


long-term information storage(저장장치)의 특징
1. 굉장히 크다 -> 큰 파일들을 저장할 수 있어야 함
2. 프로세스는 실행중에 파일을 오픈해서 읽거나 저장하는데 이 데이터가 잘 유지되고 있어야 함(비휘발성)
3. 여러 프로로세스가 동시에 접근할 수 있어야 함(선택적)
파일 시스템은 디스크를 고정된 크기의 block들이 순서대로 나열된 것으로 생각(BUT 실제로 원판이 순서대로 나열되어있지 않음.)
0번부터 n-1번까지 순서대로 읽는 장치로 생각하여 블록에 대한 read/write를 지원해줌.
따라서 내부에는 컨트롤러가 존재(ex.하드디스크 컨트롤러 != 운영체제 컨트롤러)
-> 운영체제, 호스트에서 요청한 블록번호를 원판의 위치로 변환하고 데이터를 read/write함.
-> 파일 시스템이 디스크를 연속된 블록으로 추상화, 추상화된 디스크에서 블록번호를 기준으로 파일시스템이 데이터를 read/write
이 파일 시스템에는 3가지 동작을 함.
1. 파일을 추상화 -> 정보 저장의 기본 단위가 파일, 파일 단위로 읽고 쓰고 파일을 찾을 땐 이름으로 찾음
2. 엑세스 컨트롤 -> 다른 사용자의 접근 혀용 여부 결정. 생성 시점의 파일 owner가 결정
3. 빈 공간 관리 -> 파일 시스템이 사용하지 않는 블록을 새 파일에게 나눠주고 하는 것.
+
- 파일은 바이트의 배열. 프로그래머는 byte단위로 읽고 쓰지만 실제 디스크에는 block단위로 작업.
- 파일은 유저에 의해 하나의 개체(파일단위로 연산)로서 실행되고, 파일마다 unique한 path name을 가짐.
-> 파일 이름은 중복될 수 있으나 경로를 포함한 path name은 중복 불가
-파일 시스템 : 운영체제의 계정을 갖고 있는 어플리케이션(프로그램)이 파일을 사용할 수 있도록 제공하는 시스템소프트웨어
msdos의 파일 시스템 : fat-> 이름8글자 확장자3글자 -> 편하네? 글자수 제한은 안두지만 형식 유지(전형적인 file extention이 생김)

파일시스템은 확장자를 그리 중요하게 생각하지 않으나 탐색기 등의 프로그램은 중요하게 생각
a는 파일을 byte단위의 array로 표현 : 일반적
b는 ibm에서 파일을 레코드의 배열로 생각.
-> 파일시스템은 c처럼 트리 구조를 갖고 있음.
파일시스템에서 강제적으로 파일 타입을 지정한 케이스 -> 실행 파일(유일하게 포맷 지정됨)
실행시 프로세스 이미지로 만들어져야함 -> 내부 구조가 운영체제 코드에서 사용
과거 유닉스에서는 a.out -> 근래에는 elf포맷 사용
헤더에 매직넘버, 텍스트 사이즈, 데이터 사이즈, bss, 심볼 테이블 뭐 이런 것들이 있고, 이어서 텍스트 데이터 리로케이션 비트 심볼 테이블 이런게 있음.
b를 보면 라이브러리를 묶을 때 헤더+오브젝트모듈 이런식으로 묶고 이 정보를 linker가 사용.
파일 속성 : 파일 이름과 data를 제외한 모든 것(사이즈, 날짜 등)
-> 운영체제마다 조금씩 다름. mac의 경우 HFS 쓰다가 애플 파일 시스템, 윈도우는 fat32에서 ntfs.
Q 파일에 어떻게 접근(symantic)할 것인지?
1. 순차접근
2. 랜덤(다이렉트) 접근 -> 디스크기반이기에 운영체제에서는 엑세스를 랜덤하게 할 수 있어야 된다고 생각
-> 방법 1. 읽을 위치 지정 :오픈해서 읽는 위치를 parameter로 주고, 버퍼에 얼마만큼 읽어달라고 호출 하면 파일 시스템이 from부터 rwbytes만큼 버퍼에 읽어서 반환
-> 방법 2.옵셋 이동 :lseek이라는 코드 통해서 읽을 위치(포인터) 지정하고 read system 호출하면 from부터 byte만큼 읽고 버퍼에 넣어줌
순차적으로 읽는 프로그램이 많아 메소드 2번을 사용 BUT 문제 발생 : 하나의 파일에 스레드가 동시에 접근하나 옵셋은 내부에서 하나로 유지 -> 누가 읽으면 옵셋이 바뀌고, 다른 스레드는 옵셋이 바뀌어서 엉뚱한 부분을 읽게 됨
-> 읽는 시점에 위치를 지정하고자, 두 방법 다 지원. 멀티쓰레드에서는 1번 사용
Q 파일 공유 시맨틱을 어떻게 가져갈 것인지?
동시에 파일을 오픈하고 리드 라이트 가능. 우리가 쓰는 unix와 같은 일반적인 운영체제는 수정된 것을 즉시 확인 가능하나, -> 이것이 파일 공유의 의미가 됨. 기억.
Andrew file system은 네트웤 파일 시스템이라서 데이터가 각자의 로컬에 존재. 따라서 즉시 확인 불가.
-> 닫히는 시점에 다른 프로세스가 올 수 있도록 함.
파일 오퍼레이션 : 생성, 삭제, 개방, 폐쇄, 속성 가져오기, 늘리기, 연결 등등. -> 파일 시스템 내 구현
-> user 프로그램이 접근하려면 system call 형태로 지원.


unix에서 파일 복사할 때 cp명령어 사용. parameter은 3개(프로그램 이름, 소스 이름, dst file 이름).
-> 3개가 아니면 종료.
아규먼트[1]이 소스니까, RDONLY로. 아규먼트[2]가 dst 파일이니까 새 파일 생성(복사를 위해), 이 때 디파인에서 0700이라는건 오너만 리드라이트오픈.
이후 루프를 도는데 소스에서 버퍼 사이즈 만큼 read. 4kb겠지. 읽어서 4kb씩 읽다가 리드카운트가 0이하이면 끝까지 읽었으니 종료, 그리고 dst에 write를 함. wt_count가 0보다 작으면 문제가 있으니까 종료.
루프를 돌면서 내부으로 offset이 유지. 4k씩 읽으면 src, dst 옵셋이 4k씩 증가. 끝나면 종료.
-> 파일 추상화 하고, 파일의 access 시맨틱 정의하고, 파일에대한 오퍼레이션 정의하고, 그걸로 시스템콜 구현. 그 구현된 시스템콜로 파일시스템에 복사.
디렉토리(폴더)도 하나의 파일. 파일에 대한 정보를 가진 파일이 됨(그럼 시스템 콜도 지원하겠지?).
-> 디렉토리 엔트리(파일 이름, 파일 위치 등의 매핑 정보)로 구성되어있고, byte의 연속이므로 파일임.

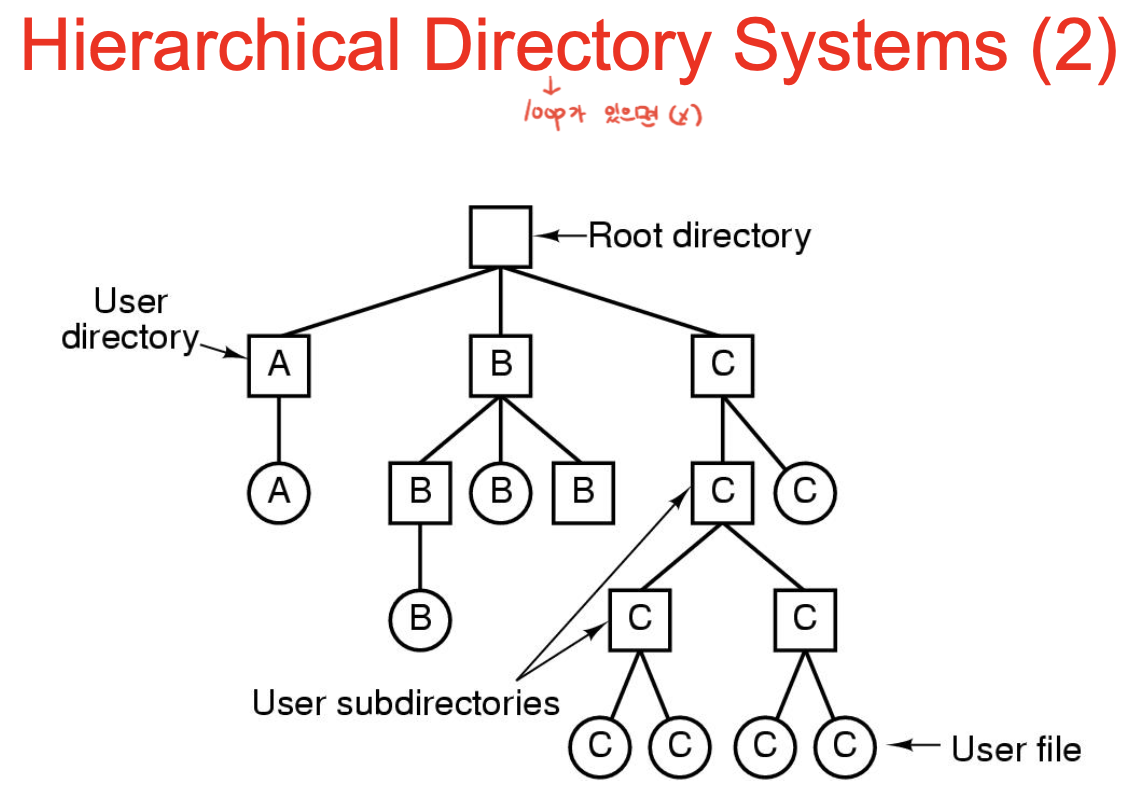
과거 퍼스널pc의 운영체제가 만들어졌을땐 스토리지가 작아서, flat한 파일 시스템을 지원
-> 파일이 많아지면서 관련된 파일을 모아놓으려 디렉토리를 만들고, 계층적으로 만듦.
사용자 디렉토리가 존재. -> 파일의 이름은 경로 내에서는 유일해야 함 : path name.
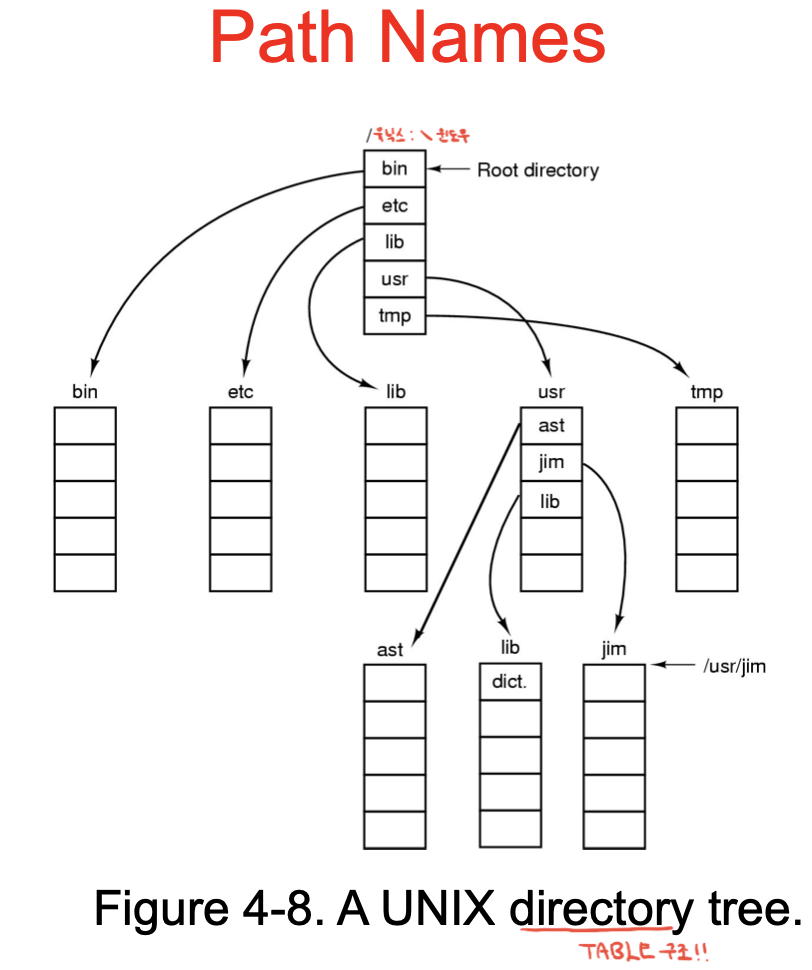
/로 시작하는게 최상위 디렉토리. 그리고 usr 디렉토리가 존재함. 그리고 다시 home 디렉토리가 아래에 존재.
어떤 파일의 path name은 /root/usr/jim/dict. 뭐 이렇게 되는거지.
절대경로 : 루트부터 시작해서 지정된 경로
상대 경로 : ../Work/a.out 과 같이, 현재 디렉토리를 기준으로 상위 디렉토리를 ..으로, 현재를 . 으로 해서 경로 표시.
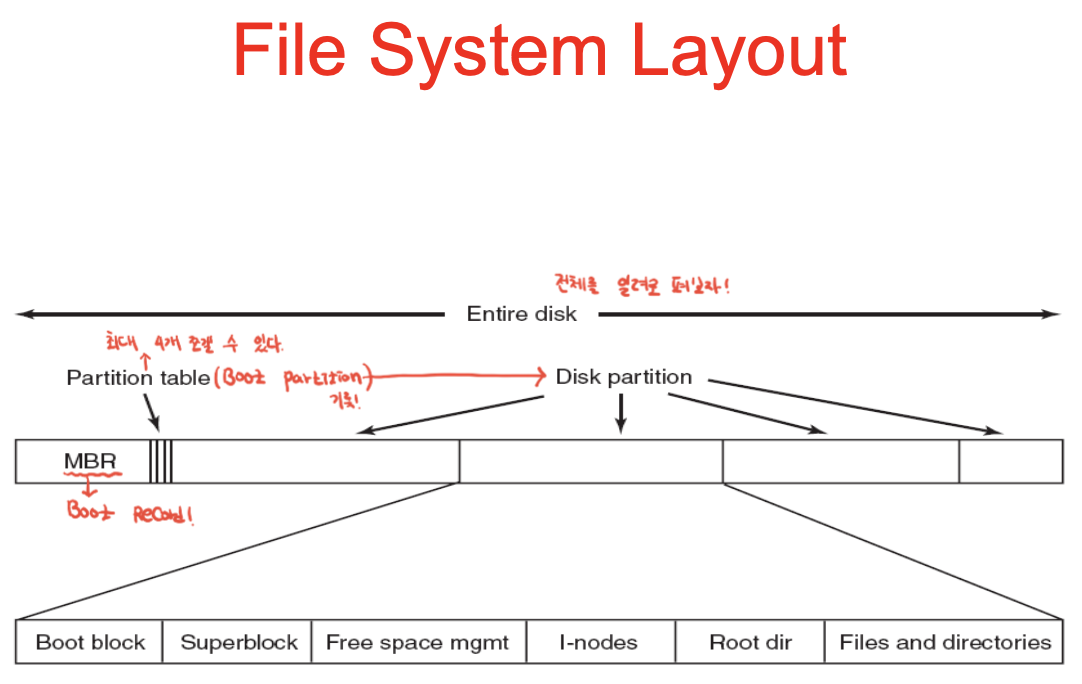
섹터 : 디스크의 최소 단위. 512bytes거나, 4k로도 지정할 수 있음. 아무튼 파일시스템은 연속된 블록으로 추상화.
MBR : 마스터 부트 레코드. 바이오스 실행 후 mbr섹터를 읽어 mbr코드 실행. 디스크의 첫 섹터가 됨.
-> 부트파티션에서 부트이미지를 메모리로 로드해주고 제어를 넘김 -> 로드된 이미지가 커널 이미지가 됨 -> 커널실행.
MBR 바로 뒤에 파티션 테이블 : 4개, 파티션의 사이즈(스타트 to 엔드)와 타입이 지정되어있음.
어떤 타입이냐? 보니 1번 파티션 보면 unix file system.
-> 부트 블록, 슈퍼 블록(파일 시스템의 레이아웃 정보 저장), 빈 블록, 아이노드, 루트디렉토리, 파일들 이런식으로.
과거에는 이런것들을 직접 파티셔닝하고, 어디에 설치할 지 정해야 했음.
파일 시스템을 설계해봐야지.
file allocation : 빈 블록을 어떻게 할당할 것인가. 이후 모든 빈 블록을 어떻게 관리할 것인가.
contiguous allocation : 빈 블록을 연속적으로 할당. but fregmentation이 생김.
non-contiguous : 2가지가 있는데, 포인터로 연결하여 다음 블록이 어디에 저장되었는지 알 수 있음.
chained는 윈도우즈의 FAT에서, Indexed는 유닉스의 inode에서 사용.
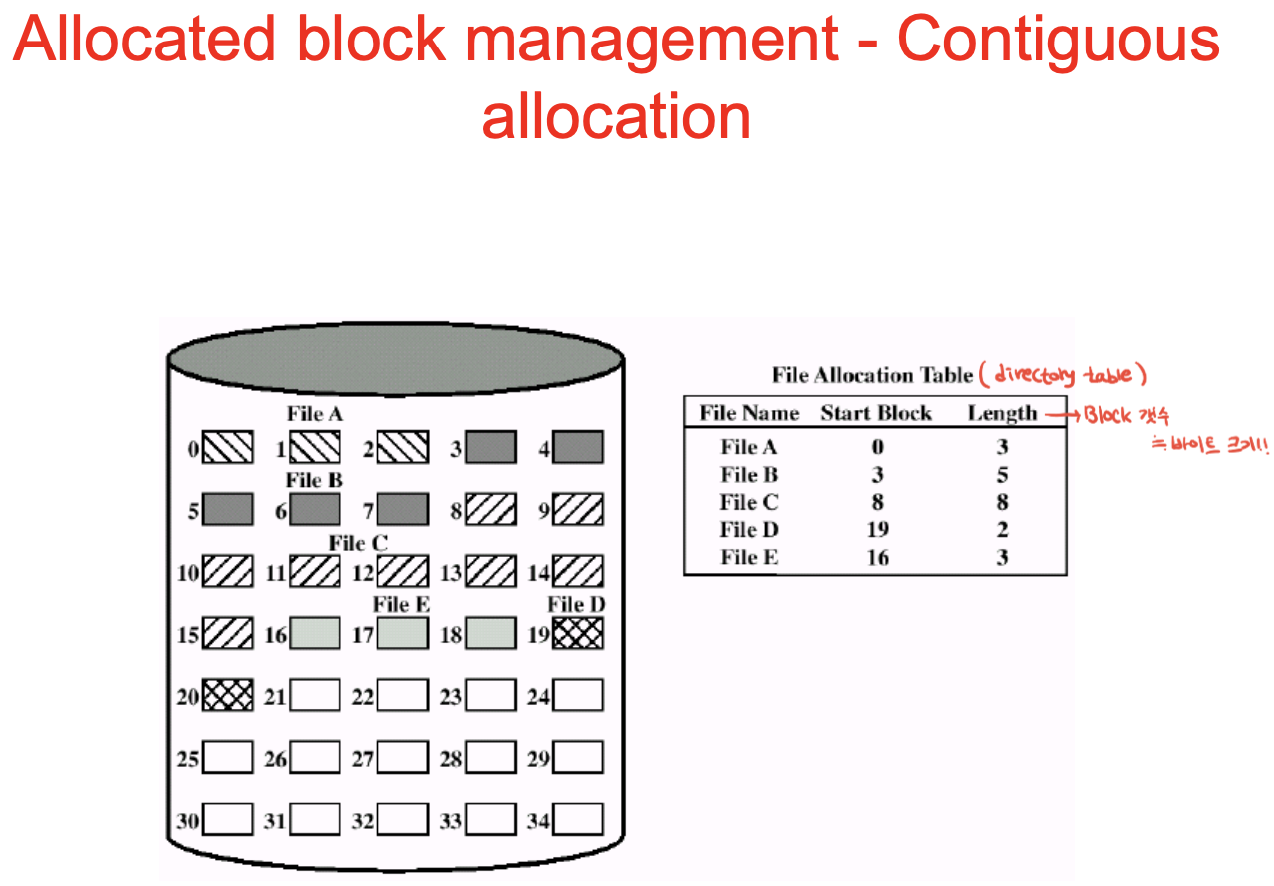
먼저 컨티뉴어스. 우측에보면 allocation table이 있음. 이게 사실은 directory. 파일 이름과 위치 정보를 가짐.
이렇게 연속적으로 저장하면 한번에 쭉 read하게 되므로 성능이 좋음. compact하고 이상적인 형태
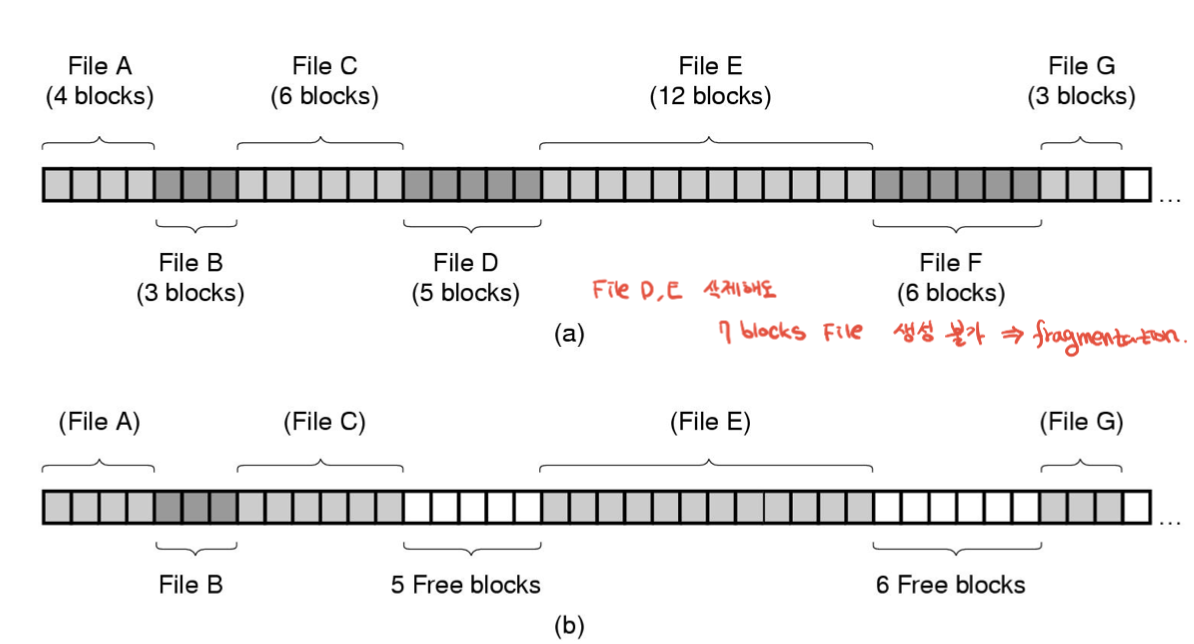
BUT문제 발생. if d,f가 삭제 되고 7개의 블록을 갖는 파일 생성하려면 못하지만 남는 공간은 11칸 : fregmentation
이는 한번 구워서 계속 읽기만 하는, 파일이 동적으로 바뀌지 않는 CD-ROM에서 사용.
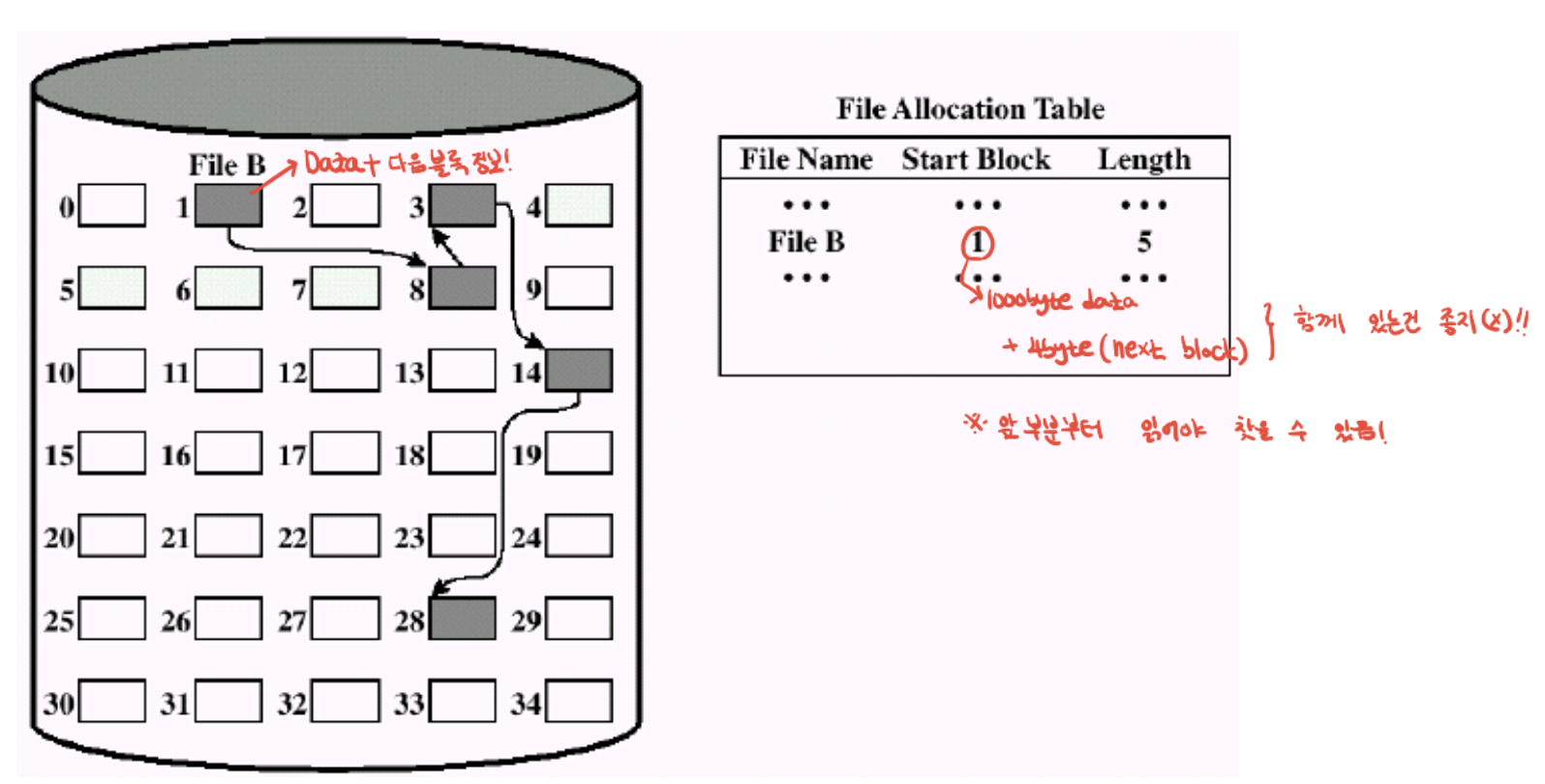
이 chained는 단편화문제를 해결. 블록size를 1024bytes라 보면, 1020만큼 데이터 저장하고 4는 다음 블록번호 지정. -> 메타데이터, 즉 블록번호하고 실제 파일데이터가 같이 저장되어 비효율적.
-> 파일 오퍼레이션에서 파일을 랜덤하게 읽는다고 했는데, 내가 3k(중간) 부터 읽고 싶어도 처음부터 읽어야 함.
또한 첫 블록에서 배드섹터가 만들어지면 읽을 수가 없음.
---
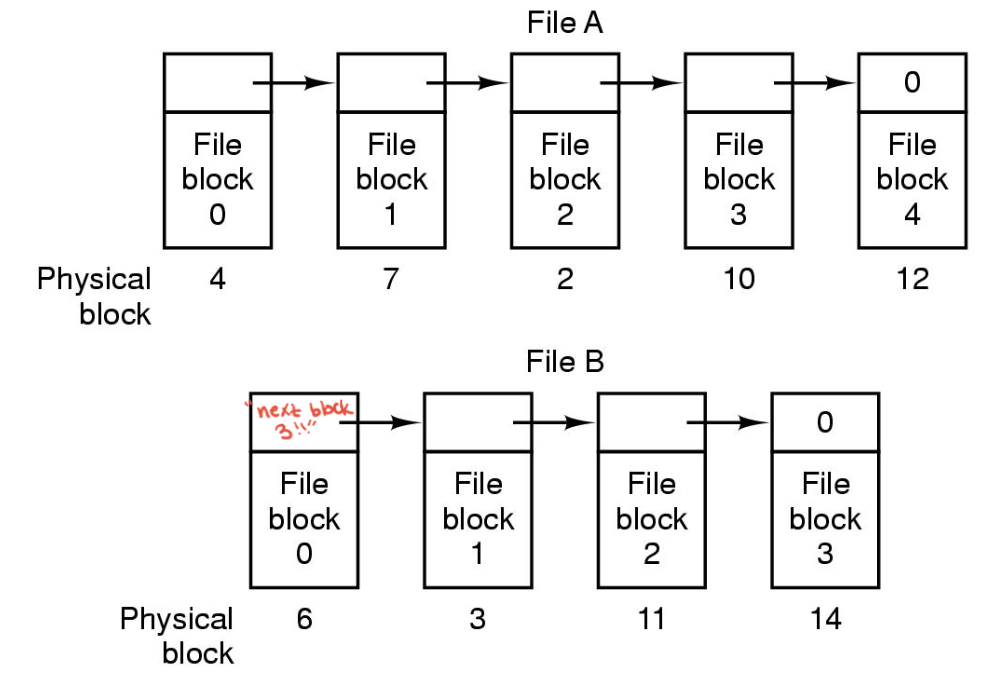
우측 이미지처럼 쭉 메타데이터와 파일데이터가 연결되고, 끝이 표시되어있음.
이걸 효율적으로 만들어볼까?
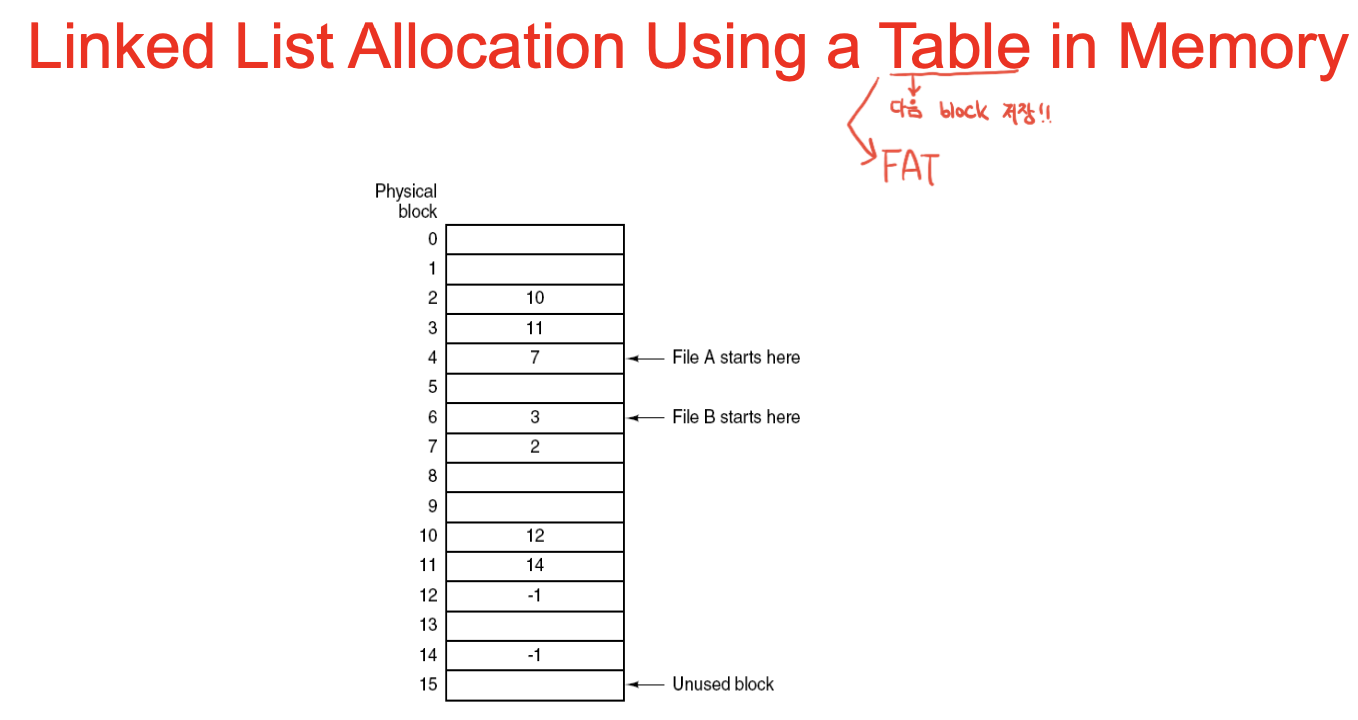
메타데이터 부분, 즉 인덱스 부분만 따로 뽑아 테이블 형태로 만듦.
이 피지컬 블록은 디스크의 사이즈 만큼 존재하고, 인덱스 안에 다음 데이터의 블록번호가 들어있음. -> FAT 시스템.
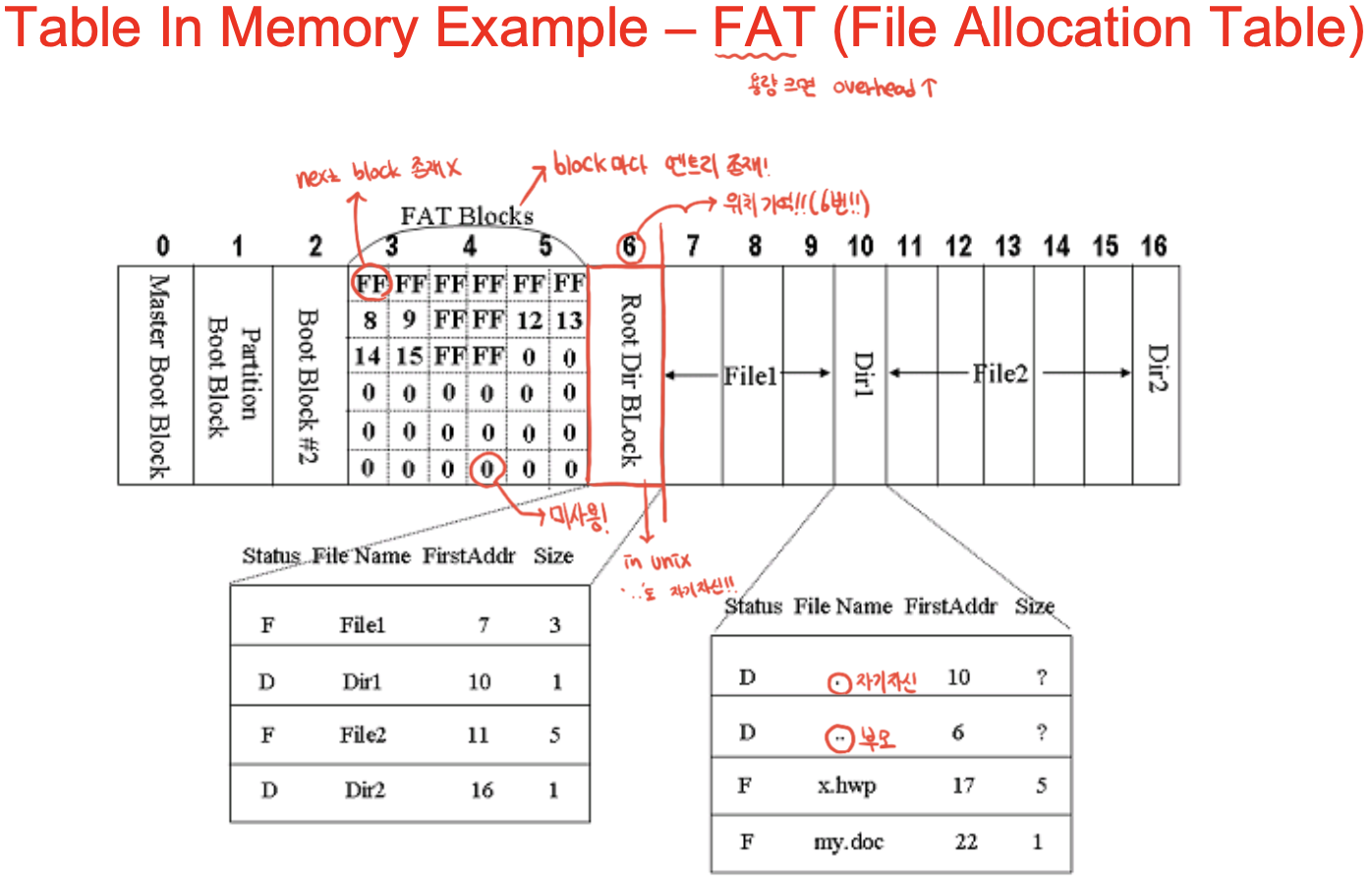
각 엔트리를 블록사이즈로 나눔. 0부터 블록번호가 됨. 0~5까지 다 쓰였고. FF라 쓰여진게 사용되고 있는 것(파일의 끝 표시).
만드는 과정 -> 파티션의 블록 계산(17개) -> 필요한 fat 엔트리 계산 = 17 -> block size를 1k로 하면, 17 * FAT 엔트리 size / blocksize -> 몇 개가 필요한지 계산 가능
1. 6번 루트디렉토리 보면 여기에 디렉토리 엔트리가 들어있음. 파일 1번은 시작 블록번호가 7. FAT 테이블 보면 7번째 블록에 8적혀있음 -> 다음 블록이 8이라는 것.
2. 디렉토리1이 10번에서 시작됐는데, 그 안의 엔트리가 또 있음. ..이 6이니까 상위디렉토리는 6번부터. 이렇게 chained되어서 링크 정보만 뽑아서 파일 데이터를 만들 수 있고 이게 FAT시스템.
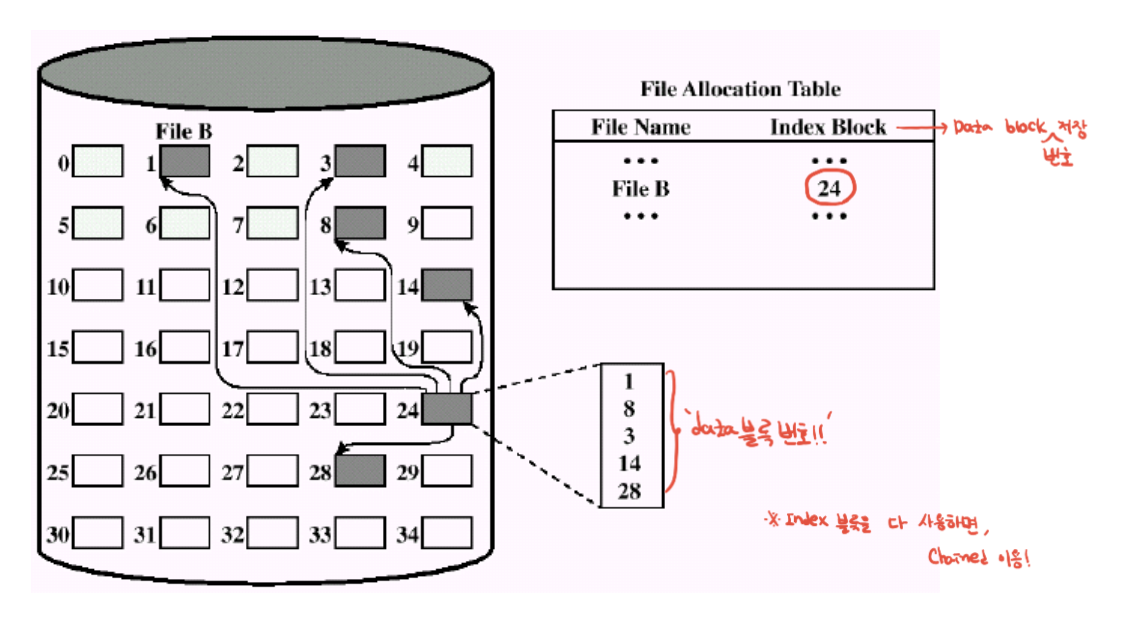
Indexed allcation. 우측에 디렉토리 엔트리와 파일 이름 존재. 24번보면 내용이 1,8,3,14,28. 4바이트(블록번호 하나당) 배열로 쪼갰음. 즉 인덱스를 위한 블록을 별도로 할당 -> 고전적인 unix 파일 시스템.
순서대로가 아니고, 연속적으로 블록할당하지 않아도 됨.
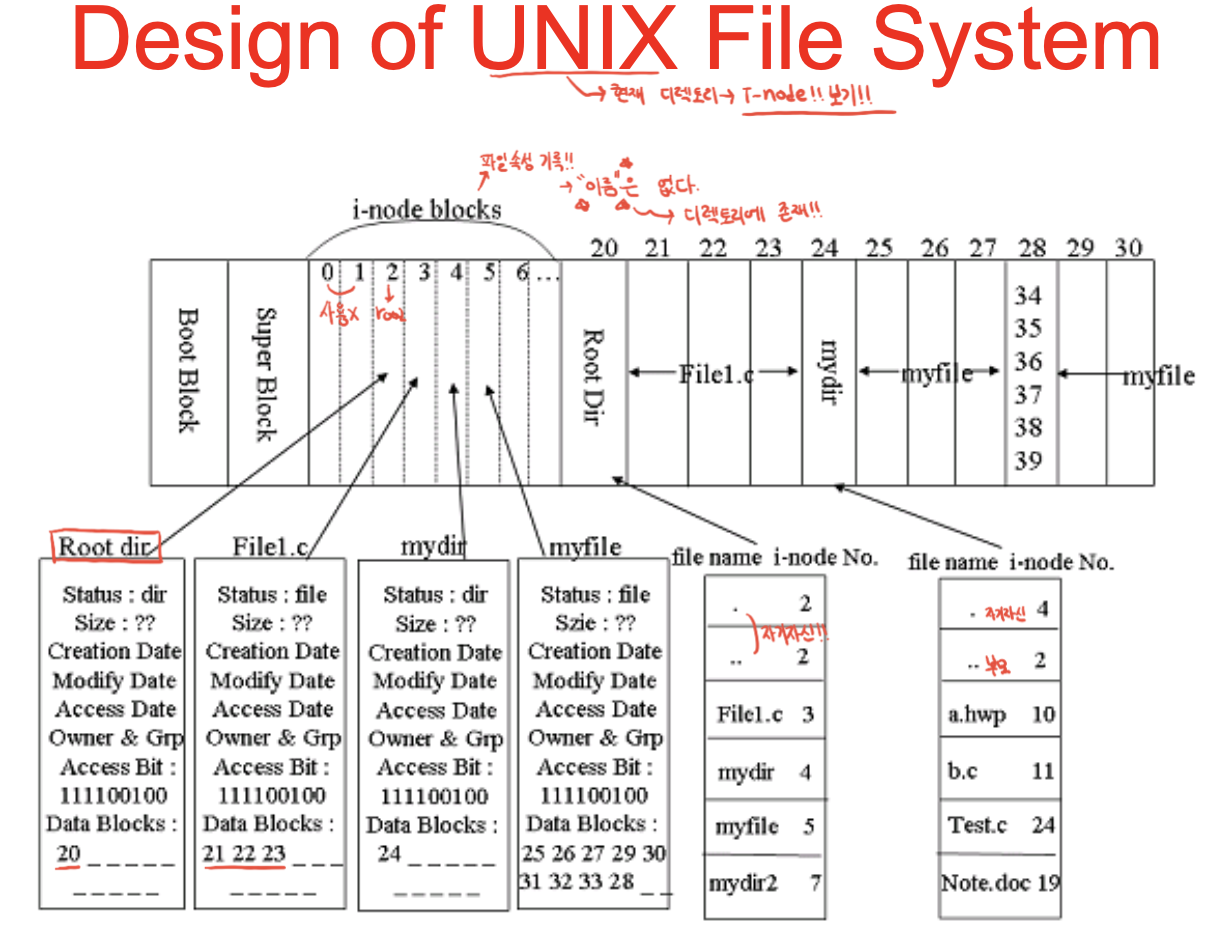
슈퍼블록 : 유닉스 파일 시스템의 형상정보가 적혀있음. 아이노드는 어디부터~ 데이터는 어디부터~ 이런 것들.
아이노드는 128바이트 -> 한 블록이 1k라고 하면, 한 블록에 8개씩, 128만큼의 아이노드를 저장할 수 있음.
루트 디렉토리가 20번부터 시작 -> 가서 보면 디렉토리 엔트리는 파일 이름과 아이노드 번호를 매핑.
아이노드 번호는 유일하고, 파일과 디렉토리가 생성되는 순서대로 할당. 시스템을 포맷하는 시점에 전부 계산되어 결정.
아이노드 0,1은 사용하지 않음. 루트가 2. 이후 저널링을 위해 저널 파일을 도입하고 얘가 아이노드 1번 할당.
2번의 아이노드 정보를 보면, status, size, access bit, datablock 뭐 이렇게 있음.
마이파일은 5번 아이노드. 파일이고. 2526272930 31 32 33 28~ 이렇게 되어있는데.
28번 블록의 경우 안에 블록번호가 존재. 아이노드의 크기가 128바이트인데, 일부분만 블록번호를 쓸 수 있는 공간
-> 아이노드 공간이 모자라서 인덱스 블록을 할당해서 4바이트의 블록번호를 순서대로 작성 -> 사이즈가 큰 파일을 인덱싱하게 됨.
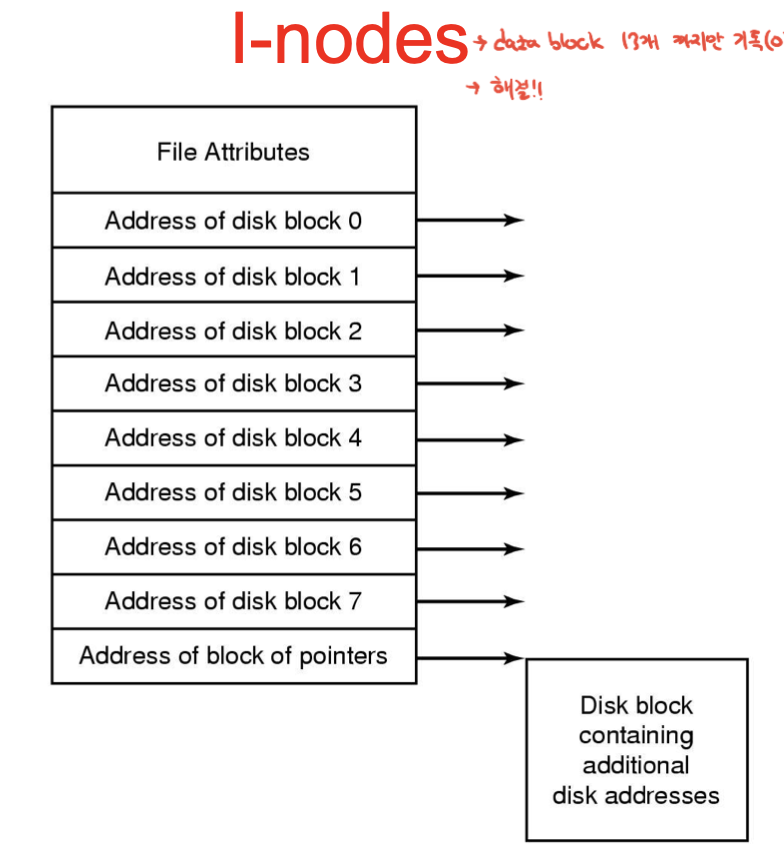
아이노드의 최상단에는 파일의 속성정보, 이후 direct indexing blocks, 마지막엔 indirect 인덱싱 블록.총 8개 이므로 4 * 8 = 32kb까지 다이렉트로 정보를 저장.32보다 클 수가 있지. 그러면 저 포인터스도 4kb겠지, 주소하나가 4바이트니까 총 1024개의 주소를 저장할수있지.1kb(1024개 주소) * 4kb(주소당 4kb) = 4mb. 따라서 총 4mb+32kb의 파일을 저장할 수 있음.
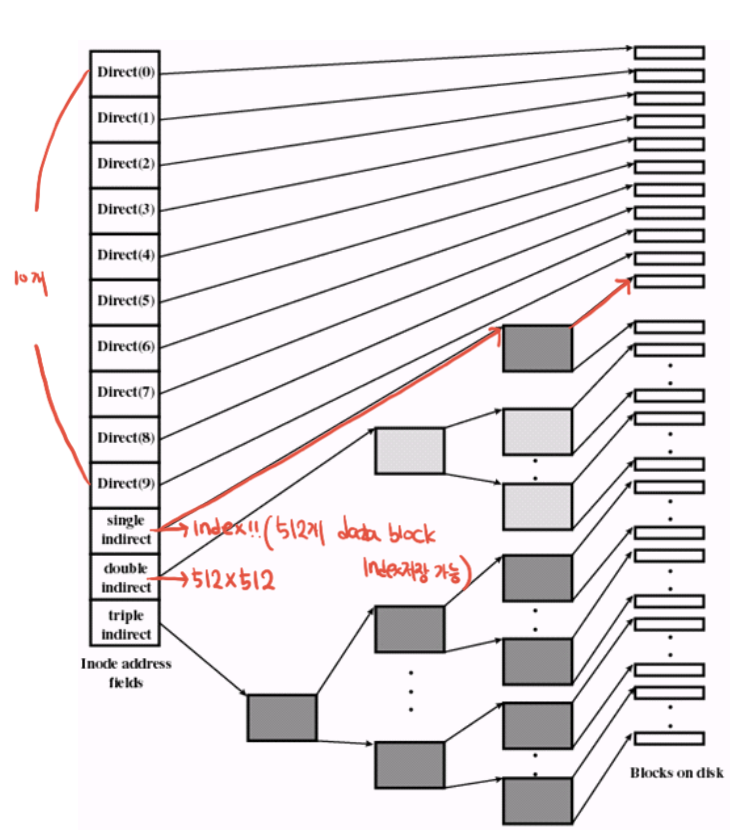
이 예제에서는, 다이렉트가 10개니까 만약에 40kb보다 크면 이제 간접 인덱싱을 해줌.
4m까지 지정할 수 있지. 근데 또 4m가 넘으면 또 2차로 간접 인덱싱을 해줘.
우리가 쓰는 파일은 작거나 크거나임. 이렇게 인덱싱하면 작은 파일은 아이노드만 읽어서 바로 데이터블록에 접근할 수 있고, 큰 파일도 인다이렉트 블록을 통해 인덱싱이 되어서 이 형태로 블록 어드레싱을 함.
'UOS > UOS@운영체제' 카테고리의 다른 글
| [운영체제] 5. I/O(입출력) - 1 (0) | 2023.06.14 |
|---|---|
| [운영체제] 4. 파일시스템 2 (0) | 2023.06.10 |
| [운영체제] 3. 메모리 관리(6/6) segmentation~ (0) | 2023.05.19 |
| [운영체제] 3. 메모리 관리(5/5) (0) | 2023.04.24 |
| [운영체제] 3. 메모리 관리(4/5) (0) | 2023.04.23 |