

디렉토리 구현.


a 윈도우즈 : 엔트리에 파일이름 + 속성정보, 엔트리 단위 저장.
-> 아래 이미지 보면, First block number가 파일의 시작 데이터가 저장되어있는 블록번호를 저장한 것. 가운데 리저브드 영역도 이후 확장되면서 사용됨.
b 유닉스 : 파일이름, 아이노드번호 -> 아이노드에 속성정보와 인덱싱 정보 저장.
-> 파일 이름이 8+3이라 너무 짧아. 그래서 255바이트까지 확장 -> 엔트리가 커질 수 있어야 하여 가변 구조가 됨.

a : 디렉토리 안에 엔트리를 표현. 한 덩어리가 하나의 엔트리.
-> 파일1의 엔트리 길이 + 속성 + 파일 이름(4바이트씩 커짐, x는 null)+ 안쓰는 부분 회색.
이렇게 하다보니 안쓰여지는 공간이 존재. 그래서 b를 제시
b : 파일1의 이름 위치 + 속성, 파일2의 이름 위치 + 속성 이런식으로 기록.
디렉토리 엔트리는 메모리에 구축한 후 블록 단위로 디스크에 씀. -> 굳이 이렇게까지? 해서 a가 쓰입니다.

문제가 되는건 최하층에 ? 파일이 공유파일. c가 만들었고, B에게 공유를 해줌.
이걸 공유하려면 아이노드 번호만 공유해주면 됨. 어떻게? 이 아이노드에 대한 링크.
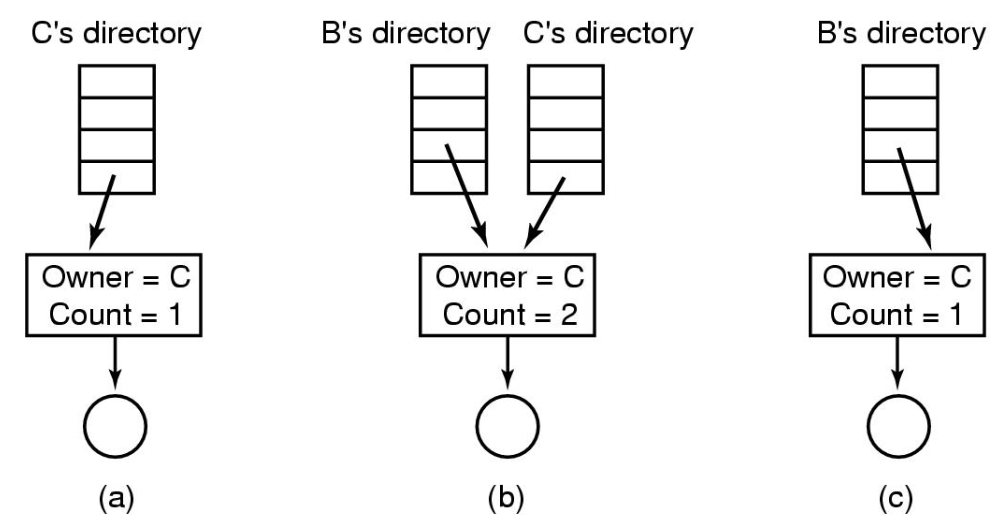
C사용자의 디렉토리를 보면 엔트리가 있지. 오너는 C고 레퍼 카운트가 1. 아이노드를 가리키고 있어.
이 사용자가 링크 시스템 콜을 통해 파일 공유 -> B의 디렉토리 엔트리를 보면 같은 아이노드를 가리킴. 오너는 C이지만 카운트가 2. -> C가 파일 삭제함. 그럼 B의 디렉토리에 오너는 C인데 카운트는 1 남아있지. 심각한 오류(무한반복- ls로 디렉토리 쫓아가는게 반복, 할당량만큼 비용 청구된다면 C는 억울하게 비용지불).
1. 따라서 횟수 제한을 둠(하드링크)
2. 심볼릭 링크 -> 바로가기파일과 같음. 링크의 데이터블록에 path name이 있어서 이를 쫓아가서 파일에 접근.
-> 추가적인 오버헤드가 필요하여 속도는 느리지만 보안에서 좋음.
--
FAT나 UNIX나 기존엔 데이터의 위치가 고정. 그 위치에 그대로 업데이트 하는것을 inplace update라고 함.
-> 오래 쓰다 보면 파일 시스템이 aging되면서 성능 하락 : 단편화로 인해 랜덤하게 블록들을 읽어야 하니까.
이를 해결해주는게 로그 스트럭쳐드 파일 시스템(LFS)
디스크를 로그로 생각. 메모리에 변경된 데이터를 모은 후 한번에 크게크게 로그의 부분집합인 세그먼트 단위로 쭉 작성
-> write성능 좋아짐. 그러나 데이터의 양이 많아지고, 유닉스는 inode번호가 고정되어있는데, 파일에 변경된 데이터를 붙이게 되면 아이노드 위치가 바뀌고, inode map(아이노드 번호와 위치정보가 들어있는 테이블)을 다시 써야함.
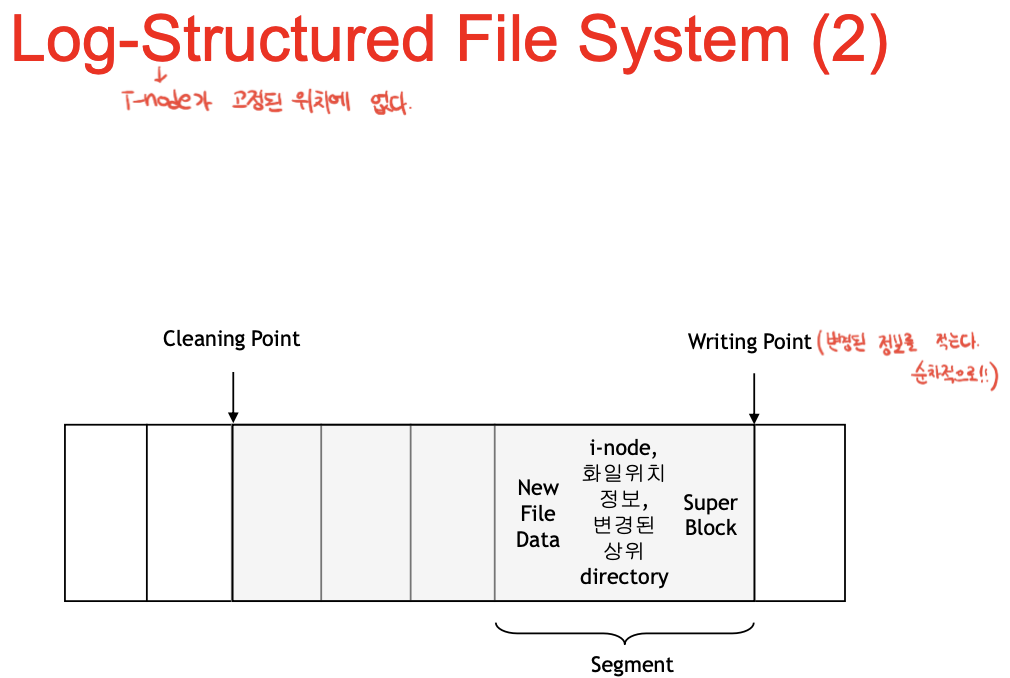
한 칸이 로그, 세그먼트의 집합으로 구성됨. 뭐 아이노드(뒤에 주기적으로 inode map써야겠지?), 위치정보, 새 데이터, 슈퍼블록 등등. 그럼 그 다음위치가 또 writing point가 됨. 순차적으로 변경된 데이터들을 뒤에다 기록하다 보면, 앞쪽에 이빨이 빠지게 됨.
-> valid한 걸 뒤로 옮기고, 클리닝 된 영역을 다시 로그 영역으로 사용. 다른말로 가비지 콜렉션.

LFS보면 아이노드 맵에, 칸으로 나뉘어져서 아이노드 번호를 인덱스로 사용. 위치(로그의)가 쓰여져 있음.
아이노드 맵을 통해서 아이노드가 실제 위치한 부분을 읽어서 파일을 오픈.
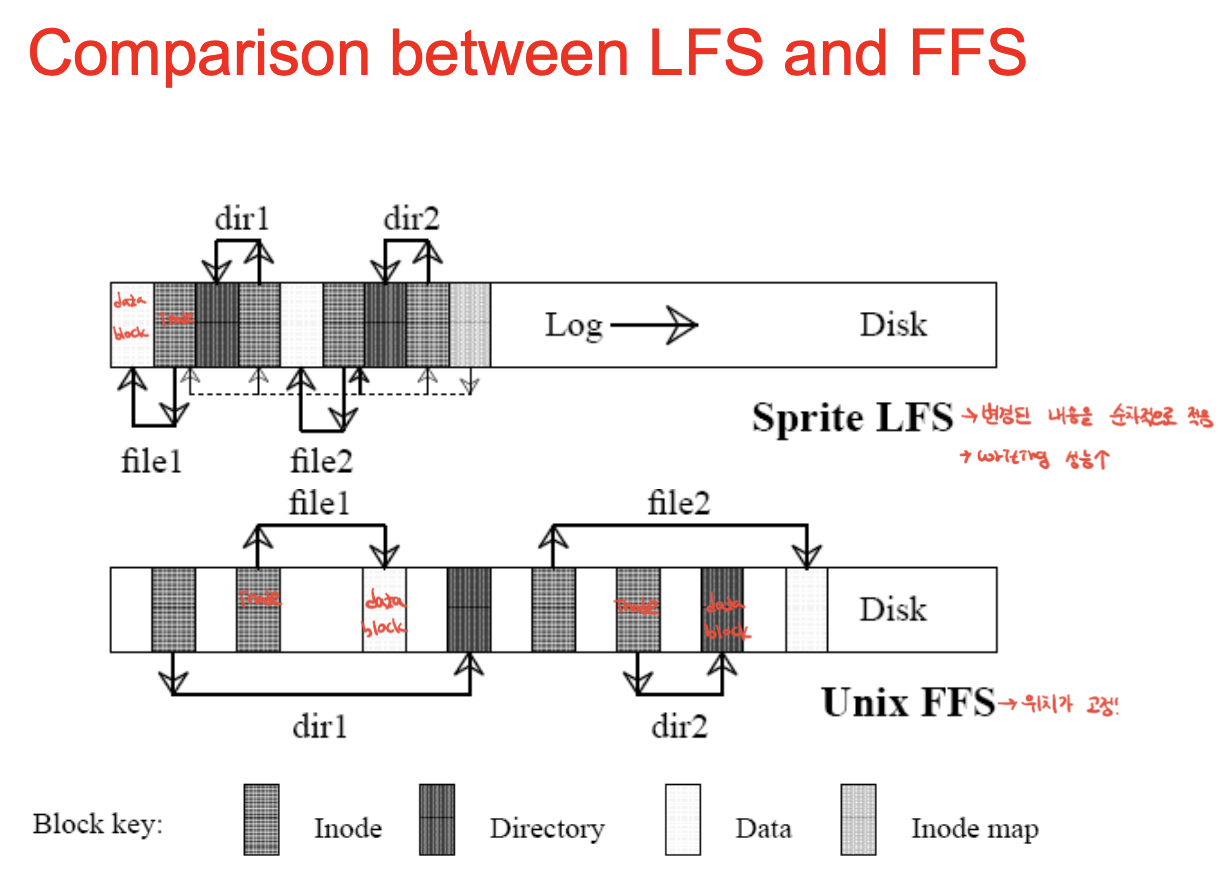
색과 패턴에 따라 구분할 수 있음.
FFS는 dir1이 새로 만들어지면 아이노드 변경 BUT 제자리에 씀 : inplace update. 아이노드는 바뀌지만 그 위치에.
LFS는 파일1의 데이터블록 쓰고 뒤에 아이노드를 씀. 파일1의 dir이 바뀌면, dir에 대한 inode도 바뀌어야함.
그리고 파일2번 바꾸면 파일2번 아이노드, 디렉토리 2번 바꾸면 걔의 아이노드도 써야함. 맵도 써야겠지.
-> 아무튼 계속 변경된 부분을 이어서 쓰는겐 LFS.

쭉 변경된 데이터를 써나가고, valid한건 뒤로 복사함.
Obsolete blocks이 필요 없기 때문에 삭제해도 됨 -> 빈 로그로 만드는 것이 클리닝(가비지컬렉션)
복사를 많이 하니까 비용상승. valid한게 많아질수록(디스크를 많이 쓸 수록) 성능이 다운.
-> 쓰이지 않았으나 ,ssd의 경우 태초에 물리적으로 블록 단위로 크게크게 써서 lfs효율이 좋음. ext, xfs의 기반.
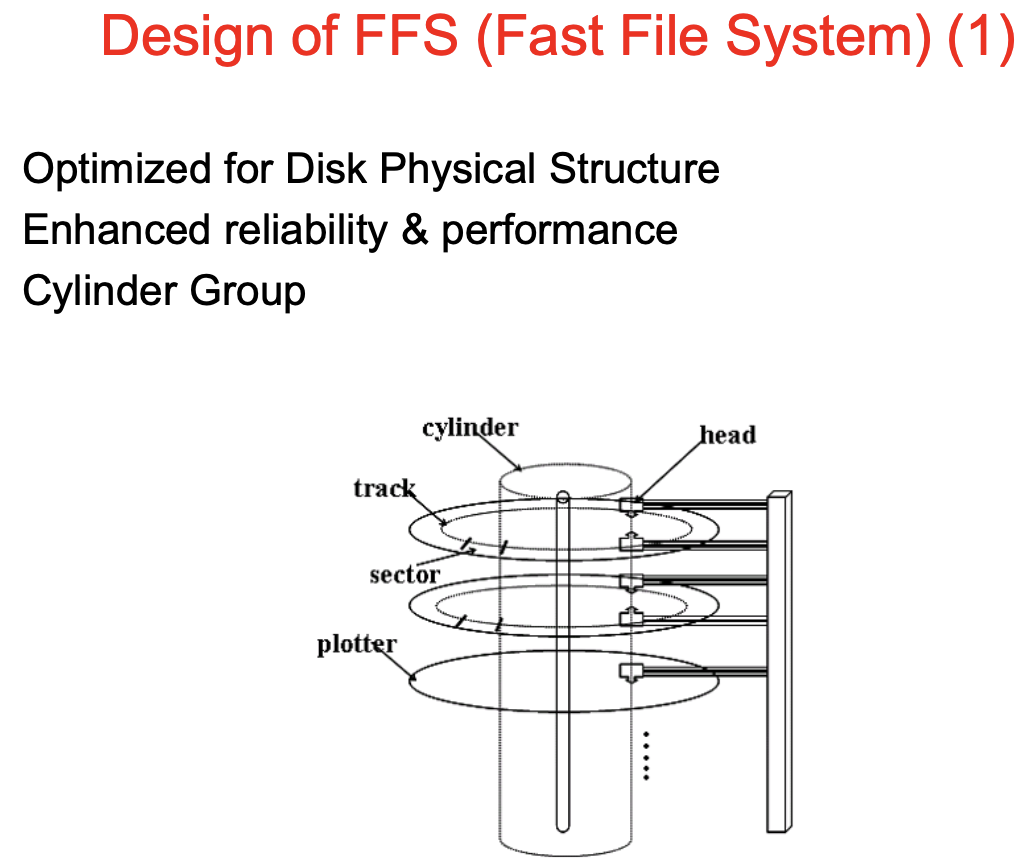
플로터 : 디스크의 원판(양면) -> 섹터 단위로 데이터를 기록
트랙 : 이 원판을 동일한 지름의 트랙으로 나누고, 이 트랙을 일정한 크기로 나눈게 섹터가 됨.
섹터 : 512byte, 너무 작아서 2,4,8,16개씩 묶어서 I/O를 함.
읽기 동작 : 헤더를 해당 트랙으로 이동시킨 후디스크를 회전시켜서 섹터를 읽고, 디스크의 메모리로 이동 -> 그 데이터를 dRAM(시스템 메모리)으로 옮김.
-> 해당 트랙으로의 헤더 이동시간(seek time) + 섹터가 헤드 밑까지 오도록 플로터가 회전하는 시간(rotation delay) + 데이터 꺼낼 때 걸리는 시간(transfer time).
실린더 : 디스크 암에 헤더가 여러개 달려 있고, 헤더가 동시에 이동해야 하기 때문에, 한번에 읽을 수 있는 각 원판의 트랙 집합.
실린더 그룹 : 헤드가 조금만 움직이면서 읽을 수 있는 인접한 트랙 집합이 실린더 그룹.

fat chain(fat system)은 fat 엔트리의 크기에 따라 전체 파티션의 크기가 결정.
블록사이즈 * 엔트리 비트가 전체 파티션의 크기가 되겠지.
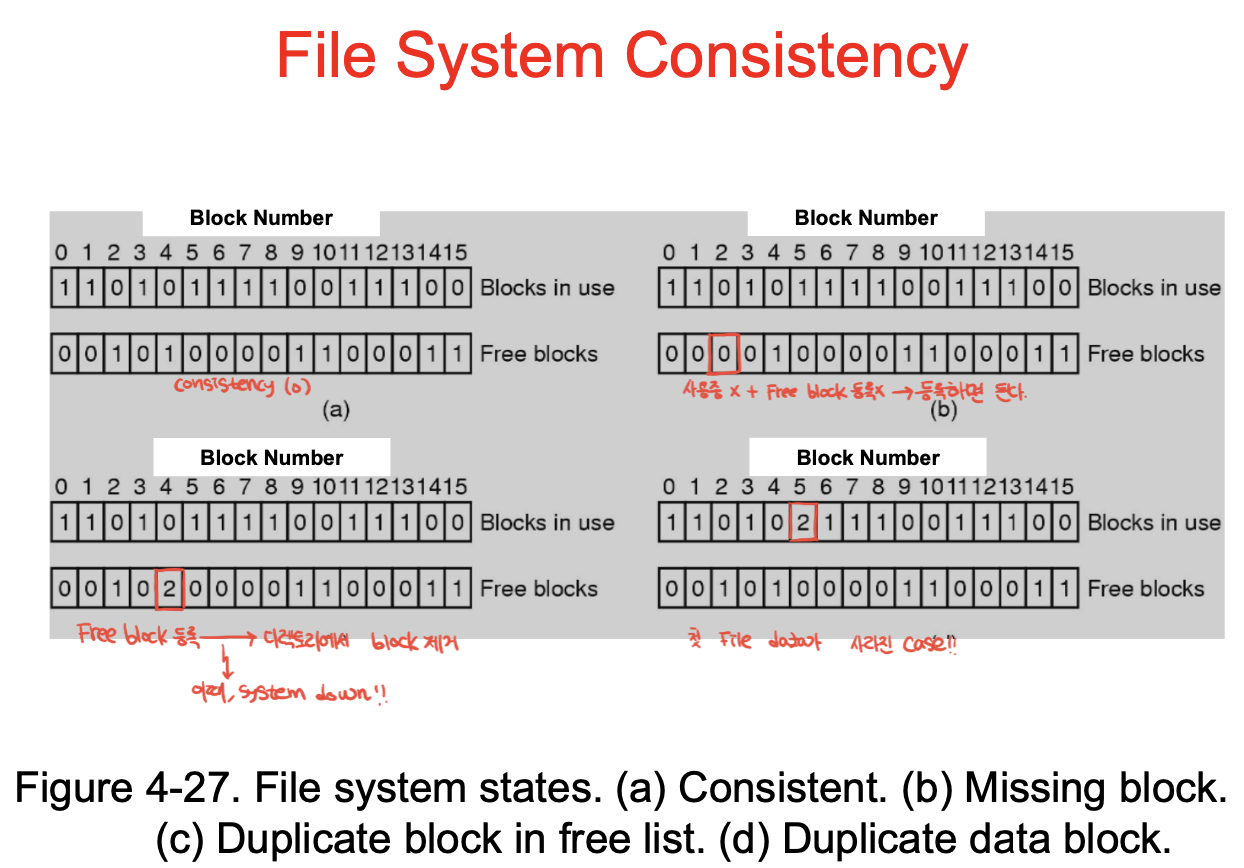
file system consistency.
파일 생성 삭제가 atomic하게 동작해야함. -> 원자적이지 못하면 시스템 일관성이 깨짐.
삭제 도중 시스템이 꺼지면, 블록을 사용 못할 수도 있고, 데이터가 남아있어서 덮어져 쓰일 수도 있고..
재부팅해서 복구 해야지. fsck나 scandisk가 제공되는데, 껏다가 켜지면 체크를 해서 일관성 회복(데이터 체크)을 하게 됨. 시간이 오래걸림.
b : 사용하지않는 블록인데 프리블록 등록이 안됨 -> 만들다 꺼져서 프리블록리스트에서는 블록할당했다 했는데 파일메타데이터엔 안씀 -> 프리블록을 1로 만들어서 빈거다 알려주면 일관성 회복
c : 다른 파일 각자가 프리블록이라 인식하여 동일한 블록들 두 번 써서, 다른 파일이 하나의 블록을 공유 -> 1로 바꿔서 일관성 회복
d : 동일한 블록에 데이터를 두 번 써서 데이터 하나가 사라짐
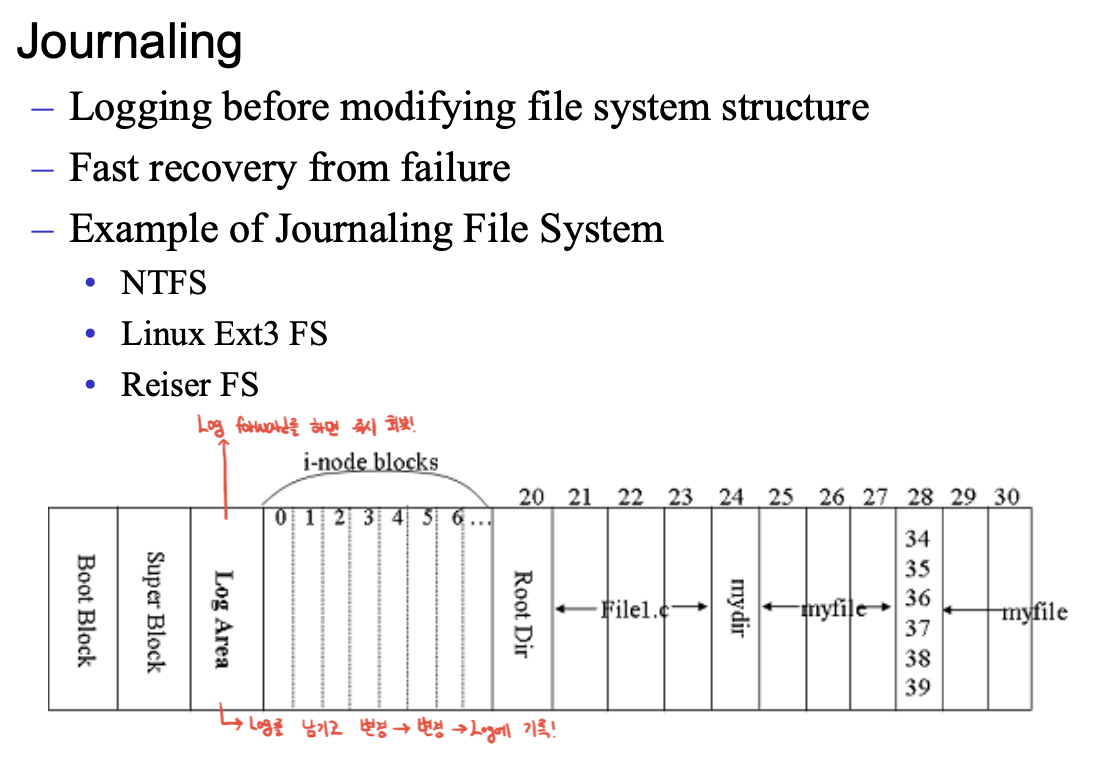
일관성 회복(복구)의 대표적인게 Journaling file system.
로그 에어리어가 있는데, 삭제와 같은 연산 전 로그를 남김. 부팅시 로그를 통해서 파일 시스템이 인식.
그럼 중단된 작업을 redo나 undo하면 일관성 복구.
---
파일시스템의 포매팅을 할 때 결정해야 하는것 : 블록size
블록을 크게 하면 순차읽기쓰기 효율적 -> 성능 up, 관리할 개수가 줄어 오버헤드 down
BUT 파일보다 블록이 커서 공간낭비
블록을 작게 하면 파일사이즈에 딱 맞게 블록 사용 -> 공간 효율 up
BUT 파일사이즈가 크면서 블록이 다른 실린더에 있으면 헤드의 움직임 up -> 성능 down, 관리 개수 늘어 오버헤드 up
대부부 파일 크기가 작음. 4krl준으로 8이나 16도 씀. FAT는 엔트리 개수 제한 떄문에 32k쓰기도 함.

모든 파일이 4k. 블록크기를 1k하면 공간사용률은 100%겠지. 근데 8k되면 50%.
-> 블록 사이즈가 커질스록 disk space utilization이 떨어지고, 성능은 좋아짐.
교차지점이 32. 너무 크기 때문에 4, 8정도. 성능을 중시하면 16정도.
빈 블록 관리하는 방법

1. 비트맵 : 블록 하나당 하나의 비트 할당하여 사용여부 표시 -> 작고 연속된 빈 블록 빨리 찾을 수 있음.
오버헤드를 살펴보면 블록크기를 4k라 했을 때, 디스크 사이즈가 1gb. 나누면 2^18개의 bit -> 32kb로 표시 가능
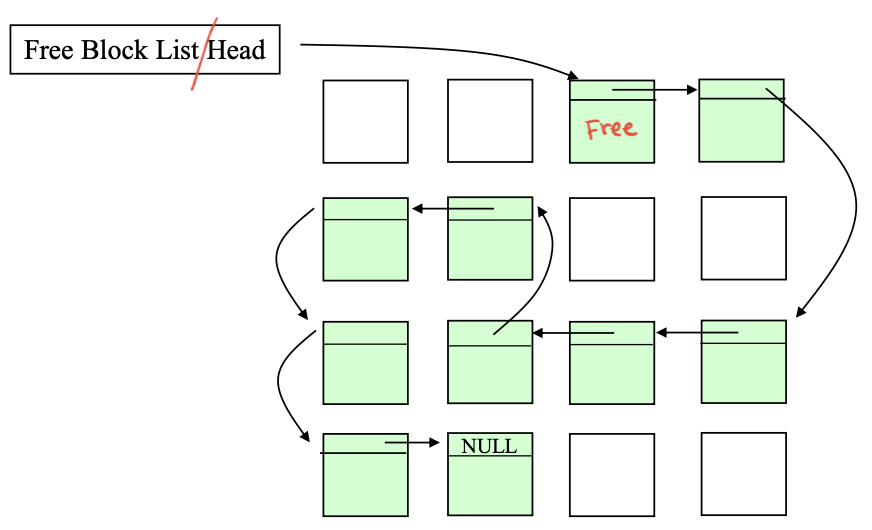
2. 연결리스트 : 빈 블록을 체인으로 연결. 할당과 해제 비용 high
슈퍼블록 같은 곳에서 free block list의 head를 갖고 있음 -> 여기서부터 체인 형태의 유지.
슈퍼블록을 바꾸려면 체인을 옮기고, 할당해야하고, 또 그럼 메타데이터에쓰고 파일데이터에도 써야함. 비효율적.
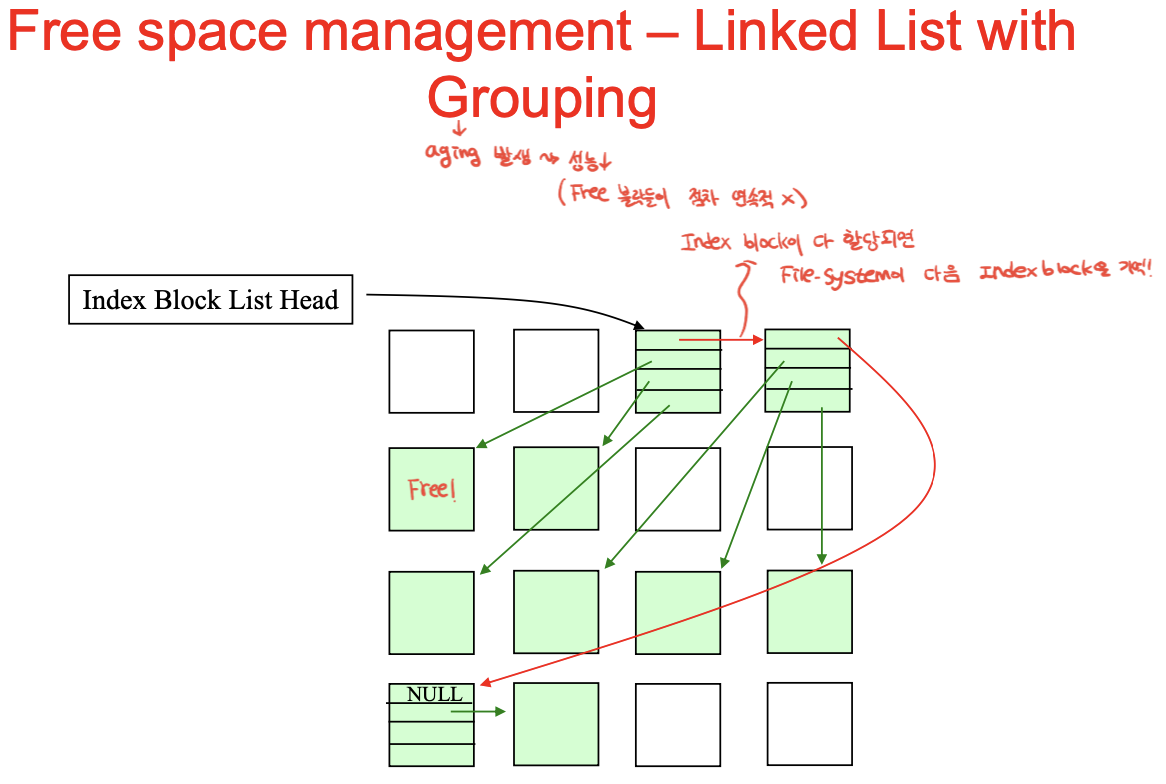
3. 그루핑 : 블록에다가 빈 블록 번호 쭉 적어놓고, 이 인덱스블록들을 할당하여 체인으로 연결.
인덱스 블록들이 프리블록들을 가리키게 함. 모자라면 다음 인덱스블록 놓고 또 가리키고.
한 블록이 다 채워질 때 쯤 경계조건에서 인덱스블록을 읽고 쓰는 동작이 많이 일어남. -> 반만 채워서 쓰자 뭐 이런 아이디어도 있었음.
-> 부팅할 때 FAT 엔트리 쭉 읽고 비트맵을 만들어 두는 것이 가장 효율적.
---
디스크 쿼타 : 중대형 컴퓨터 공유. 오픈 파일 테이블에 쿼터테이블을 가리키는 포인터 연결
-> 소프트 리밋 : 경고, 하드 리밋 : 할당 제한.
---
백업 파일 방법
1. 물리적인 백업 : physical dump : 디스크 그대로 뜨는 것.
2-1 논리적인백업-complete : 파일단위로 모든 파일 백업
2-2 논리적인백업-incremental : 변경된 파일만 백업
-> 일정 주기로 컴플리트 덤프하면서 그 사이에는 인크리멘탈.


디렉토리 구조 백업 -> 변경된 파일 백업.
a : 변경된 파일 + 모든 디렉토리의 아이노드번호에 해당하는 비트맵 정보 1로 세팅.
b : 변경된 파일이 없는 디렉토리 제거(0) : 이제 백업 준비 완료
c : 디렉토리 먼저 백업(dump) - 파일 덤프 하려면 어짜피 디렉토리 덤프 해야함 // 회색이 변경된 부분이니까, 폴더 부분이 변경되었다는 것.
d : file 백업(dump) // 파일 부분이 변경되었다는 것.
logical dump에서 고려해야 할 것
1. 링크 : 여러개면 덤프도 여러개 되니까 카운트를 통해 확인.
2. hole 파일 : 빈 부분 빼고 백업
안나올듯?
파일시스템 성능향상방안
1. 캐싱 : 작업중인 블록을 메모리에. 변경된부분 바로 기록하면 라이트 쓰루, 메모리에 유지하고 나중에 기록하면 라이트 백.

블록이 참조되면 제일 앞 MRU로 이동. 해시테이블에 없으면 가장 오래된 것을 제거, 새 것을 해시를 연결.
순차참조(ex.동영상파일) : MRU부터 동영상 데이터블록으로 채워져 있으면 나중에 사용될 해시 데이터가 다 쓸려나가버림 -> sweep
따라서 순차참조를 인식하면 얘는 lru에 위치하여 참조하고 바로 빠지게 됨.
2.리드어헤드 : 영상 같은거 미리 읽어들이는 것 -> 잘못예측하면 손실.

실린더 그룹에 같이 참조되는 그룹들을 배치하면 헤드의 움직임 최소화 가능
그룹 디스크립터 : 그룹 내의 정보
블록 비트맵 : 데이터 블록에 대해 사용중인 것 표시
아이노드 비트맵 : 아이노드 사용중인 것 표시
-> 디렉토리를 실린더 그룹에 만들고, 파일을 만들면 파일 읽을때 디렉토리부터 읽어야 하는데 헤더의 움직임이 줄어듦.

b처럼 실린더 그룹별로 아이노드와 뭐 이런저런 블록을 가짐
-> 헤드를 많이 움직이지 않아도 필요한 데이터 read 가능. 이렇게 한게 ffs.
유닉스 ext 2 : ffs, ext 3 : 저널링, ext 4 : 블록 인덱싱.
cd롬 : ms가 주도 -> 유닉스 속성을 쓸 수가 없어 ! -> rock ridgge extensions : 긴파일이름 지원, 디렉토리 depth 깊게, 유니코드 추가,, -> 더 확장한게 joliet
엑세스 컨트롤 매트릭스 : 행렬 복잡해 -> 액세스 컨트롤 리스트 : 파일마다 저장 -> 아이노드.
권한은 파일 오픈 시점에 적용.
'UOS > UOS@운영체제' 카테고리의 다른 글
| [운영체제] 5. I/O(입출력) - 2 (0) | 2023.06.14 |
|---|---|
| [운영체제] 5. I/O(입출력) - 1 (0) | 2023.06.14 |
| [운영체제] 4. 파일시스템 (0) | 2023.06.10 |
| [운영체제] 3. 메모리 관리(6/6) segmentation~ (0) | 2023.05.19 |
| [운영체제] 3. 메모리 관리(5/5) (0) | 2023.04.24 |