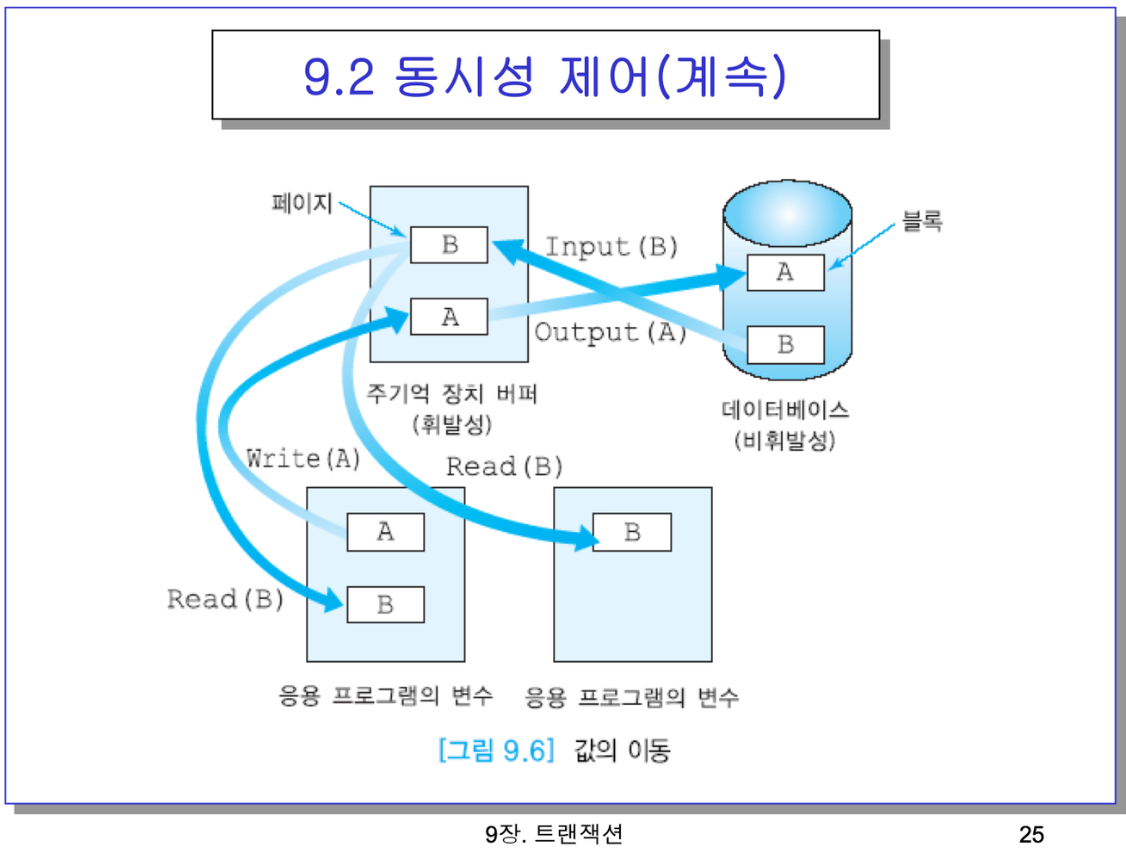

- 그림을보면, 네모 3개가 다 RAM임. 버퍼가 있고, 프로그램들이 돌아가면 프로그램이 결국 프로세스니까 프로세스들이 주기억장치의 일정부분을 배정받을 것.
ex) B를 디스크에서 버퍼로 읽어서 아래에 복사해주는 것.
-> 이 버퍼에 담아두고 수많은 트랜잭션이 버퍼에 있는 블록들을 읽어다 필요한 레코드를 골라서 씀. 그럼 뭐 날라갈수도 있고. 또 조금바뀔때마다 디스크에 기록하면 그 수행시간을 많이 잡아먹니까
-> 그걸 최대한 늦췄다가 디스크로 보내야겠지(페이지 교체 알고리즘에서 봤듯이)
- 25p에서말한 연산들이 이거임. 항목은 레코드 블록 컬럼이 될 수 있음. 인풋 10ms, 아웃풋 10ms 정도(?)

- 임의로 동시에 실행시키면 이런 문제가 생김.
- 하나의 실렉트문은 내부적으로 여러 단위명령으로 나눌 수 있음. 다수 사용자 환경에서 여러 명령들이 섞여서 실행될 수 있음. 왜? 비직렬스케줄로 트랜잭션 수행하니까.

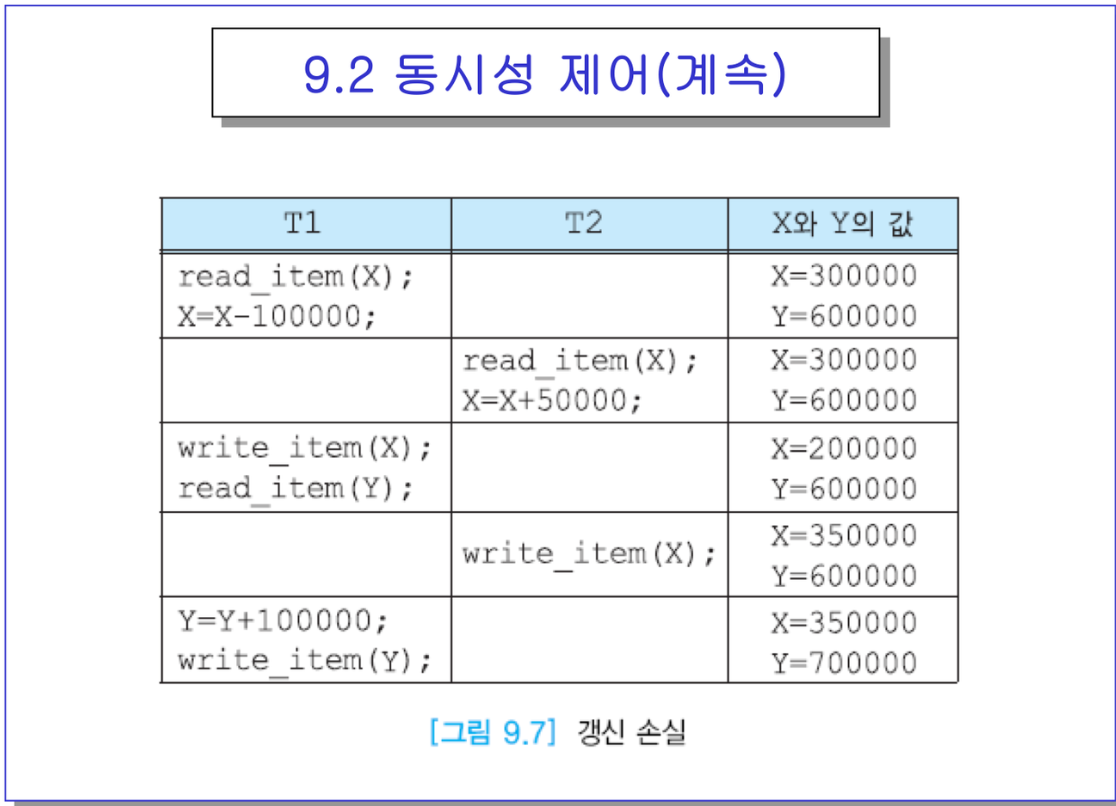
다수 사용자 환경에서 여러 명령들이 섞여서 실행될 수 있음. 비직렬스케줄로 트랜잭션 수행하니까.
- T1 후 T2 직렬 스케쥴 : x 30→20, y 60→70 / x 20→25 // 최종 25, 70
- T2 후 t1 직렬 스케쥴 : x 30→35 y 60 / x 35→25 y 70 // 최종 25, 70
→ 뭘 먼저하든 끝나고 나면 최종값은 동일
- 비직렬 스케줄로 한다면,
- T1버퍼와 T2버퍼가 있다고 한다면 x를 둘 다 불러내지만 각자의 T1, T2에서만 수정된 것.
-> 그래서 버퍼에서는 계속 30을 불러옴.
- 그러고 3번째 라인에서 write x를 하면 20이 되겠지. 그러고 cpu가 t2로 넘어와서 write x를 하면 다시 35가 됨. 덮어씌워짐
→ t1의 갱신결과가 날라갔음
- 그러고 cpu가 다시 t1으로 넘어와서 write y하면 y가 70. 그래서 35,70이 됨
→ 앞과 비교해서. 직렬 스케줄과 다름.


오손 : dirty(일관성이 깨진 데이터)
- 정미림 잔액이 30이었다면, 20으로 줄겠지 -> 근데 롤백이 되어버리면, 잔액이 30으로 복귀되겠지
- 그럼 전체 평균에서 미치는 영향은 소소하겠지만, 완료되지 않은 트랜잭션의 고친 값을 T2에서 읽었으니까.
-> 더티 데이터를 읽었다 라고 함.

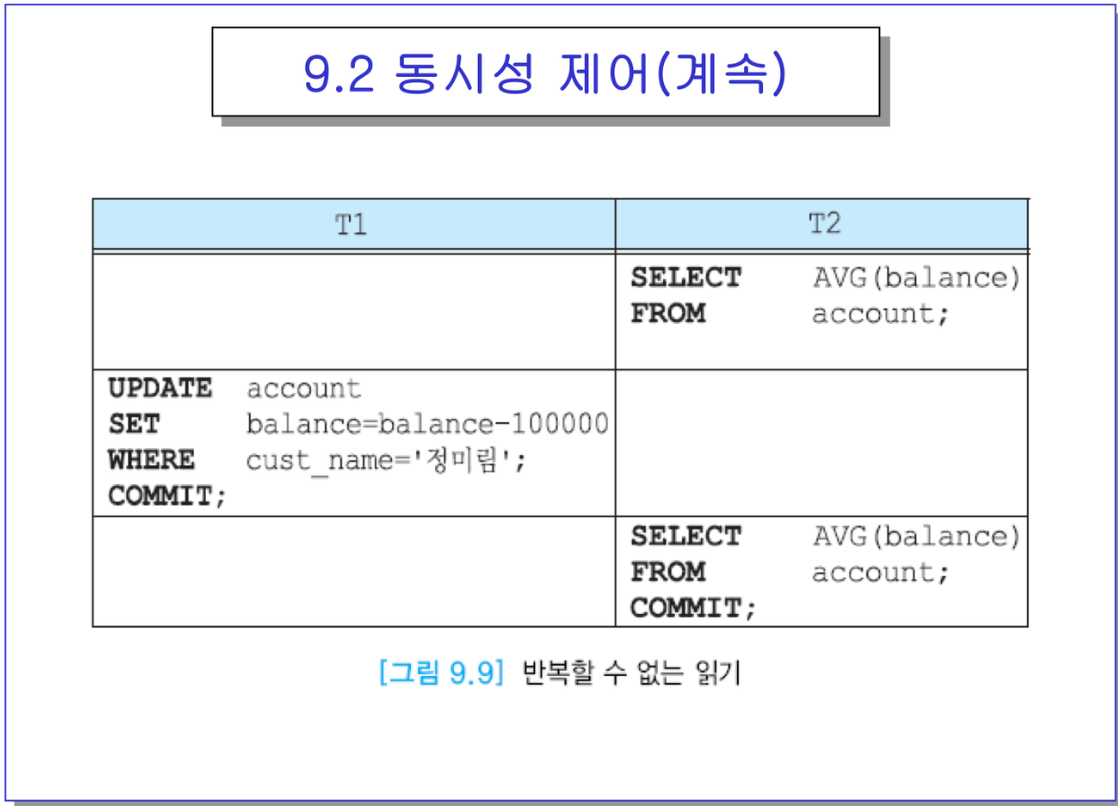
똑같이, 평균을 T2가 실렉트 -> 그리고 cpu가 T1으로 넘어감. 커밋을 했음.
- 그러고 다시 T2로 넘어와서 평균 잔액을 구하면, 여기서는 정미림 잔액이 10만원 빠진 후지.
-> 평균이지만 그래도 둘의 값이 미세하게 다를 것.



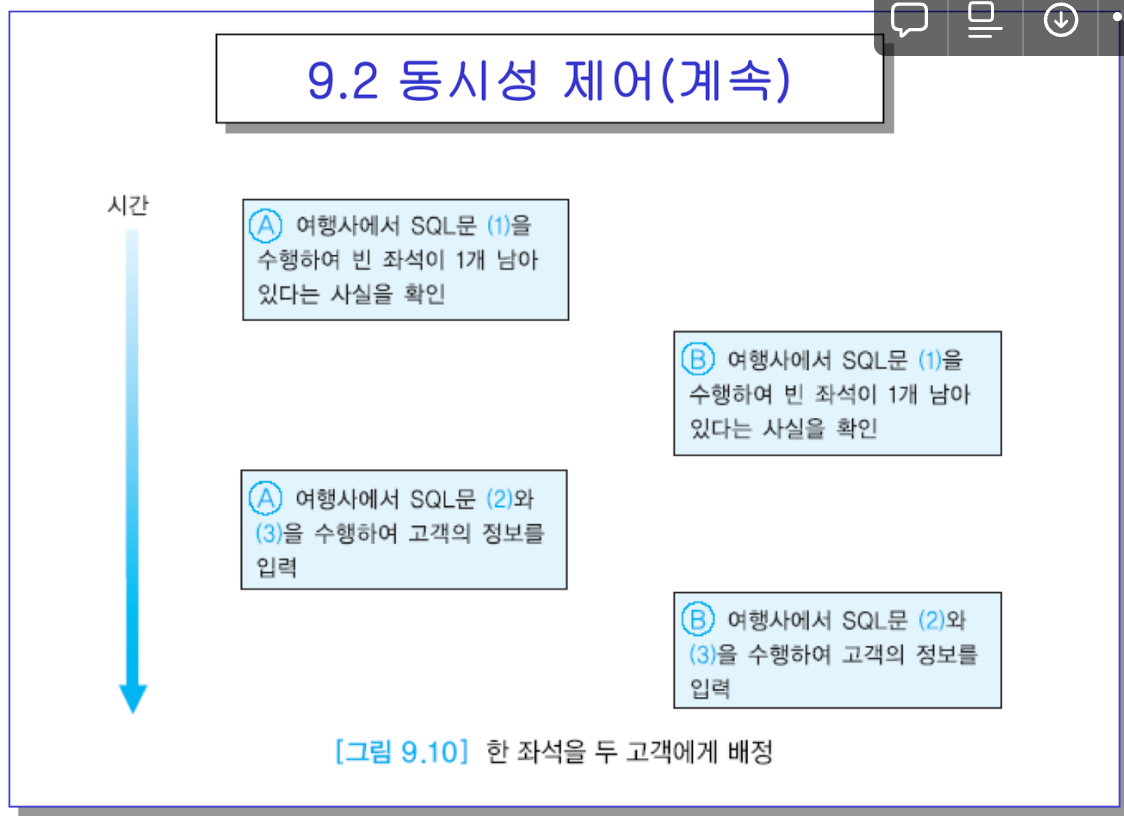
- 같은도시에 같은날 도착하는 비행기표를 서로 찾을 수 있음.
- A여행사에서 누군가의 전화를 받고 검색해보니 자리가 하나 남아. B도 마찬가지.
-> CPU가 A로 먼저 넘어오면, A의 고객의 예약정보를 넣었음. 그러고 B → 한좌석에 두 고객의 정보를 넣었다


동시성제어는 3가지가 나왔는데. 로킹 타임스탬프 옵티미스틱(낙관적)
- 그럼 어느 경우에 어떤 것이 좋으냐? → 로킹!
- 로킹의 개념 : 데이터 항목마다 변수가 하나 있다고 생각. 실제로 레코드에 있는건 아니지만, 그런 변수가 있다고 가정. = 로크는 레코드, 페이지, 릴레이션, 데이터베이스 각 항목마다 연관된 변수가 있다고 가정.
- 사용자는 전혀 신경 쓸 필요가 없음. 각 트랜잭션이 수행 시작해서 데이터항목 접근할때마다 사용자 대신해서 로크를 함.
- 갱신할땐 독점로크. → 끝날 때 로크를 품.
- 읽을땐 공유 로크 -> 끝날 때 로크를 품.
- 로크가 안걸려있는데 그 데이터를 읽을 목적으로 로크를 요청하면, 허가. 독점도 허가.
- 현재 공유로크가 걸려있다면, 공유로크는 허용해줌.
- 근데 독점로크가 걸려있다면, 읽지도 못하게 함.


- A 10 B 20으로 가정해보자.
- A읽고 하나 증가시키고 버퍼에 write함 → 미리 독점 로크를 요청하자
-> 그러고 T2에서 또 요청해서 로크를 걸고 *2하고 write하고 로크를 품 → B잡아서 이제 *2.그리고 로크를 품.
- 다시T1으로 넘어오면 B에대해 독점로크 요청하면 받을 수 있고, +1해서 41이됨. 이걸 버퍼에 씀.
→ A 22, B 41 이는 직렬 스케줄과 다름.
- 직렬 T1→T2로 하면, T1끝나면 22/42가 됨. → T2하면 21/41이 됨.
- 따라서 2단계 : 로크 요청과 해지를 구분해야겠다
로크 요청이 로크 확장단계임. 이게 끝나야 로크 해제하는 수축단계가 올 수 있음.

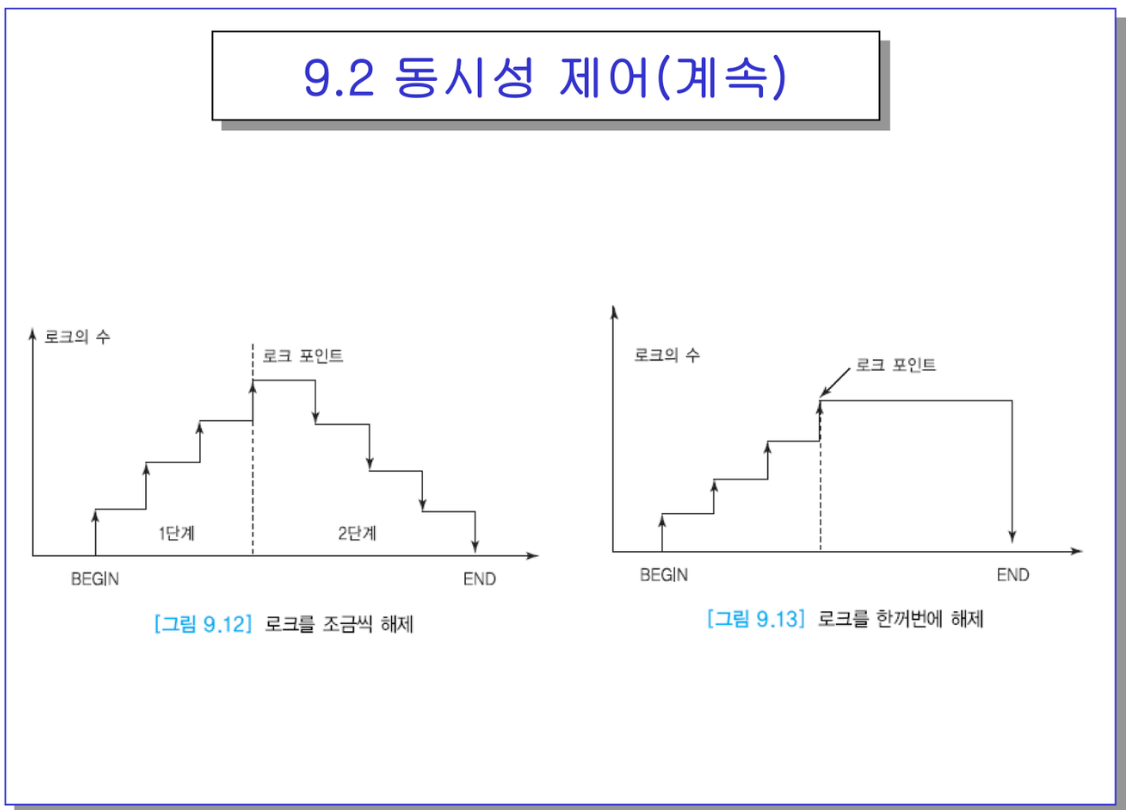
- 2단계 로킹 프로토콜은 이런식으로 두 단계로 구분함.
- 로크 확장단계 : 트랜잭션이 데이터 접근 전에 로크를 요청함. 단, 갖고 있는 로크를 하나라도 풀면 안됨.
- 로크 수축단계 : 아무렇게나 로크를 풀 순 있지만 새로운 로크를 요청할 순 없음
-> 로크를 다 확보한 시점(쩌 가운데)이 로크 포인트라고 함.
- A C D B → D A C B 이렇게 야금야금 풀어도 됨. 2PL(2Phase locking)인데,
→ 기다리던 트랜잭션이 그만큼 일찍 수행될 순 있지만, 항상 중간에 사용자나 시스템의 요청에 따라서 문제가 생기지. 중간에 만약에 죽였어. 그럼 트랜잭션이 끝까지 못갔으니까 원상태로 돌아가야함.
- 즉, 로크 푸는 중에 취소시키면, 그 전에 중간에 가져간 애들은 더티 데이터를 가져간 것.
→ 줄줄이 다 취소를 해야함 → 케스케이드 롤백이 발생.
- 따라서 한번에 확 풀자 하는걸 엄격한 2PL이라고 함.
업무 환경에서 어떻게하면 성능 높이는 데 도움이 될 것인가를 이해하면 좋다~

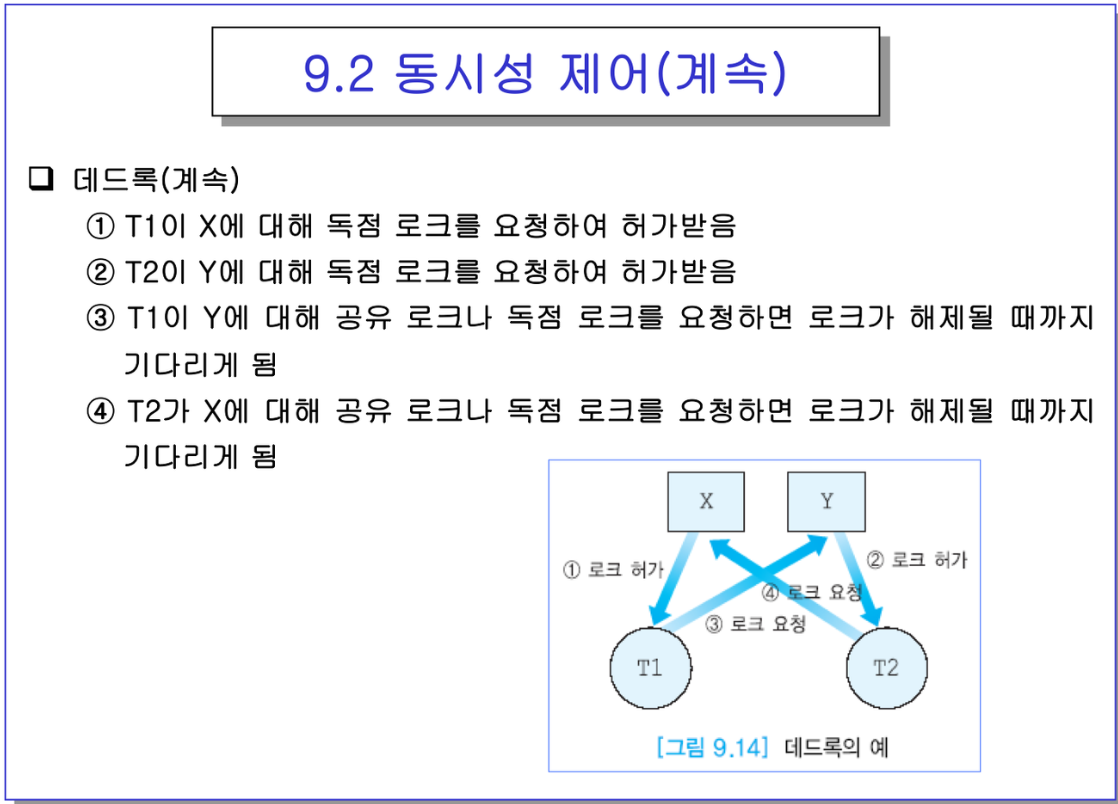
- 불행히도 동시성 제어로 로킹을 쓰게 되면, 데드록을 피할 수 없음
- 우측 이미지를 보면, 둘 다 필요한데 서로 양보하라고 하는 것.
어떻게 해결하지? -> 우선순위, 타임아웃해서 죽이기, 일이 길게 남은 애 죽이기 등.
- 피할 수가 없음 데드록 어보이던스, 데드록 프리벤션, 데드록 디텍션&레졸루션(얘는 데드록 허용)
→ 거의 모든 DBMS는 디텍션&레졸루션 이용 데드록 허용하고 발생하면 트랜잭션을 죽여 해소함.
→ DBMS에서 번호를 부여하는건 불가능하고, 자원을 미리 확보한다음(뱅커스 알고리즘) 수행하자 이것도 트랜잭션이 긴데, 얼마나 많은 데이터 항목을 요청할지를 비효율적(?) 불가능하다.
- 데드록이 발생할 필요충분조건 4가지
mutual exclusion : 독점 상호배제
hold and wait : 뭔가 갖고있고, 상대방이 가진걸 달라 그래야해. 지칠 때 까지 기다려야함. 트랜잭션은 생각이 없으니, 그냥 기다림.
no preemption : 쫓아내질 못한다. 뻇을 수 없다.
circular wait : 서로 기다리고 하는게 사이클이다(?)
→ 데드록 상태는 무한히 감. 냅두면 안되겠지. DBMS는 누군가를 희생자로 선정해야함.


SELECT AVG(BALANCE)
FROM ACCOUNT;
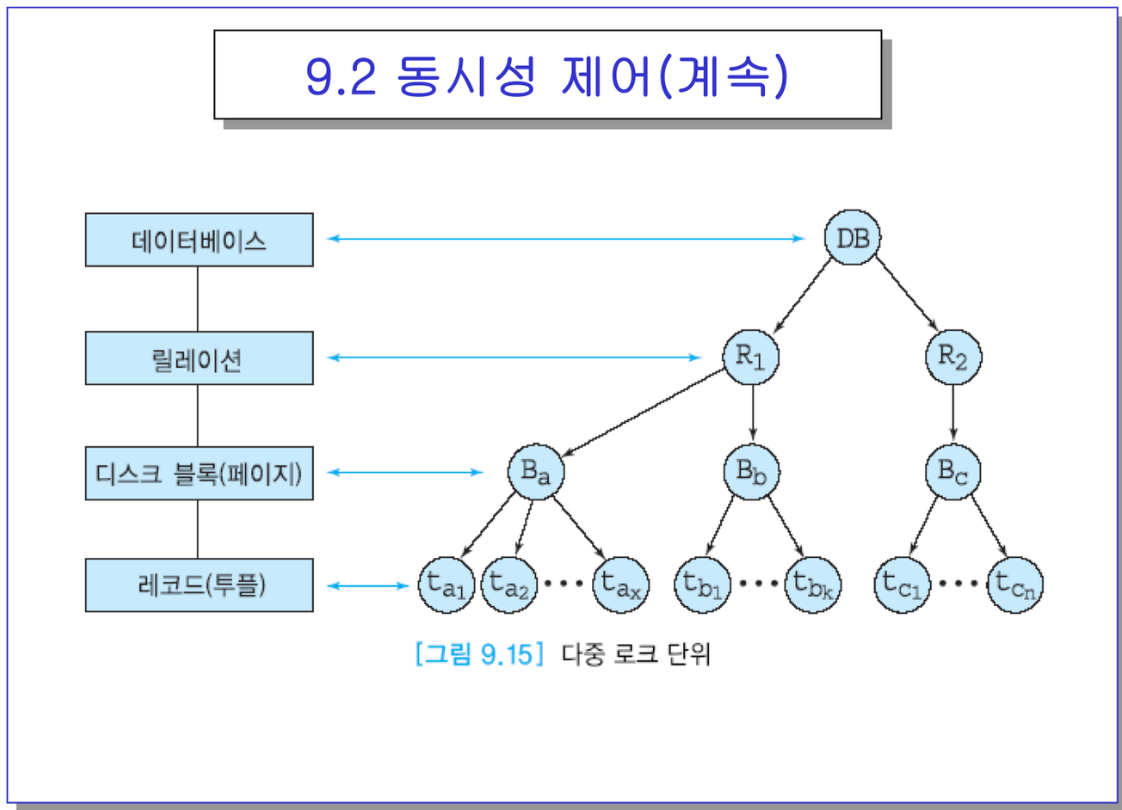
- 데이터 항목이 뭐냐. 블록이냐 테이블이냐 뭐 데이터베이스냐. 로크를 하는 단위를 정하진 않았는데 어떤 DBMS에서 로크 단위를 레코드로만 제한한다고 생각해보자.
- 어카운트 테이블에 레코드가 천만개쯤 잇다고 하면 읽을 때 마다 로크를 요청하면 로크 천만개를 하는거임.
- 레코드를 로크를 했을 떄 천만개의 로크레코드가 필요함. 하나의 길이가 4바이트라고만 해도 4천만. 40MB만큼의 공간이 필요해짐. 로크테이블은 주기억장치에 반드시 유지해야 하거든.
-> 그럼 좋은 방법이 뭐가 있을까? 테이블 자체에다 로크를 딱 거는거야.
- DBMS에서는 일반적으로 자동적으로 로크 단위를 조정함
→ 레코드 단위로 내려갈수록 동시에 사용할 수 있는 트랜잭션의 수는 늘어남. 동시성의 정도는 늘어남
최상단에 IS (Intension Share) IS → 저 아래서 공유 로크를 하려고 한다. / IX는 독점로크!
- ta1에서 S 걸려면, DB IS R1 IS Ba IS. 이런식으로 함.
- tb1에서 X 걸려면, DB IX R1 IX Bb IX.
→ Bb에서 S하려면, 충돌이 될 수 밖에 없지. 반대로 S해놨는데 IX하려고 해도 충돌.
이해하면 양립성 행렬(아까 위의 표)을 채우는데 큰 어려움은 없을 것.
SIX라는것도 도입되는데, 해당 레벨 공유로크를 걸면서 그 아랫단계 어딘가에 선별적으로 독점 로크를 걸 것이다.
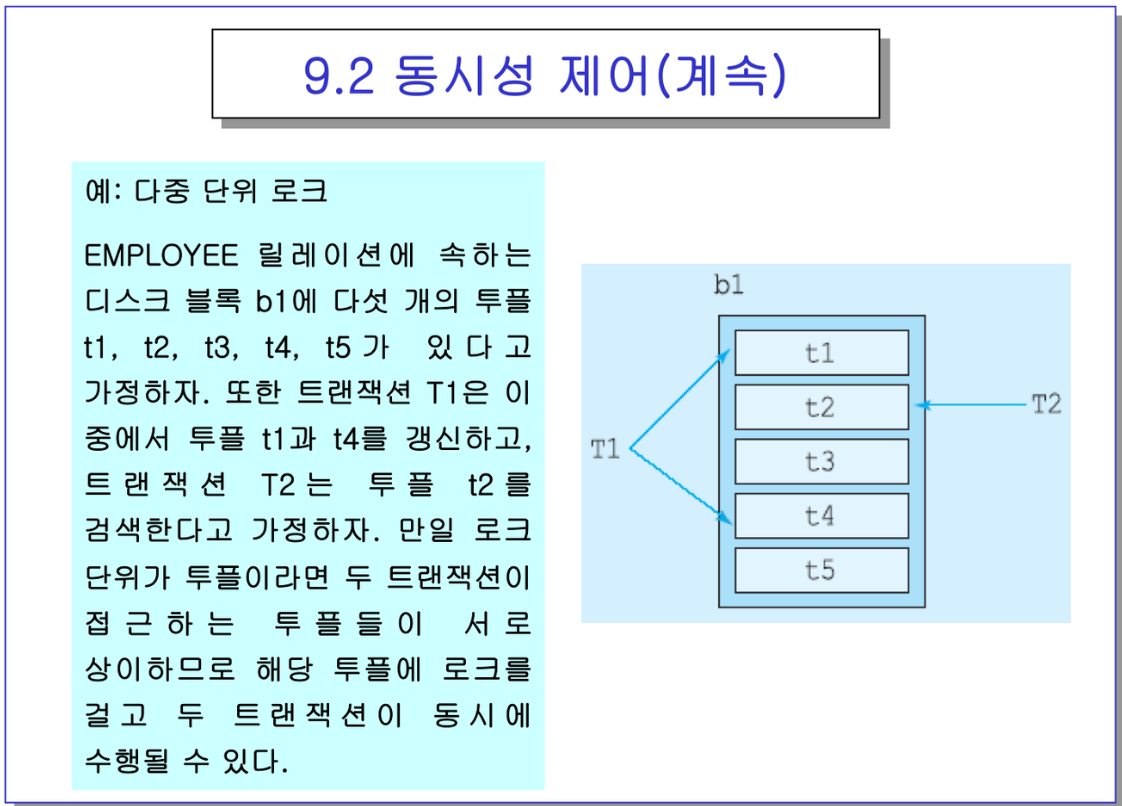
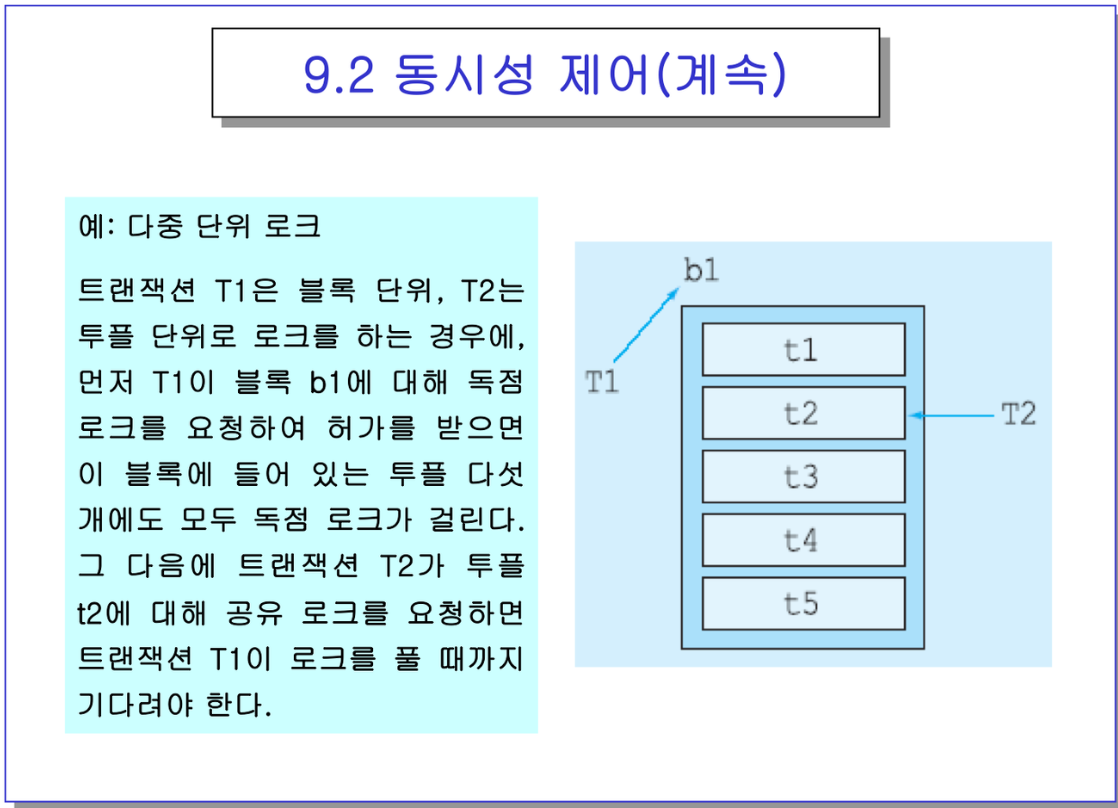
- 블록 b1에 투플 5개가 있는데, T1은 t1,t4 투플에 접근. 근데 T1이 레코드에 독점 로크를 요청한다?
-> 서로 접근하는 레코드들의 집합이 겹치지 않으니까 동시에 수행 가능.
- 그런데 이 T1은 블록단위로 로크를 하게되면, T2는 S든 X든 기다려야함.
-> 동시에 수행 할 수 있는 정도는 줄어듦


팬텀 문제
- 지금까지 우리가 본건 정적이라고 생각했음. 테이블에 들어있는 레코드 집합이 변하지 않는다.
- 시간1에서 1번 부서인 사람의 이름을 검색해 검색해서 사용자한테 보여주고, 1번이네 공유로크를 걸고.
-> T1이 이 시점에서 돌아갈 때 정희연이 없었음. 그럼 이 정희연을 로크하는건 불가능하겠지.
- 그러고 T2로 CPU가 넘어왔는데 이제 정희연 레코드를 인서트함. 없는 레코드에 대해서 1은 로크를 못거니까 새 레코드를 넣는건 아무 문제가 없음.
- 다시 T1으로 넘어오면, 이제 다시 임플로이 릴레이션을 읽으니까 정희연까지 공유 로크를 걸음.
-> 1에서는 박영권,김상언. 3에서는 정희연까지 3명.
-> 읽을 때 값이 달라졌지? 이게 도깨비라는 것. 중간에 인서트하는 레코드를 앞에서 보지 못하기때문에 이걸 팬텀현상이라고 함. 이걸 막는건 레코드 단위로 로킹을 해서는 불가능함.



- 수행 도중 일부 반영 : nothing → 어떻게 원자성?
- 완료 직후 다운시 모든 갱신 효과가 기록되지 않았을 수 있음 : all → 어떻게 지속성?
- 회복을 차츰차츰 : 바보(박응봉)
- 버퍼의 내용을 디스크에 기록하는걸 최대한 줄이자. -> 버퍼가 꽉찼거나 트랜잭션 완료했을 때 디스크에 기록하자.
if 버퍼에는 갱신사항을 다 반영했는데, 미처 기록되기전에 고장이 발생할 수 있음
-> 고장 전에 완료명령까지 했다면, 더 수행할게 남지 않았으니 죽었다 살아났을 때 갱신 사항을 재수행(다시 디스크에 기록) → ALL을 보장
-> 완료명령까지 도달하지 못했다. 근데 일부 반영을 했을지도 몰라 → UNDO


- 디스크와 같은 비휘발장치에 있는 내용은 물리적으로 망가지지 않는 한 다운되었다가 재기동되어도 데이터가 살아있음.
- 안전저장장치는 모든 유형의 고장을 견딜 수 있는 저장장치. 디스크 두개 쓰면 두개가 동시에 날아갈 가능성이 거의 없으니 안전 저장장치라고 함.
- 재해적고장은 디스크가 맛이간 것. 이런 고장으로부터 회복하려면 백업해놓은 자기테이프. 또 지진 화재 대비해서 다른 곳에 보관을 해야함.
- 비재해적 고장이 그 이외의 고장. 디스크는 살아있는 고장.
-> 여기서 회복 알고리즘이 적용된다!
ex) 로그를 생성하는 데 데이터베이스를 즉시 갱신, 로그 기반으로 한 지연 갱신(로그 기록하긴 하는데 메모리에 모아두다가 한꺼번에 반영), 그림자 페이징(IBM)
-> 대부분은 로그를 기반으로 한 즉시 갱신. 로그를 생성하면서 데이터베이스를 즉시즉시 갱신해나가는방식을 씀.

if 520명인데 320명까지 인상하고 DBMS가 죽었다!
- 520명 블록을 다 갖고있으면 좋은데 그게 안되면 디스크에 있는걸 버퍼로 읽어와서 모자라면 기록을 해야할 것 아니야. 근데 버퍼에 빈자리가 모자라면 앞에껄 내려보내야함.
- 이런걸 피하려고 하는게 지연갱신. 트랜잭션이 끝날때까지 모든 갱신사항을 버퍼 말고 로컬디스크에 따로 저장해놨다가 트랜잭션 끝나면 반영하자는건데.
-> 이중으로 write하니까 시간이 오래걸림.
- 즉시갱신에서는 이렇게하다가 트랜잭션이 완료되기 전이라도 버퍼가 모자라면 희생자로 선정이 되어서 디스크의 DB에 기록될 수 있음.
→ 철회될지도 모르는 트랜잭션의 결과도 반영될 수 있음.
- 그래서 원자성 지속성을 위해 로그라는 별도의 화일을. 다른 디스크에다 저장함.
모든 트랜잭션 연산들에 대해 로그 레코드를 기록함. 수많은 로그레코드들을 디스크에서 쭉 차례대로 저장
→ 로그레코드마다 순서번호를 dBMS가 부여하고, 한 트랜잭션에 속하는 로그레코드들은 링크로 연결.
새로운 DB상태로 바뀌는데. 회복 전엔 13p(쩌 위에 불일치상태
→ 새로운 DB로 바꾸면서 동시에 로그를 만들어내자! 로그는 각 항목의 값이 바뀐 역사를 기록하고 있음.

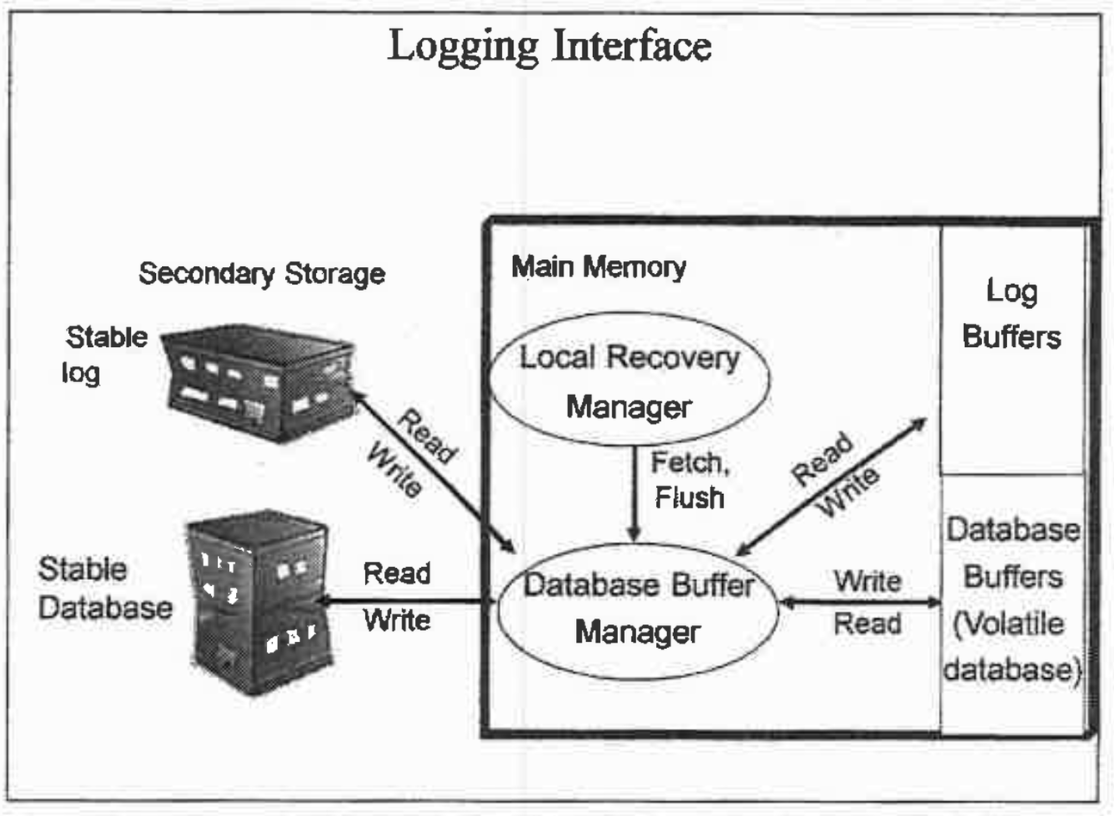
가져와서 읽어왔는데 메모리가 모자라다 → 누굴 디스크에 기록해야지.
내용이 어디서 어디로 바뀌었다 하는걸 로그로 별도로 기록하는 것.
→ 이후 로그 버퍼에 생성하다가 이제 다 차면 디스크에 로그로 기록하자. 즉, 로그에도 버퍼가 있다..
스테이블 DB. 로그는 두대의 디스크장치에 기록. 우측 버퍼에 빈자리가 없으면 내보내야지.
-> 그리고 바뀐내용들을 로그레코드로 로그버퍼에 기록하는데, 항상 로그를 먼저 기록해야함.
데이터가 디스크로 가기전에 버퍼가 먼저 가야함. OS는 이 관리를 못해서 DBMS가 버퍼 관리를 전담함.

- 로그버퍼가 꽉차면 얘도 디스크로 나가야하잖아 ? 두 대의 디스크 장치에 동시에 기록하는걸 듀얼 로깅이라고 함.
- 로그 레코드마다 여러 컬럼들이 있을텐데 그 중 하나에 트랜잭션ID를 포함.
- 동일 트랜잭션 로그레코드는 링크드리스트로 유지.



- 로그레코드가 차례대로 생성되는 것을 보자.
- DB버퍼 / 로그 버퍼 / T1 / T2 이렇게 있다고 하면,
-> 로그 스타트 하면 로그 1 생김.
-> T1의 5번째줄 write하면 이제 로그 2가 생김.
-> C읽고, 2배하고 write하면 이제 로그레코드 3이 생김.
-> 그러고 A가 결정되고 write하면 로그레코드 4가 생김.
-> 트랜잭션 마지막문장해서 로그레코드 5 커밋!
- 6번부터도 마찬가지로 write할 때 로그 레코드가 하나씩 생김.

스타트만 있는가, 커밋까지 있는가 → 1단계
마지막 지점에서 커밋이 없으면 완료되지 않았으니 역방향으로 undo를 하는 단계 → 2단계
다시 아래로 가서 커밋까지 된 것 REDO → 3단계
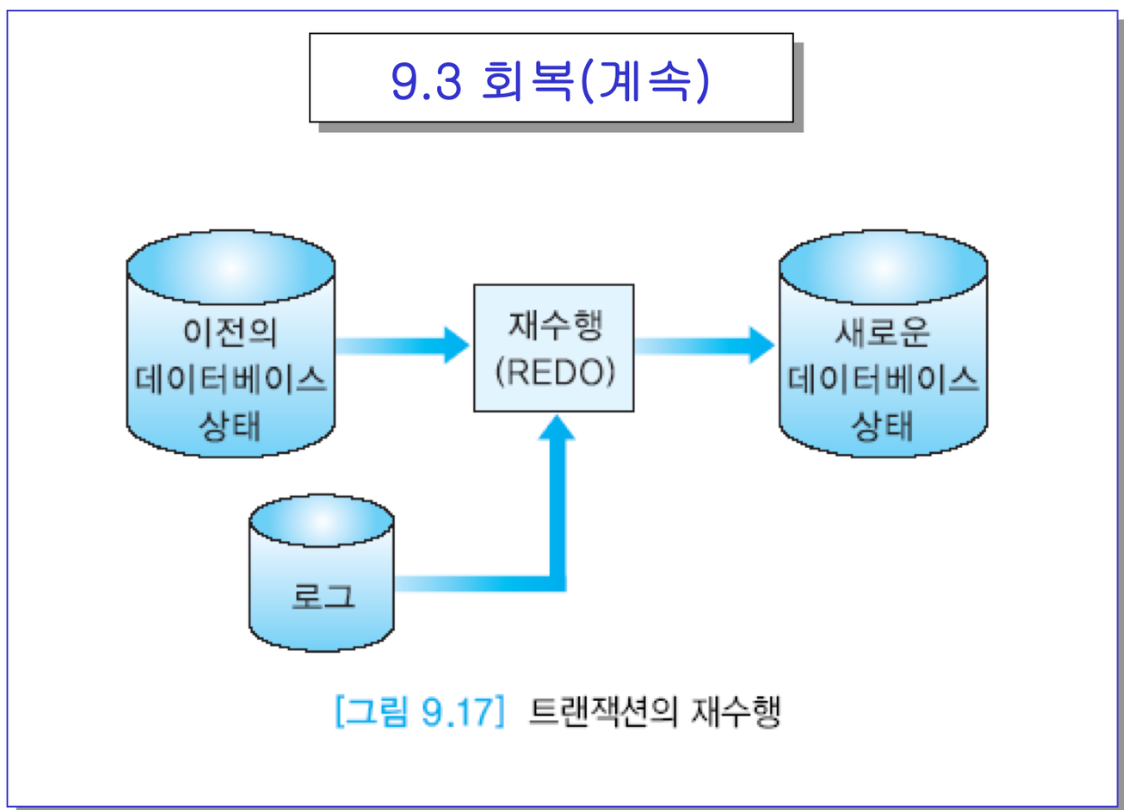
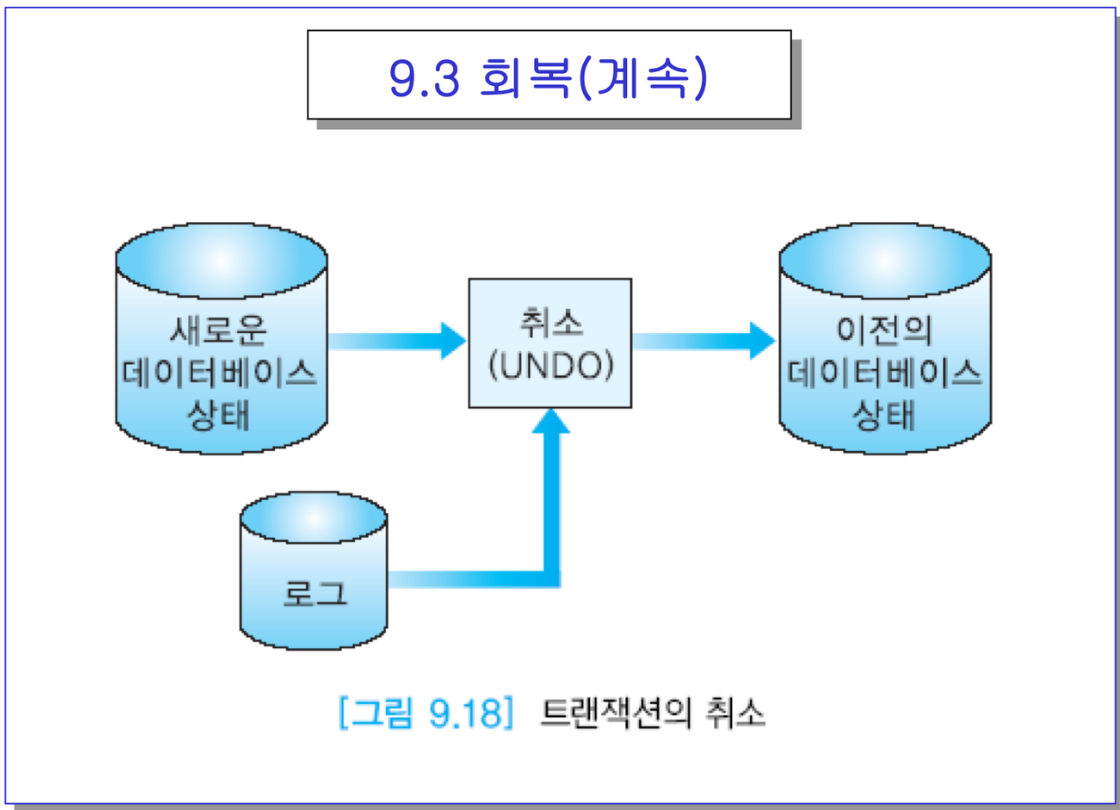
바로 앞의 케이스에서,
시스템이 언제든 예고없이 죽을 수 있지.
만일, 죽었다가 기계를 부팅 → DBMS가 데이터베이스의 원자성 지속성을 다 보장한다음에 사용자한테 감. 그래서 먼저 로그를 살펴봄.
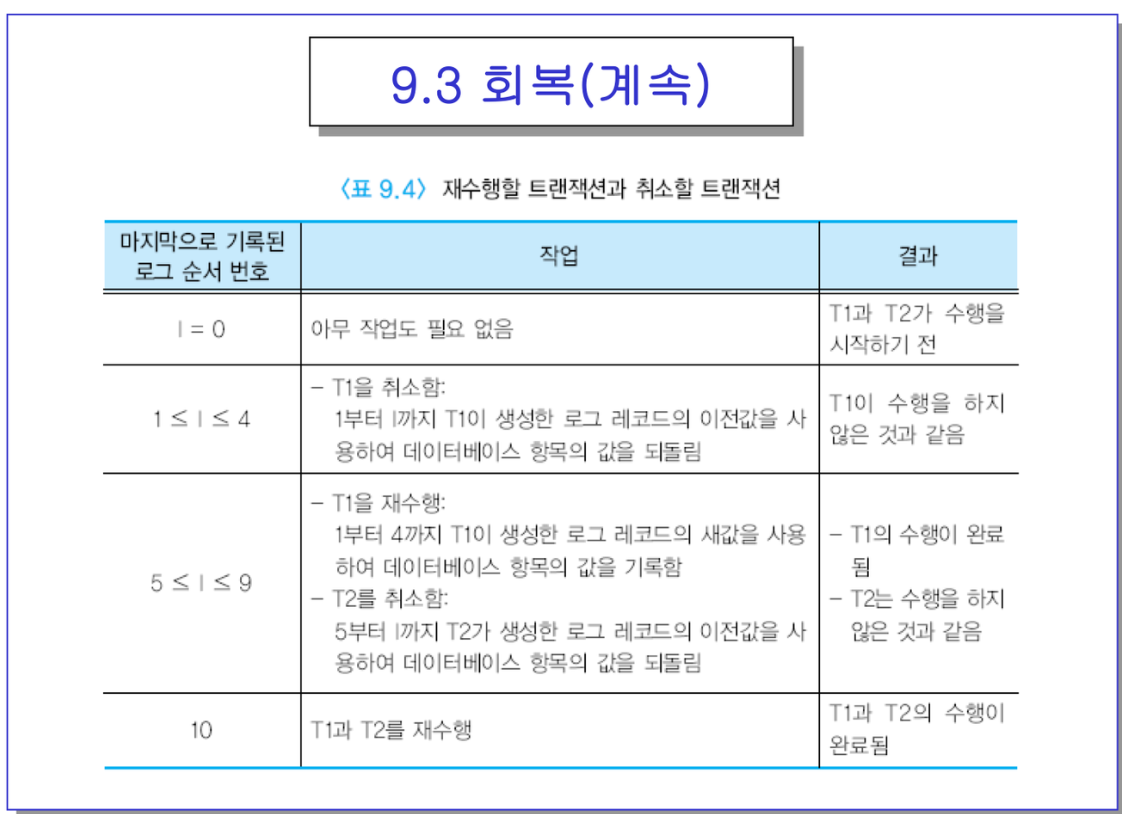
- 만일 로그가 0이면 그때는 로그레코드가 텅 빈것.
- 커밋 못한상태로 죽었다면, DBMS가 어디가 커밋인지 모르잖아. 수행을 다 안한 것. 그래서 취소함. 이전 값을 가지고 UNDO를 함.
- 근데 5번을 발견했거나, 그 이후라면. T1은 끝났구나! 근데 T2는 커밋이 없지. 그럼 T1을 redo(로그는 갔더라도 디비가 반영됐는지 디스크는 모르니까)를 하고, T2는 UNDO를 함.
- 10까지 갔다면 다 커밋 된거니까 둘다 REDO를 함.

- 로그 먼저쓰기는 굉장히 중요한 원칙. 모든 DBMS가 따르는 원칙.
-> 만일 DB버퍼가 로그버퍼보다 먼저 디스크에 기록되는 경우에는, 로그를 유지하는 의미가 하나도 없겠지.
- DB버퍼보다 로그버퍼를 먼저 디스크에 기록하자가 원칙!


- 어떤 트랜잭션이 디스크에 기록되었는지 구분할 수 없음. 아무튼 안전한 지점을 주기적으로 설정해야함.
즉, DB에 반영됐는지 안됐는지 확신할 수 없다. 로그나가고 DB나갔는지 안나갔는지 모른다!
→ 로그를 사용하더라도 갱신사항이 디스크에 기록됐는지를 구분할 수가 없다
→ 회복할 때 재수행 할 트랜잭션의 수를 줄이기 위해 주기적으로 체크포인트를 수행.
체크 포인트 수행하면 강제 기록
- 체크포인트를 할 때 수행중인 트랜잭션을 일시중지 → 사용자가 불편할것
-> 중지하지않고 다른 트랜잭션 수행되는 과정에 체크포인트 진행되는 알고리즘도 있음. 대부분이 이렇게함.
순서를 생각해보자면,
- 로그버퍼를 디스크에 강제로 write. 그리고 db버퍼를 디스크에 강제로 write
→ 다 끝나면 체크포인트했다는 로그레코드를 디스크에 강제로 내보냄
→ 회복모듈은 마지막 체크포인트 위치를 알고 있음. 만일 중지시켰다면 재개.

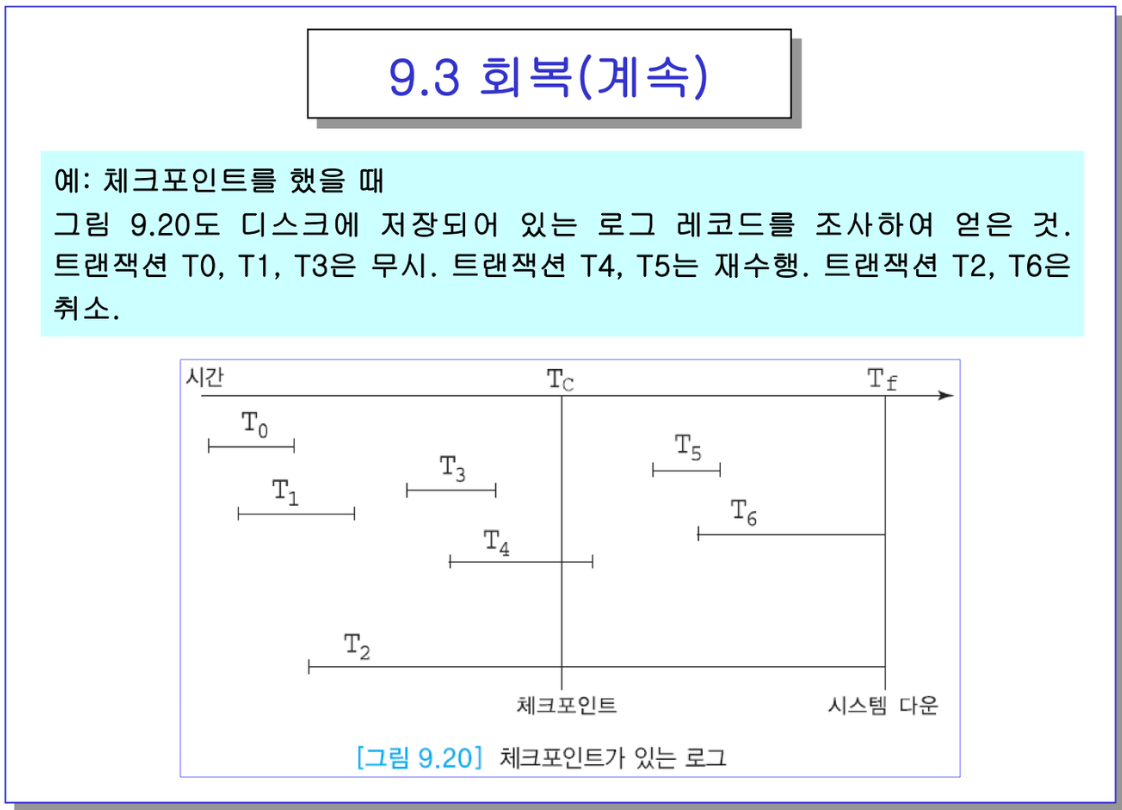
- 스타트는 있는데 커밋이 없는 T6,2는 되돌려줘야함. undo.
- 나머지는 커밋이 있으니 Redo해야함.
-> 근데 T0,1은 한참전에 수행을 마쳤으니 재수행을 안해도 될 수도 있음 → 이거때문에 체크포인트!
- Tc가 체크포인트 시점. 그럼 회복모듈은 가장 마지막 체크포인트 시점으로 감.
이 때 진행중이던 T4,2가 저장이 되어있음.
→ 그 전에 스타트하고 커밋했던건 이미 끝났으니 무시.
-> 이 시점부터 죽을 때 까지 분석을 해서 커밋을 만난 애들은 리두로 분류, 아닌애들은 언두
ex) 만약 Tf에서 죽었다면 T2,T6은 UNDO, T4,5는 커밋이 있으니 REDO
-> 똑같지만, T0,1,3을 신경쓰지 않아도 됨

재해적 고장은…. 전체db와 로그를 각각 백업받고 이 테이프를 별도의 건물. 공간에 안전히 보관.
점진적 백업이 바람직!


- 커밋 : 한개 이상의 데이터 조작어 결과를 디비에 모두 반영하고 현재 트랜잭션을 끝내라
- 롤백 : 은 트랜잭션에서 수행한 결과를 모두 되돌리고 nothing으로 만들어라.
- 세이브포인트 : 현재 트랜잭션 내에 특이점. 위치를 저장하고 트랜잭션을 나누는 것.
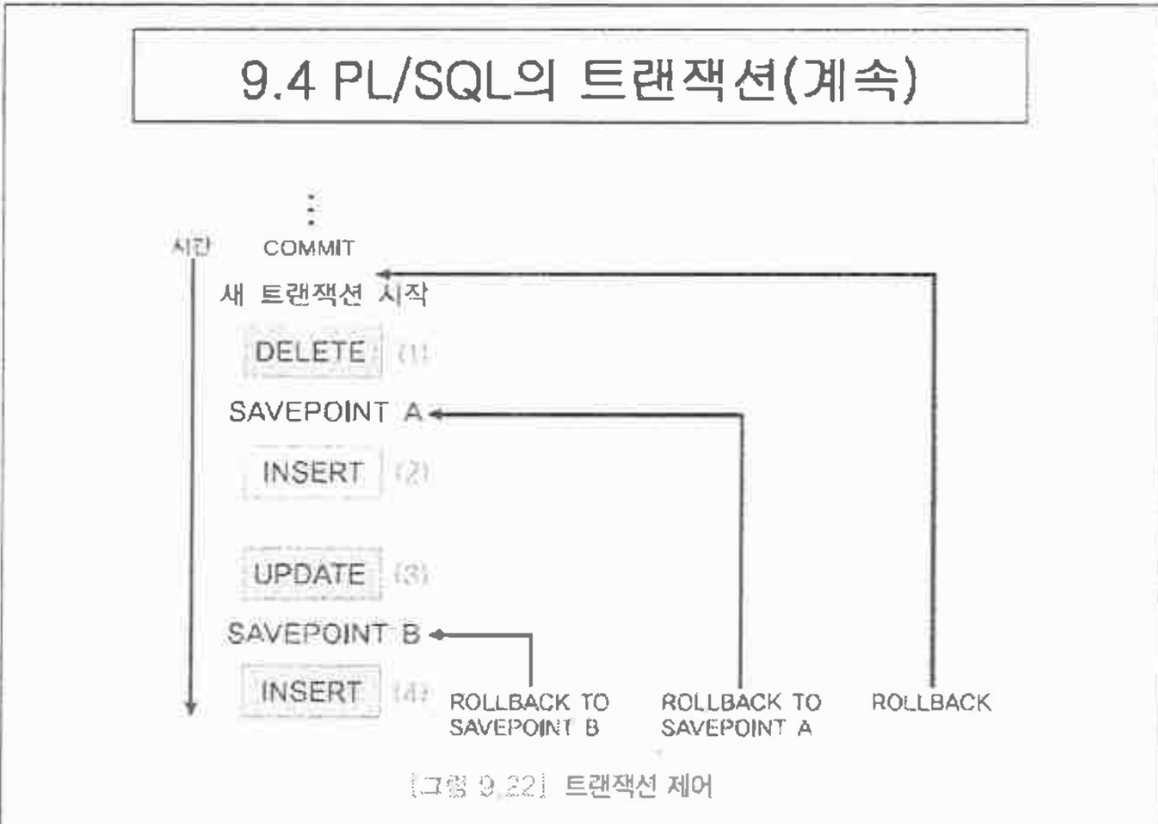
완전 처음으로 다 돌아가면 아쉽잖아. 전부 다 취소하는건 아깝다.
그래서 세이브포인트라는 키워드를 적절한곳에 넣음.

SQL*PLUS에서는 set 명령으로 각 데이터 조작어를 한 트랜잭션으로 처리할 수 있음
- 각 인서트 딜리트 이런걸 하나로 취급하고싶으면 set auto on;
-> 이걸 안하면 디폴트는 인서트 딜리트 여러개 입력했을 때 마지막 커밋이 들어오면 그걸 트랜잭션으로 취급함.

- DB환경에서 앱을 만든다. 트랜잭션의 범위를 잘 구분해서 특성에 맞도록 뭔가를 더 지정해서 성능을 높이고싶다.
-> 읽기만한다면 읽기전용을 명시하면 동시성의 정도를 높일 수 있음.

-> 그럼 이 설정이 되어있으면, UPDATE문은 수행을 못함! 읽기 전용이니까!

- READ에다가 WRITE까지 명시를 해주면 이제 갱신 가능!

- 고립수준은 모든 관계 DBMS가 따르는 표준안. 어느정도로 고립시켜야하는가를 나타냄.
4가지로 구분해서 명시.
- 낮으면 → 동시성은 높아지지만 데이터 정확성 일관성 떨어짐
- 높으면 → 데이터가 정확해지는데 동시성정도는 떨어짐
→ 응용 성격에 따라 허용가능한 고립수준을 적절히 선택하면 하드웨어 증설하지 않고도 DBMS성능을 향상시킬 수 있음.
고립 수준에 따라 로킹 동작이 달라짐. 팬텀 현상이 나올건지 안나올건지..
-쓰기 위한 데이터는 어떤 고립 수준을 따라도 똑같음


- READ UNCOMMITTED : 리드는 그냥 신경안쓰겠다 로크 안걸겠다! 갱신중인거 읽어도 상관없다
- 가장 낮음 → 트랜잭션에 포함된 실렉트문은 공유로크 안걸고 읽으니까 그 데이터를 다른 트랜잭션이 고치려고 로크를 요청해도 허가함. 내가 안걸었으니까.
-> 따라서 오손 = 때 묻은 데이터를 읽을수도 있음
- 갱신은 엄격한 2단계 로킹을 따름
- READ COMMITTED : 읽을 때 공유로크 요청해서 허가받으면 읽고 읽자말자 풀고 또 같은데이터 읽으려면 로크 요청.
-> 따라서 2단계 로킹을 안따르는 것. 동일한 데이터를 2번 읽을 때 서로 다른 값을 읽을 수 있다.
- 갱신은 엄격한 2단계 로킹을 따름
- 이게 오라클의 PL/SQL의 디폴트.


- REPEATABLE READ : 반복할 수 없는 읽기를 막겠다. 검색하는 데이터에대해 공유로크 걸고 트랜잭션 끝날 때 까지 보유!
- 독점로크까지 둘 다 엄격한 2단계 로킹 프로토콜을 따르겠다
- 한 트랜잭션 내에서 동일한 질의를 두 번 이상 수행해도 같은 값
- SERIALIZABLE : 가장 높은 케이스. 얘는 팬텀연산까지도 막아줌. SQL2에서 사용.
- 2단계 로킹에서 새로 들어오는 레코드에 대해서는 S록을 못하니까 얼마든지 레코드를 인서트 해서 이후에 검색하면 한 명이 더 나오고 그랬지?
-> 이걸 막으려면 전체 릴레이션에 s록 걸거나,
부서번호(외래키니까 인덱스가 있을 가능성이 높음)와 같은 인덱스에 로킹을 하자!
- 1번 부서에 새 레코드 들어가면 인덱스에도 반영이 되어야하는데 인덱스에서 이걸 막을 수 있음
- 근데 인덱스가 어떤 컬럼에 없으면 인덱스로킹을 적용할 수 없지
-> 그럼 릴레이션 전체에 로킹을 걸어야함.
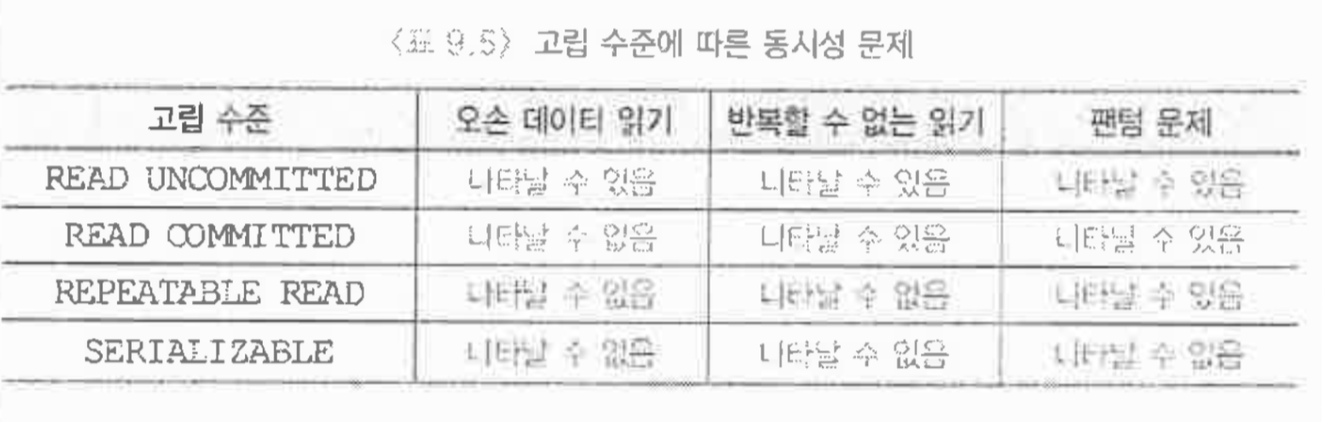
- 고립수준 정리하면 이렇게 된다!
'UOS > UOS@DB' 카테고리의 다른 글
| 8장 뷰와 시스템 카탈로그 (0) | 2023.12.16 |
|---|---|
| 7장 릴레이션 정규화 (0) | 2023.12.15 |
| 6장 물리적 DB 설계(버퍼,디스크,인덱스 등) (0) | 2023.12.07 |
| 5장 데이터베이스 설계와 ER모델(설계 사례 분석 및 릴레이션으로의 사상) (4) | 2023.12.03 |
| 5장 데이터베이스 설계와 ER모델(DB설계 개요, ER모델) (0) | 2023.11.27 |