

2.2.3 POSIX스레드 : 유닉스 표준, 여기서 정의한 스레드 패키지는 Pthreads라 불림.

2.2.4 Implementing Threads in User Space

과거 : 좌측처럼 유저레벨에서 thread만들어 쓰게끔 함. 커널엔 프로세스 테이블만 존재. 프로세스 별로 스케쥴링.
런타임 시스템 : 스레드 패키지에서 지원하는 라이브러리, 스레드 관리하는 프로시져들의 모음 : 안에 스레드 테이블을 갖고 있음.
-> 프로세스가 커널에서 스케쥴링되어 실행되는 시점에 런타임시스템에서 스레드 3개중 하나를 골라 실행. : 스케쥴링 기능 O
User level thread package : 프로세스 단위 CPU할당, 각 프로세스에서 스레드별로 나누어서 실행시켜주는 것
-> 비용 많이들고, 프로세스를 많이 만든다는 것 자체가 어려움
-> I/O동작시 스레드가 아닌 프로세스 자체가 block
2.2.5 커널 내부에서 스레드 구현
blocking이 생기지 않으려면 -> state machine 형태로 구현해줘야 함.
프로세스 테이블이 커널에 존재, 스레드 테이블도 존재. -> 스케쥴링 단위가 스레드가 됨.
2.2.6 HYbrid

커널에서는 커널 스레드 유지, 유저레벨에서도 유저 스레드 유지.
커널 스레드 : 비용 up, 유저 스레드 : 저렴. 커널과 유저를 1:n으로 맵핑.
1:3 -> 스케쥴링은 커널스레드 단위, 긴 일이 필요하지 않을 떄 유저스레드를 만들어서 사용.
2.2.8 : 팝업 스레드 : 분산 환경에서 메세지가 왔을 때 그 메세지를 보여줄 때 활용

2.2.9 : making Single-Threaded Code Multithreaded
-> 스레드로 멀티 스레드를 지원하려면, 스레드 자체로 스캔 뿐만 아니라 하드웨어컨텍스트도 유지해야 하고 문제가 더 생길 수 있음.

스레드 1 : 엑세스 시스템을 호출. -> 호출이 정상적으로 실행됐는지 전역변수인 에러 넘버에 세팅
-> 그러나 체킹 전에 2번이 스케쥴링이 되어버림 -> 오픈 시스템 호출 -> 1번에서 세팅한 에러 넘버가 2번에 의해 overwritten.
-> 이후 1번이 스케쥴링 되면 에러 넘버가 검사되지 않음.
-> 현재는 각 스레드별로 코드, 스택, 전역변수 다 각자 유지하게 됨.
2.3.1 Race condition, 경쟁 조건

이미 기록되어있는 상황에서 A와 B가 출력하려고 하는데, 스케쥴링 상황에 따라 7번에 기록되는 데이터의 내용이 달라지며, 심지어 덮어씌워버릴 수도 있음. 이게 레이스 컨디션이고, 컴퓨터 시스템에서는 막아야 함.
2.3.2 Critical Regions(임계 구역) : 메모리에 변수 선언해두고, 여러 스레드가 접근하려는 그 코드 부분. 공유변수 자원을 참조하는 코드.
- No two processes may be simultaneously inside their critical regions. (Mutual Exclusion)-> 레이스 컨디션이 발생하면, 해당 크리티컬 리전에 한 순간에 하나의 프로세스나 스레드가 진입하도록 해야함(상호배제)
- No assumptions may be made about speeds or the number of CPUs.-> CPU의 속도개수에 영향받지 않음.
- No process running outside its critical region may block other processes. (Progress)-> 비어있으면 무조건 들어갈 상황을 만들어줘야 한다는 것. 임계구역 외부의 프로세스는 다른 프로세스들을 블록시켜선 안됨.
- No process should have to wait forever to enter its critical region. (Bounded Waiting)
-> 기다리면 어느순간엔 임계구역에 진입할 수 있어야 함.
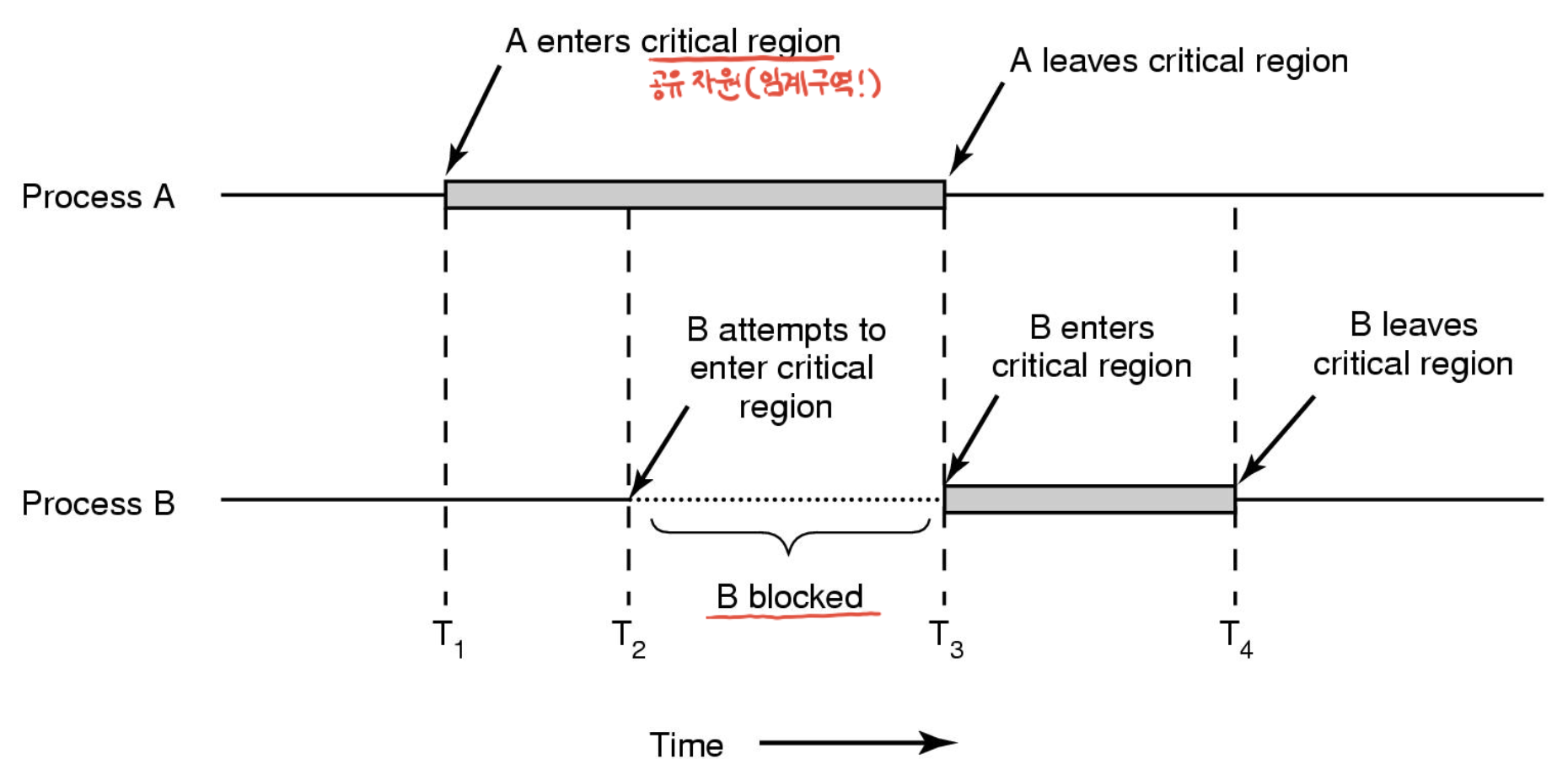
A가 이미 작업중이기에 B는 임계구역으로 진입을 못함(Blocked)

V는 공유변수, V++; : 크리티컬 리전.
타이머 인터럽트를 실행시켜서 레지스터에 넣고, 값을 1 증가시킴 -> 메모리에 쓰기 전에 j에서 V 다시 가져와서 증가시킴 -> 1 중복입력
동시에 V값이 증가 : Race condition.
이걸 막으려면 이 분홍색 부분, 진입할 때 한 순간에 하나만 진입하도록. 이걸 잘 만들어 놓으면 동시에 두 프로세스/스레드가 진입못하도록 할 수 있음.
2.3.3 바쁜 대기(Busy waiting)을 활용한 상호배제(Mutual exclusion)
- Disabling interrupts (인터럽트 꺼버리기. CPU와 프로세스 간 문맥을 교환하지 않음)-> 2개 이상의 CPU를 사용하는 다중처리기 시스템일 경우 불가, 유저 프로세스에서 인터럽트를 꺼버리면 다른 프로세스는 인터럽트를 받지 못함 : 운영체제 내부에서, 커널 내에서 인터럽트를 금지시키는 것은 유용하나, 유저 레벨에서는 적절하지 않음.
- Lock variables (변수를 따로 설정하기. 의미 없음)
- Strict alternation (번갈아가며 임계구역에 진입하자)

turn 변수를 추가 -> turn 변수에 따라 critical region에 진입하게끔 함. -> i가 아닐동안 루프를 돌고(자기차례 기다림) -> 오면 임계 구역으로 진입하여 수행 후 상대편 턴으로 변경 -> 다른 영역으로 감.
-> 상호 배제를 만족했으나, CPU의 속도에 따라 while루프를 빠져나올 수 없을 수 있음. (그러나 조건2에따라 무시)
-> 그러나 프로세스 0이 실행을 마치고 턴을 1로 설정했는데, 프로세스 1은 아직 비임계구역을 수행 ->프로세스 0이 다시 진입하고싶어도 못함 : 묶여있어함 : 조건 3 위반
- eterson's solution
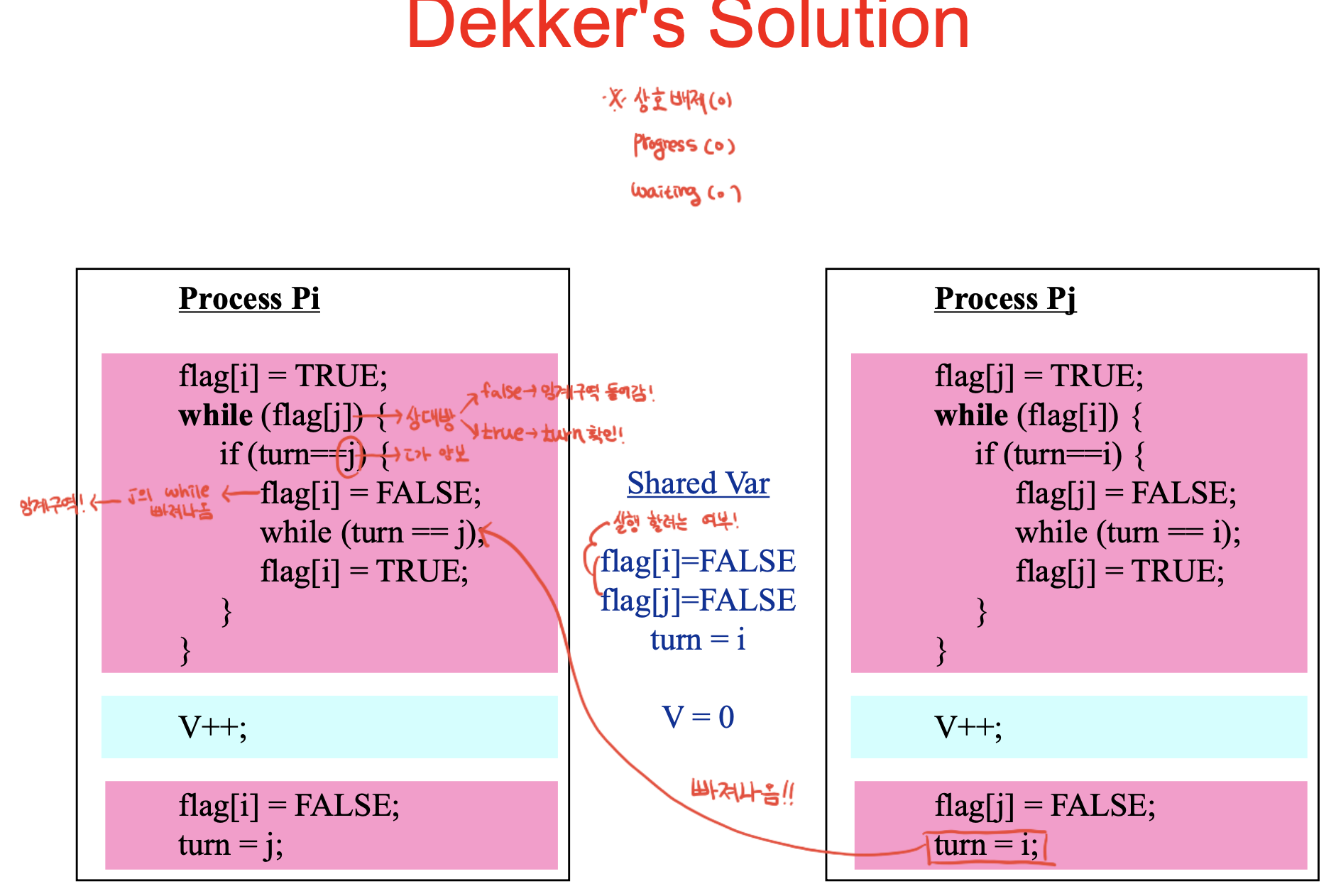
뭔가 하나 더 있으면 되지 않을까?
그래서 flag변수를 하나 추가 -> 상대방의 의도를 파악. 턴 변수는 진입하겠다는 것.

의도적으로 상대방이 크리티컬 리전에 들어올지 말지를 결정하는 플래그 2개를 추가.
트루면 진입 하겠다는 것. 턴 변수는 양보하겠다는 것. 턴 값을 변경하는 위치가 달라져서, 정상적으로 동작하지 않게 됨.
ex) 현재 턴 변수가 j이고, 프로세스 i가 진입하려 했을때. j는 진입할 의사가 없으므로 플래그i는 트루. 우측보면 플래그 j는 폴스.
따라서 와일루프 돌지 않고 크리티컬 리전으로 진입. 이제 pj가 진입하려고 하면. flag i는 트루. 턴은 j따라서 인계구역으로 진입.
-> Pi가 진입하고 턴이 j일 때, Pj가 진입하려 하면 Pj도 진입할 수 있음 : 상호배제 X


while loop가 조금 다름 -> 턴 변수부터 관찰 후 상대방의 진입 의사를 확인 : 결과적으로는 같음.
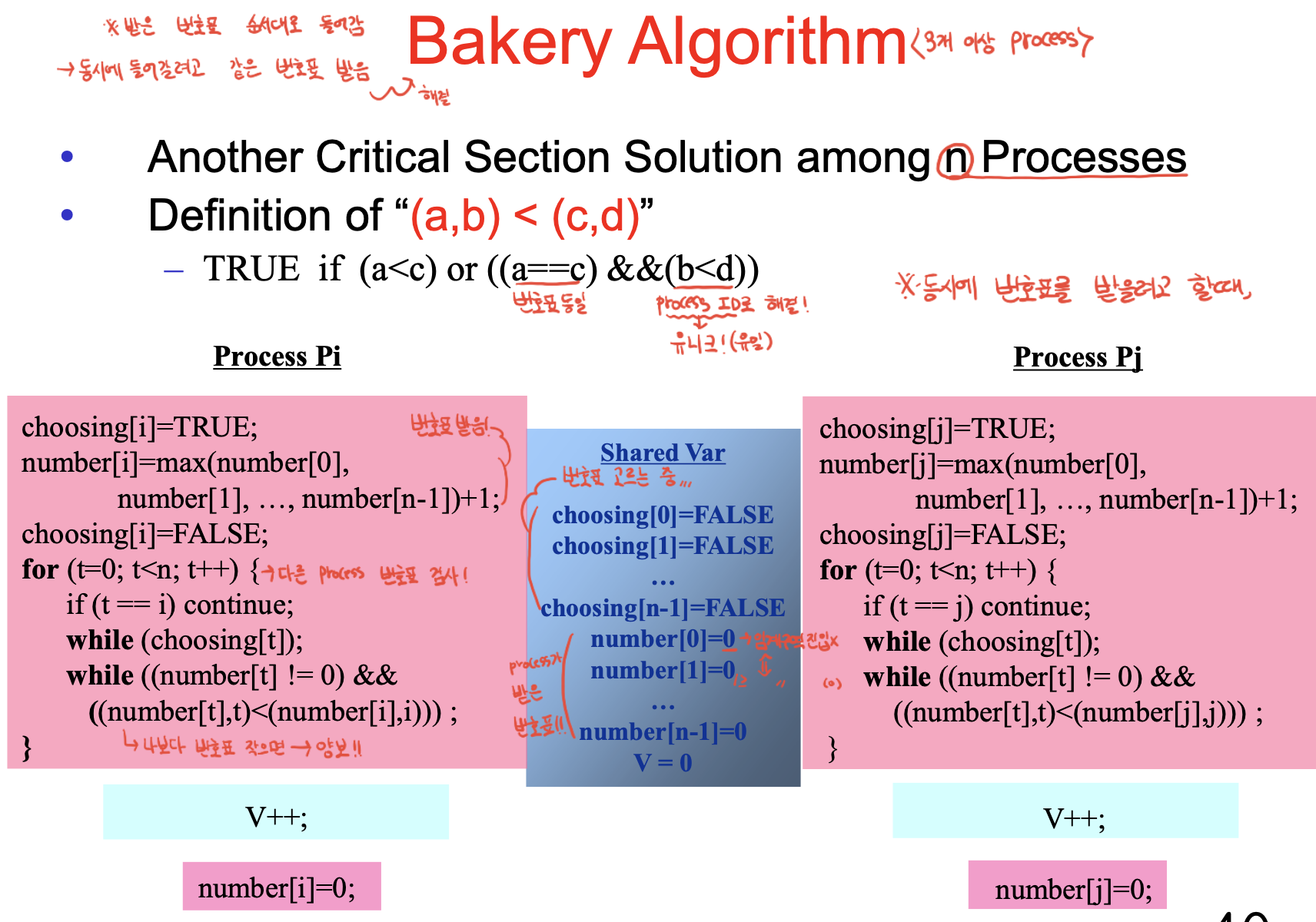
베이커리 알고리즘은 3개 이상 프로세스 간 동기화에서 사용. 번호표를 받은 후 순서대로 서비스를 받게 됨.
choosing이 있고, 이 배열에서 인덱스가 프로세스 번호. 번호표를 선택할 때 choosing변수를 트루로 만들고 번호표를 받음. 프로세스들 중 가장 큰 것 +1의 번호를 받음. 그리고 choosing i를 false로 변경.
T가 번호표 뽑고 있을 수 있으니 기다림. 이후
만약 번호표가 동일할 수도 있음 -> 프로세스 번호가 작은게 우선순위 높은 것으로 정함.
- The TSL instruction

바쁜 대기(while)가 너무 비효율이라, 하드웨어의 도움을 받은게 TSL, 인스트럭션을 만들어줘!
임계구역에 진입할 때 Lock변수 값이 어떠냐에 따라 임계구역에 진입하고 못하고를 결정.
Lock 변수는 메모리에 있음 -> 레지스터로 가져오고 -> 메모리 주소에 값을 기록
CMP : 내가 바꾸기 전 값 확인
- 따라서 레지스터의 값과 0과 비교 -> 같다면 메모리에 있던 값이 0,
메모리의 lock에 tsl instruction 을 통해 1로 써놓고, 이전에 레지스터 값=락변수 값이 0이었으니 누가 락을 걸지 않았다는 것.
- 만약 같지 않다면= 레지스터 값이 1이었다면 내가 락 변수를 쓰기 전 이미 메모리의 값이 1 -> 다시 엔터 리전으로 가서 tsl,레지스터,락 재실행.
엔터 레전은 무조건 락을 1로 바꾼다.
- tsl 인스트럭션이 두 동작이라면? -> 만약 중간에 다른 프로세스에서 메모리의 값을 바꿔버리면 오류
-> tsl 명령어는 한 동작 : 아토믹 하다. -> cpu는 메모리와 버스로 연결되어 있으므로 버스로 lock signal을 보냄 -> 나만 메모리 값을 변경 가능하도록.
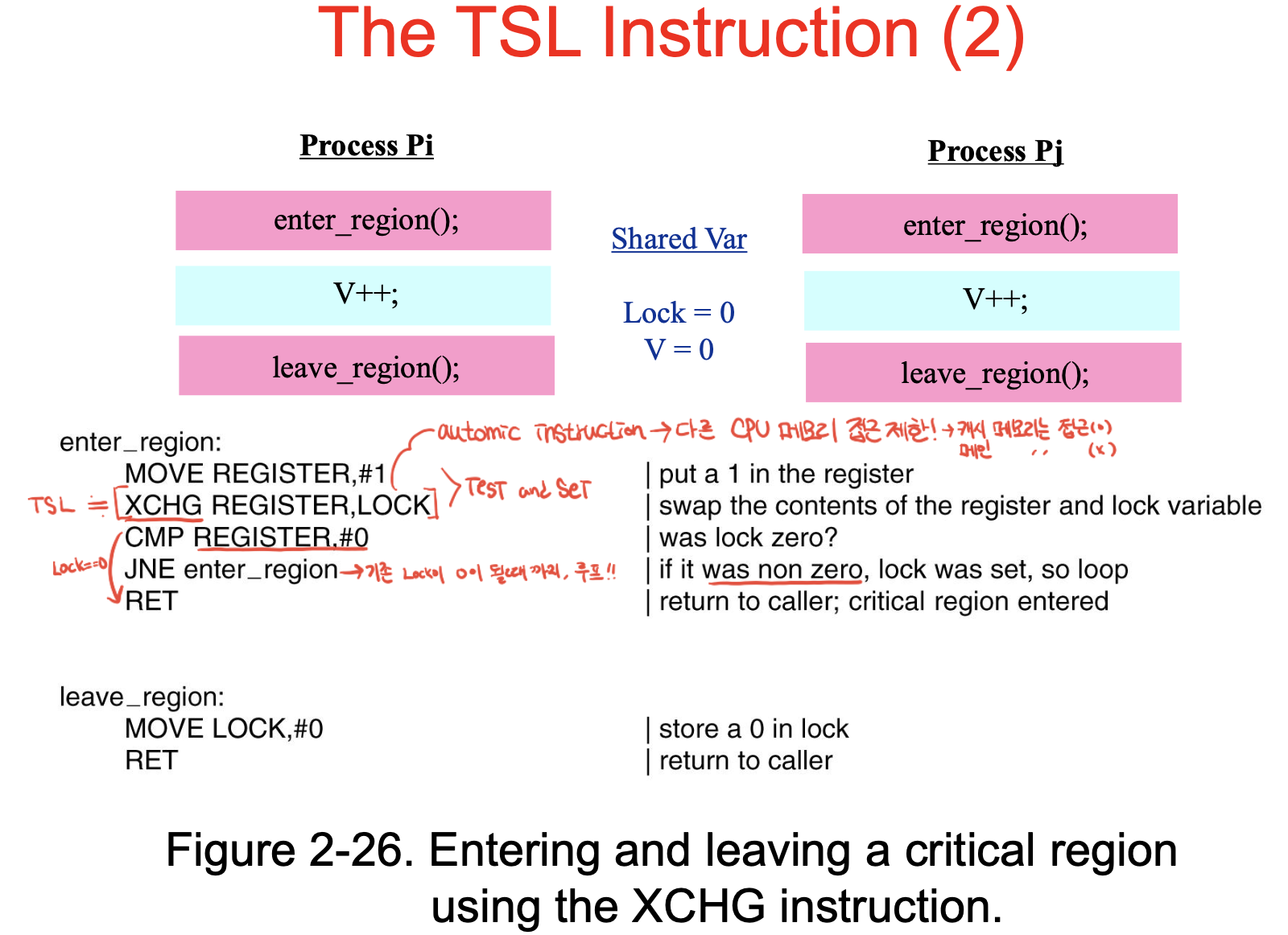
exchange(XCHG)가 있는데, 레지스터의 값과 메모리의 값을 atomic하게 변경시켜주는 연산.
동일하지만, 의미적으로 조금 더 낫다는 것.

Spin lock : 상호 배제를 잘 구현 : 루프를 가지고 상호배제를 구현
버전 1 : 스핀락 변수가 메모리에 존재하고, 와일 루프를 계속 수행 -> 다른 프로세스의 진행을 막음. -> 테스트 앤 셋 동작을 할 떄 마다 버스에 락을 시도하니까 다른 프로세스나 스레드가 실행되는 것을 방해
리바이스버전 : 실패하면 메모리 값을 관찰만 함 -> 바뀌게 되면 테스트 앤 셋을 실행 -> 효율적
단점 : 할 일이 없는데도 계속 루프를 돎 -> 잠들었다가 필요할 때 깨우면 되지 않을까?

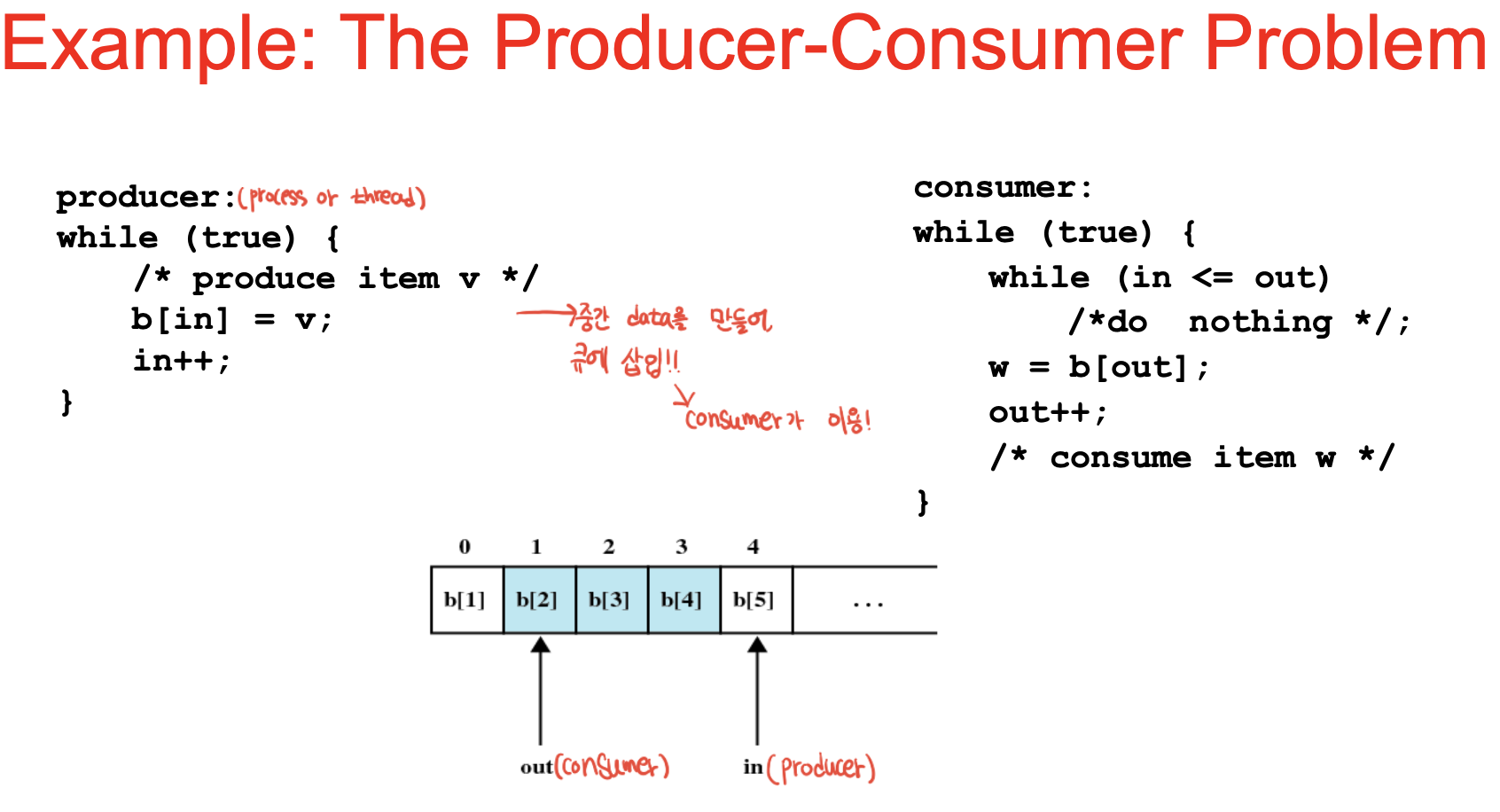
생산자 소비자 문제 : 유한 버퍼 문제 : 프로듀서와 컨슈머는 다른 프로세스 or 스레드 -> 공유하는 데이터가 유한버퍼.
프로듀서는 while loop 안에서 아이템 생성 -> 버퍼에 채움 -> N은 큐의 크기, 카운트는 아이템의 개수 -> 카운트가 N이면 버퍼가 꽉참 -> 프로듀서는 잠들어야 함 -> 컨슈머를 꺠워줌 : 아름답게 cowork중.
count에 mutex exclusion이 되어있지 않음 -> 버퍼가 비어있고 소비자가 카운트가 0임을 알았을 때, 스케쥴러가 소비자 정지시키고 생산자를 수행 -> 생산자가 아이템을 버퍼에 추가하고 1이 되었을 때, 소비자가 잠든 상태가 아니었다면 wakeup시그널은 사라지고, 예전에 소비자가 읽었던 카운트가 0 이 었으므로 잠듦
아직은 깨어있는 상태이기에 wakeup 무시 후 바로 sleep-> 둘 다 잠들게 됨.
-> 카운트값에 접근할 때 상호배제 되어야 하고, 카운트가 n 1 0 n-1이런 경계조건일 때 확인하고 슬립과 웨이크업을 수행하는걸 한 동작으로 해야 함.

세마포어 : 새로운 변수형 : 카운트값(자원의 개수)을 가지는 변수 : 자원에 대한 값, -> 상호배제와 동기화 구현
- 임계 영역을 설정한다.
- 임계 영역에 진입하기전에 세마포어 값을 확인한다.
- 세마포어 값이 0보다 크면 세마포어를 가져온다. 세마포어를 가져왔으니 (커널의 입장에서)세마포어가 1감소 한다.
- 세마포어 값이 0이면 값이 0보다 커질때까지 block 되며, 0보다 커지게 되면 2번 부터 시작하게 된다.
-> down은 세마포어 카운트의 값을 1 다운시키고(세마포어를 얻고) 바로 반환, 카운트값이 0보다 작으면 프로세스를 레디큐에 매달고 블록킹
-> UP연산은 세마포어 카운트 값을 1 증가시키고(세마포어 반환), 카운트 값이 양수가 아니면 블록킹된 프로세스를 큐에서 하나를 깨워줌(또 반환하라고).
이때 이 두 연산은 automic해야한다.

여기서 세마포어는 음수를 가질 수가 없음 : 자원은 0 이상이니까.
양수면 감소, 아니면 유지, 큐에 있으면 깨워줌, 깨우지 않으면 남은거니까 카운트 ++.
'UOS > UOS@운영체제' 카테고리의 다른 글
| [운영체제] 3. 프로세스 & 스레드(4.8/5) (0) | 2023.04.16 |
|---|---|
| [운영체제] 3. 프로세스 & 스레드(4/5) (0) | 2023.04.16 |
| [운영체제] 3. 프로세스 & 스레드(3/5) (0) | 2023.04.15 |
| [운영체제] 1. 운영체제 서론(2/2), 프로세스 & 스레드(1/2) (0) | 2023.04.13 |
| [운영체제] 1. 운영체제 서론(1/2) (2) | 2023.03.21 |