

1.2 운영체제의 역사
1세대 : 진공관
2세대 : 트랜지스터 + batch 시스템
3세대 : IC 와 다중프로그래밍

- cpu는 연산이 빠르기 떄문에 입출력장치를 기다리게 된다 -> cpu는 놀게 되기 때문에 입출력장치가 job1 을 처리하는 동안 cpu는 job 2를 연산할 수 있고, 이 시점에 멀티 프로그래밍이 가능해졌다.
- 이 때의 운영체제 중 MULTICS가 있는데, 보안코드가 많이 들어가 굉장히 느렸기에 상업적인 성공은 거두지 못함. 이후 UNIX로 발전
-pdf 11 / p12
4세대 : 개인용 컴퓨터. CP/M -> DOS -> MS-DOS -> GUI ...
1.3 하드웨어 복습
CPU는 메모리에서 명령(instruction)을 받아 실행하고, 결과를 다시 메모리로 반환.
모니터나 하드디스크 같은 각각의 주변기기는 각 컨트롤러를 통해 연결되며, 이런 장치들은 bus를 통해 CPU와 메모리와 연결됨.
컨트롤러 내부에서도 메모리와, 프로그램과, 코드가 존재 가능. 이를 CPU에서 가져다가 실행하거나, 비디오 컨트롤러의 메모리에 명령을 전달할 수 있음. 하드디스크 컨트롤러 내부에도 sata, nvme와 같은 메모리가 존재.
bus는 전선. 이를 통해 제어신호, 주소, 데이터 등을 보냄.
i/o 모듈 내부의 메모리에는 메인 메모리와 겹치지 않는 주소를 할당함
ex) 서로의 10번은 각기 다른 주소를 갖고 있음.
프로세서 레지스터에는 user-visible과 unvisible(운영체제가 사용)이 있음.
명령이나 데이터를 가져오기 위해 메모리에 접근하는 시간이 명령을 실행하는 시간보다 훨씬 길기 때문에 모든 CPU에는 중요한 변수나 결과를 임시로 저장할 수 있는 레지스터가 존재.
user-visible에는 데이터, 주소, Index, segment pointer, stack pointer(메모리에 있는 현 스택의 최상위를 가리킴)이 있음.
special하거나 user-invisible한 레지스터에는 Program Counter(fetch해야 하는 다음 명령의 메모리 주소를 포함), IR(instruction register), PSW(program status word, 비교 연산에 의해 설정되는 조건 코드 비트나 cpu의 우선순위, 모드, 각종 제어비트들이 있음)가 있음.
파이프라이닝 : 작업을 빨리 해보자!
기존의 CISC 방식은 명령어의 길이가 가변적이고, 처리하기가 복잡. 이를 효율적으로 해결한 것이 파이프라이닝.
펫치, 디코드, 익스큐트 세 유닛으로 나눈 것. 명령어 하나 실행하는 데 걸리는 시간이 1/3으로 줄어들고, 단계를 늘릴 수 있음.
단점은 레지스터와 트랜지스터를 더 사용해야 하기에 발열이 있음. 그리고 분기문이 있으면 앞에서 처리한 명령들을 다 버려야함.
따라서 위험부담이 있으며, 모바일은 7단계, 데스크톱은 11단계 정도로 구성.
슈퍼스칼라CPU는 홀딩 버퍼에 모아놓고 동시에 실행하여 최대한 한번에 많이 동작하게 함.
더 빠르게 동작하고 싶을 때 멀티쓰레딩과 하이퍼쓰레딩(인텔).
cpu로 하여금 두 개의 서로 다른 스레드 상태를 가질 수 있도록 하여 나노초 단위에서 왔다갔다 동시에 두 일을 할 수 있게 함.

여기서, 더 빠르게 하고싶어 멀티 코어를 사용. b가 편리하나 느려지는 문제가 있어 a방식을 사용, 요즘엔 l2까지 내부, l3를 공유.
인터럽트 : CPU가 프로그램을 실행하고 있을 때, 입출력 하드웨어 등의 장치에 예외상황이 발생하여 처리가 필요할 경우에 CPU에게 알려 처리할 수 있도록 하는 것. 우선적으로 처리해야할 일이 발생하였을 때 그것을 처리하고 원래 동작으로 돌아옴.
i번째 명령 실행 도중 인터럽트 발생 -> 버스 중에 인터럽트 선이 존재(혹은 인터럽트 컨트롤러가 존재) -> i번째 명령까지 실행하고 인터럽트 핸들러를 실행 -> i+1번째 명령 실행.
스택은 push-pop연산을 하기때문에, 그림에서 위로.
Cpu의 제너럴레지스터에는 이전의 동작이 담겨있음. 이를 스택에다가 저장함. 그리고 복귀주소를 설정해야함. 복귀주소는 현재 프로그램 카운터의 n+1이 됨.
그럼 이제 cpu에서 스택포인터는 t-m이 됨. 레지스터는 전부 리셋이 됐고,
프로그램컨트롤러는 y를 가져다가 실행(인터럽트를). 끝나고 복귀주소를 만나면 스택에 저장되어있던 레지스터들을 원래 레지스터로 다시 가져옴. 스택포인터는 다시 t로 줄어들고. 스택의 리턴어드레스를 실행해서 원래 프로그램의 n+1번째로 감.
메모리는 레지스터에 비해 10배정도 느림. 그래서 그 중간에 조금 더 빠르게 동작하는 메모리를 만들었고, 그것이 캐시메모리.
메인메모리(DRAM)는 카페시터 하나를 씀. 따라서 일정시간이 지나면 값이 소실, 주기적으로 전원을 공급해줘야함(리프레쉬).
캐시메모리(SRAM)는 피드백회로를 가지고 있고, 소자 4개를 사용. 리프레시가 필요없으며 매우 빠름.
블록 사이즈는 캐시메모리를 3mb라고 했을 때, 하나의 블록 사이즈를 3kb로 하면 1000개가 들어감. 이 블록 하나가 캐시 라인.
필요한 데이터가 캐시 메모리에 존재하면 캐시 히트라고 부름.
문제점으로는 언제 캐시메모리로 아이템을 가져올 것인가, 주소가 존재할텐데 메인메모리의 데이터를 가져오면 똑같은 주소를 가질테니 이걸 어떻게 처리할 것인가, 꽉 차면 새로운 아이템을 집어넣어야 하는데 기존의 것들 중 어떤 것을 바꿀 것인가, 데이터가 변경되었을 때 시스템메모리(메인메모리)의 데이터랑 차이가 있는 더티메모리를 어떻게 처리할 것인가(write back:일정시간 후 한번에, write thru: 즉시) 등의 문제가 있음.
cpu에서 한번에 처리할 수 있는 데이터의 단위가 word length. 이 워드 몇 개를 묶어서 block이라 하고, 실제 데이터가 저장된 공간 왼쪽에 tag(주소)가 있고, 태그와 블록 쌍이 0부터 c-1개가 존재.
이 데이터를 맵핑시키는 방법에는 3가지가 존재.
fully associative mapping : 8자리 중 뒤의 3자리를 제외하고 00000을 태그로 가짐.

cpu에서 캐시메모리에 있는지 검색하고, 앞의 태그 부분을 비교. 메모리의 각 라인의 태그 옆에 비교회로를 쭉 놓고 그 결과가 있으면 뒷부분의 주소와 데이터를 씨피유로 전달.
이 때 만약 없으면 캐시키스, 이미 캐시의 모든 메모리가 사용되었으면 잘 안쓸 것 같은걸 없애고 집어넣음. 보통 가장 오래전에 참조된 데이터를 버림(LRU방식). 이 때, 캐시메모리에 있는 데이터가 변화하면 메인메모리에 기록. 비교회로가 비싸서 비용이 많이듦.
Direct mapping : 해결책. 인덱스에 따라 캐시메모리에 저장될 위치가 고정되어있음.
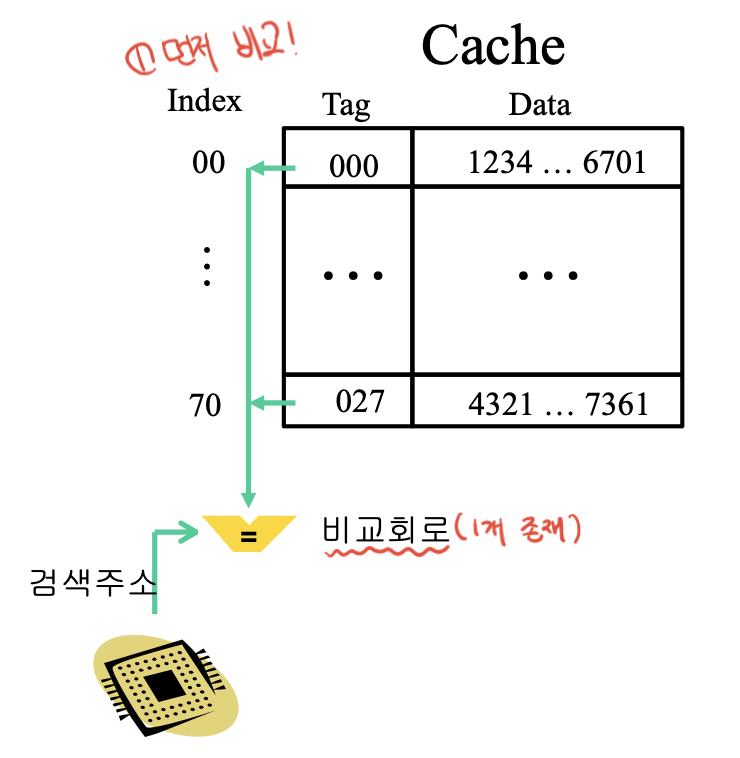
새로운 데이터가 들어오면 같은 인덱스의 데이터를 버리고 집어넣음. 문제점은 똑같은 인덱스에서 자주 참조되는 데이터가 있으면 계속 이 과정을 반복(핑퐁 현상) -> 성능저하.
set associative mapping : 위 둘을 짬뽕.
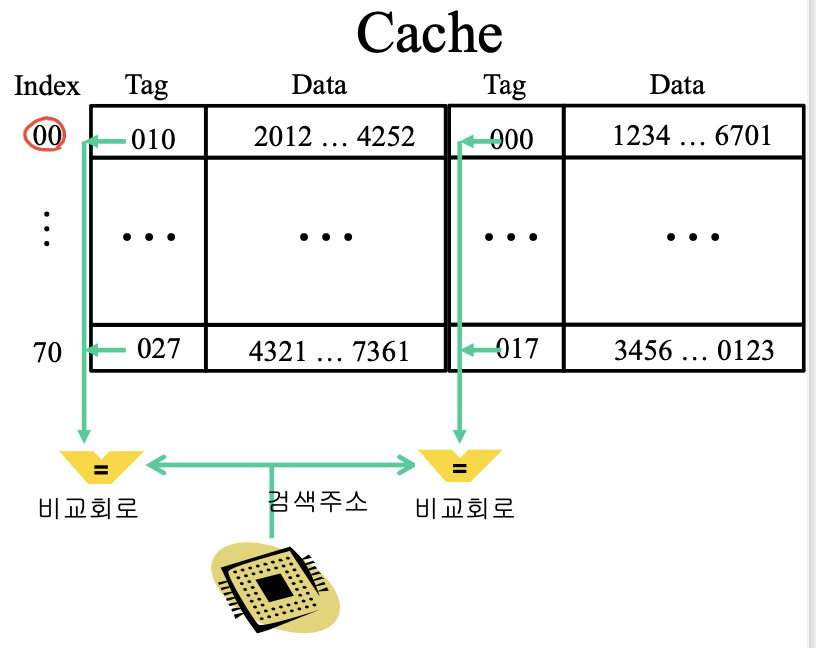
우리 pc에서는 보통 8way로 사용됨. 비교회로를 way만큼 가지게 됨. 보통 cpu에서 이 방식을 채용.
캐시메모리의 퍼포먼스 : 메인메모리 속도의 10배.
메모리 엑세스 타임 : 히트율 * 케시메모리 + (1-히트율)*(캐시+메인). 아무튼 효율적이다. 캐시메모리는 메모리와 디스크 사이에도, 네트워크 시스템 사이에도, 웹서버에도 웹캐시라는 이름으로 사용됨.
캐시메모리의 효과는 locality덕분. 로컬리티엔 시간적/공간적 부분이 있음.
루프가 돌다보면 계속 참조하는데, 캐시로 갖고오면 계속 빠르게 사용할 수 있음.
공간(스페셜 로컬리티)부분에서는, 메모리의 특정 부분을 참조하면 그 주변도 함께 참조하는 경우를 말함. 배열에서도 특정 부분을 바꾸고싶으면 같이 참조하듯이, 마찬가지.
working set : 자주 사용하는 데이터의 모음을 워킹셋이라고 함. 이걸 잘 처리하면 hit ratio를 높일 수 있으나, 현실적으로 어렵다.
disk.
대부분 플래시메모리를 사용하지만, 이전엔 디스크를 주로 사용하여 운영체제엔 디스크 관련 내용이 다수 존재.
원이 각각의 트랙으로 나뉘어져있고, 조각조각 나뉘어서 섹터라는 단위로 나뉘어짐. 디스크 헤드를 원하는 트랙의 위치로 이동시켜서 데이터를 읽게 되는데, 헤드들이 연결되어 있어 한번 헤드가 움직이면 특정 트랙으로 이동하게 되고, 다른 서페이스도 똑같은 위치에 헤드가 가게 됨. 이거를 실린더라는 용어로 트랙집합을 정의.
i/o장치(디스크포함) : 디스크에서 메모리로 정보를 가져오는 방식은 3가지가 존재.
현재 인스트럭션을 실행하고, 다음 인스트럭션이 들어오면 인터럽트가 걸려 핸들러를 실행시키고 다음 프로그램을 실행.
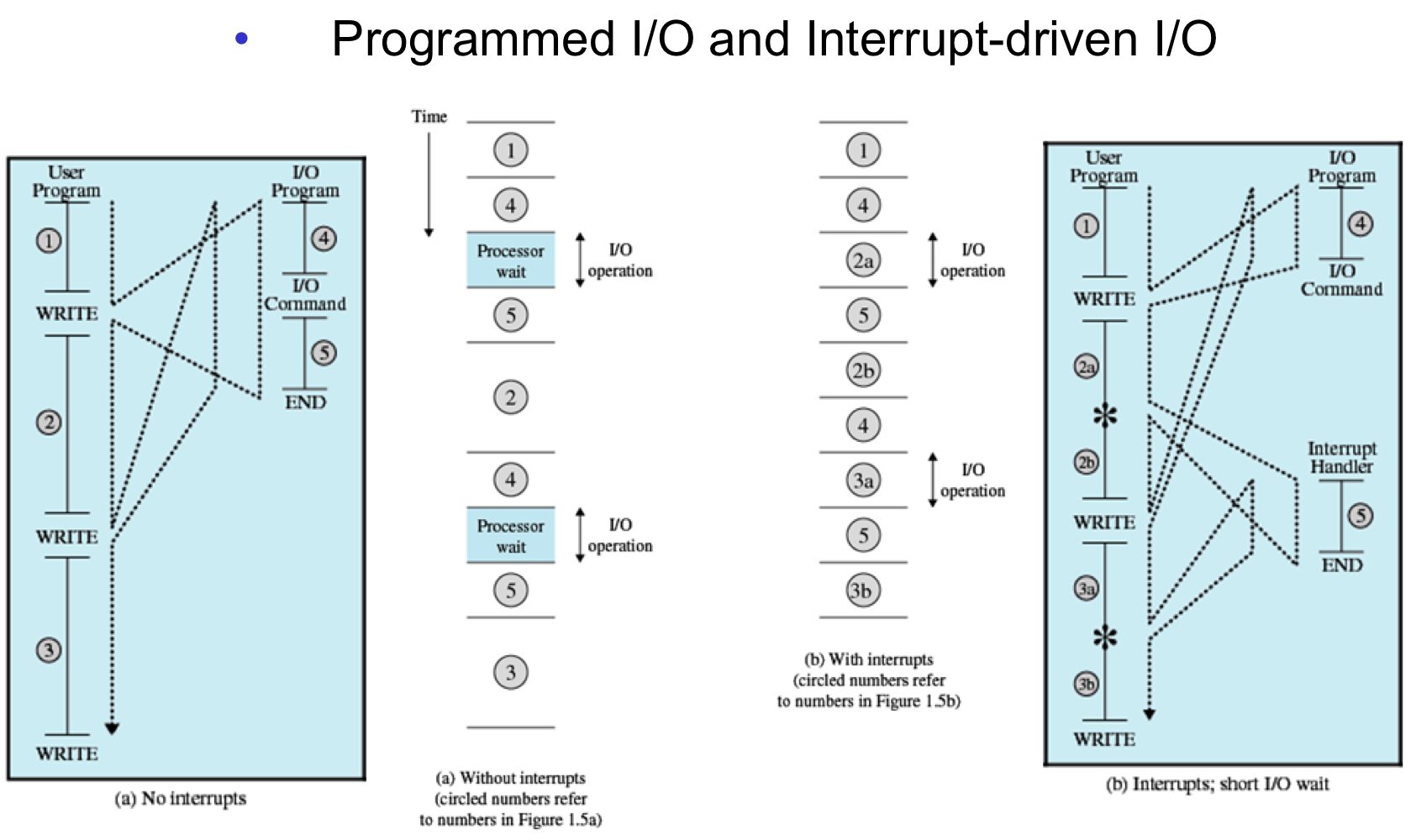
좌측 방식은 계속 쉬는시간이 발생. 우측 방식은 io프로그램을 둘로 나눠서 작동
----- 아주 절망적이게도 자료를 다 날려서 심신미약 상태....
우측 방식이 좋아보이나 현재는 그렇지 않음. why? io 명령은 느리고 cpu는 빨라 어짜피 기다려야 함.
Dual MOde ProCeSs
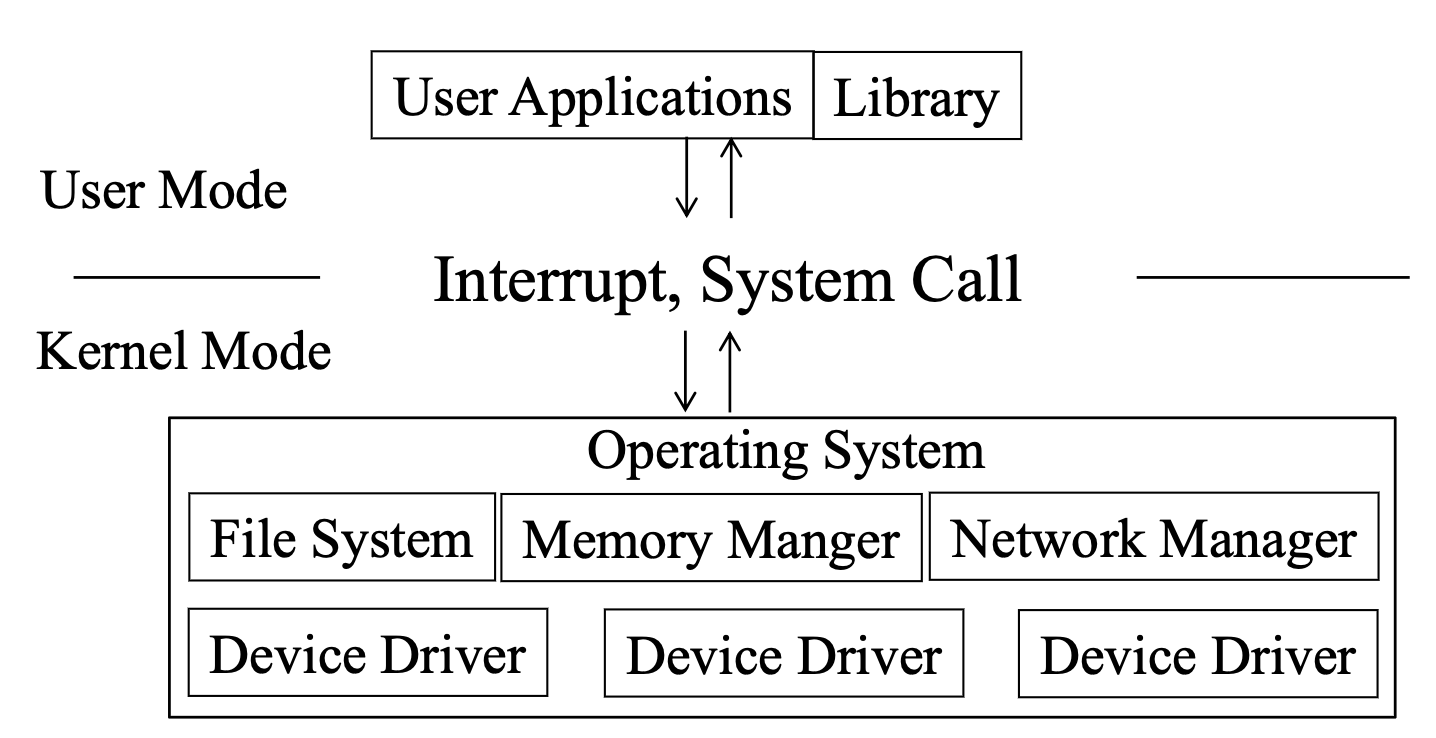
cpu는 크게 두가지 모드를 지원함.
1. 운영체제는 user program과 같이 링크되어 있음. 이 때 서로 io를 요청하면 복잡하기에 cpu에서는 모듈 두 개를 만들어서 지원.
user mode에서는 유저 프로그램이, kernel mode 에서는 운영체제가 동작하도록 함. 특권 명령어는 커널모드에서만 동작가능.
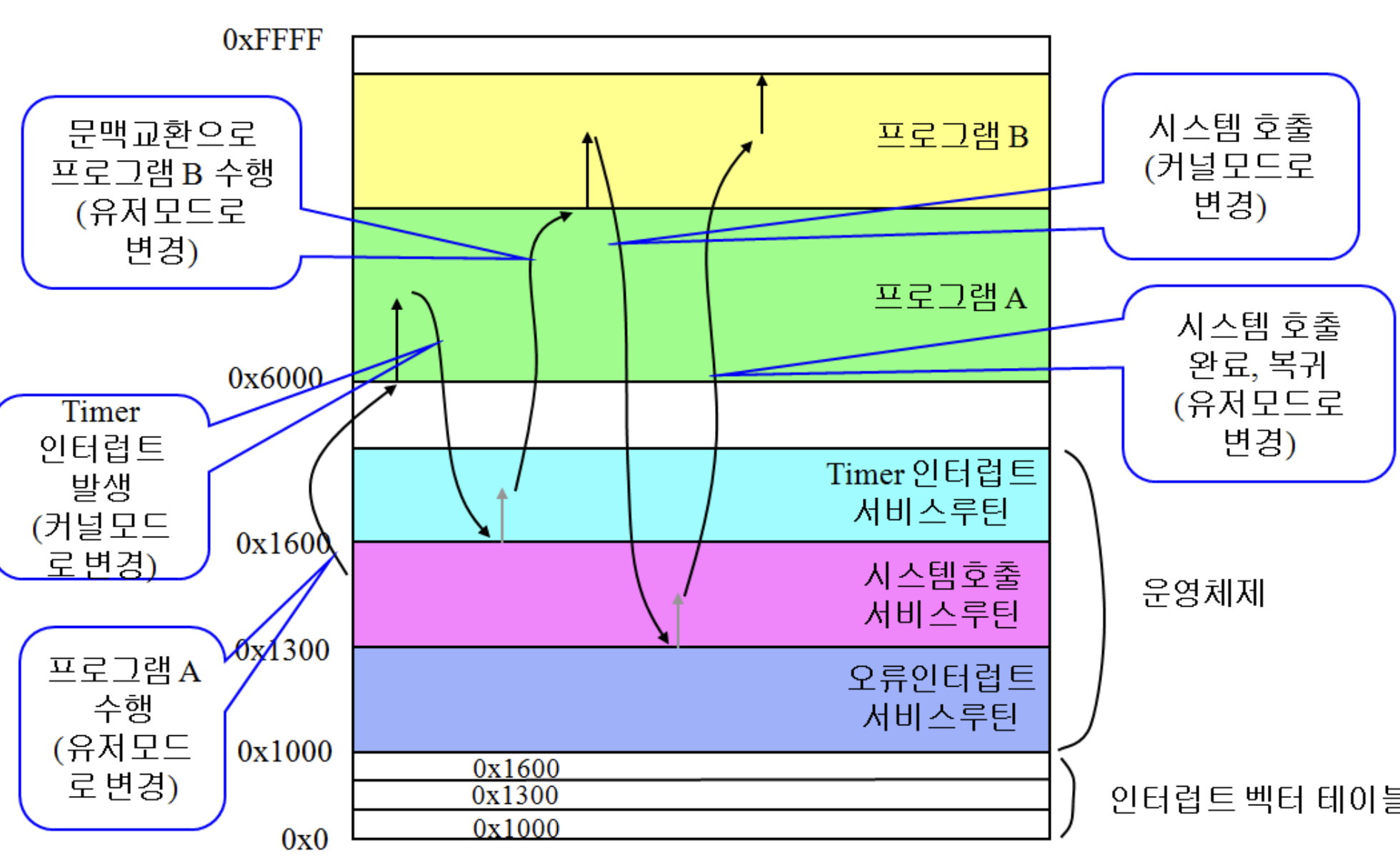
좀 더 상세하게 보면, 메모리를 쭉 따라가다가 timer 인터럽트에선 시간 관련 정보를 업데이트를 하고, 마지막엔 스케쥴링을 함.
타이머 인터럽트가 뜰 때 마다 프로세스에게 주어진 시간이 전부 소비되었는지를 확인하고, 다음으로 어떤 것을 실행할지 결정하게 됨. 이게 스케쥴러의 역할이고, 이걸 타이머 인터럽트 서비스 루틴이 진행되고, 그림에서 b로 복귀하게 됨.
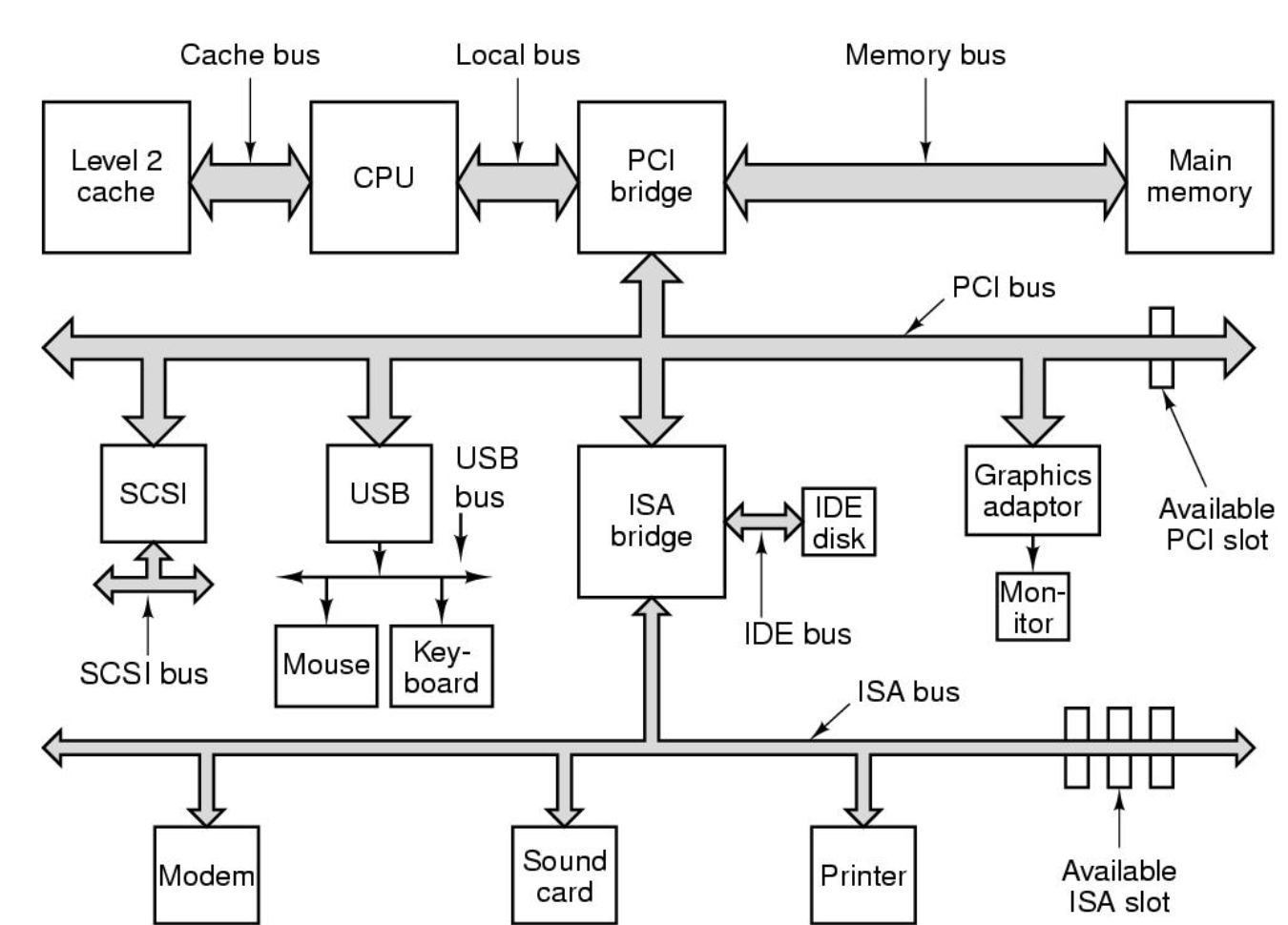
아주 옛날엔, 컴퓨터가 빠르지 않았고 그 때 쓰던 버스가 ISA버스.
이미지의 맨 위에, 요즘은 cpu와 메모리가 할 일이 많아 Cache bus, memory bus라는 전용 버스를 연결. pci버스(메인보드에 주변장치 연결)도 존재.
이 모든것(ISA,PCI)들을 연결시켜주는 것이 ISA브릿지.
1.4 운영체제 동물원
운영체제의 종류
메인 프레임 : 예전 것.
현재 운영체제는 모두 멀티프로세서 오퍼레이팅 시스템. 대세이나 성능쥐어짜기가 심함.
퍼스널 컴퓨터 오퍼레이팅 시스템 : windows, mac os, linux
핸드헬드(ios, and). 임베디드, 센서 : 리눅스
리얼타임 : 별개의 것
스마트 카드 : 학생증 내부의 칩 오퍼레이팅 시스템 같은 것을 의미.
1.5 운영체제 개념
operating system concepts
프로세스 : 중요
파일 : 우리가 아는 파일 뿐만 아니라, 예전엔 주변장치도 포함(디바이스 파일)
ontogeny recapitulates phylogy : 예전 운영체제는 이런 기능이 필요 없었음(구형 폴더폰을 생각)
어떤 특정 분야의 운영체제가 발전하면 다른 분야의 운영체제도 발전케 됨. 예전의 분산시스템 쓸모없다고 여기다가 요즘엔 클라우드컴퓨팅으로 각광받음.
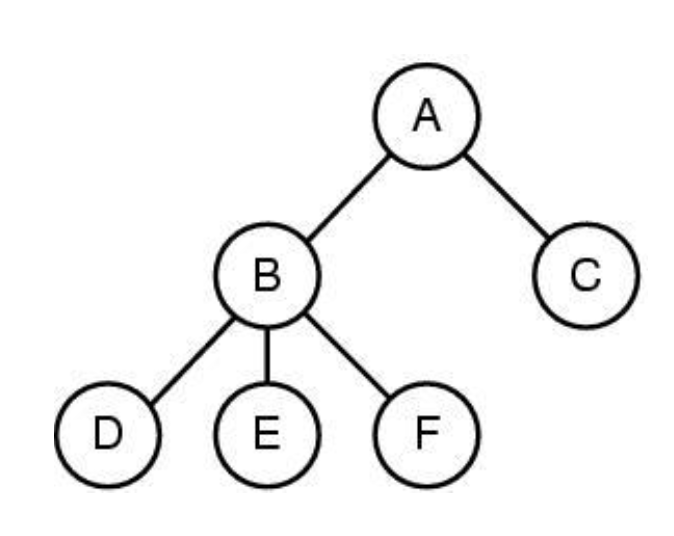
프로세스는 실행의 주체. 혼자 할 수 없음. 누가 실행시켜줘야하고, 그림에서 B라는 쉘 프로그램의 자식이 되는 것. 계층구조 -> 부모자식의 관계를 가짐
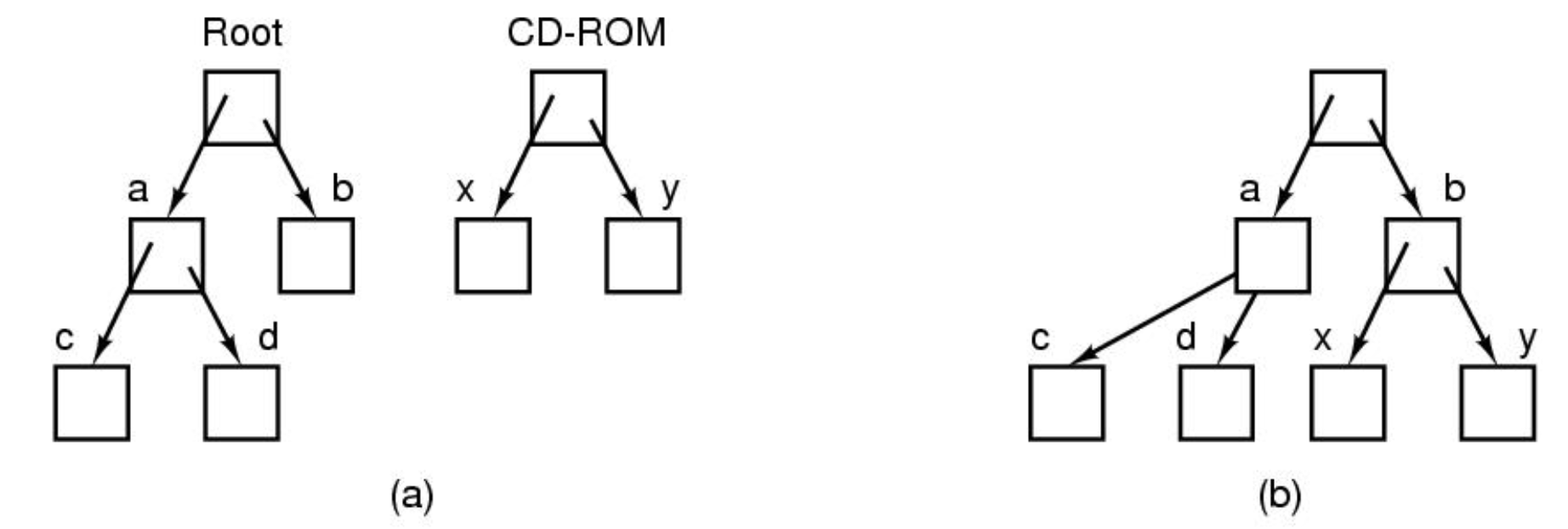
파일 이미지는 파일들의 계층구조를 보여주는데, 과거엔 디렉토리 구분 없이 단일 레이어였음.
좌측은 윈도우, 우측은 리눅스 시스템. 윈도우는 각 파일 시스템(파티션) 마다 계층 구조를 따로 갖고 있음. 유닉스는 하나의 파일 트리.
pipe라는건 대형 프로그램에서 프로세스 여러개를 사용할 때, 독립된 프로세스들 끼리 데이터를 주고받아야 했는데 그 때 파이프를 사용.
디스크에 접근하지 않고 메모리로 주고받음.
system call : 하..
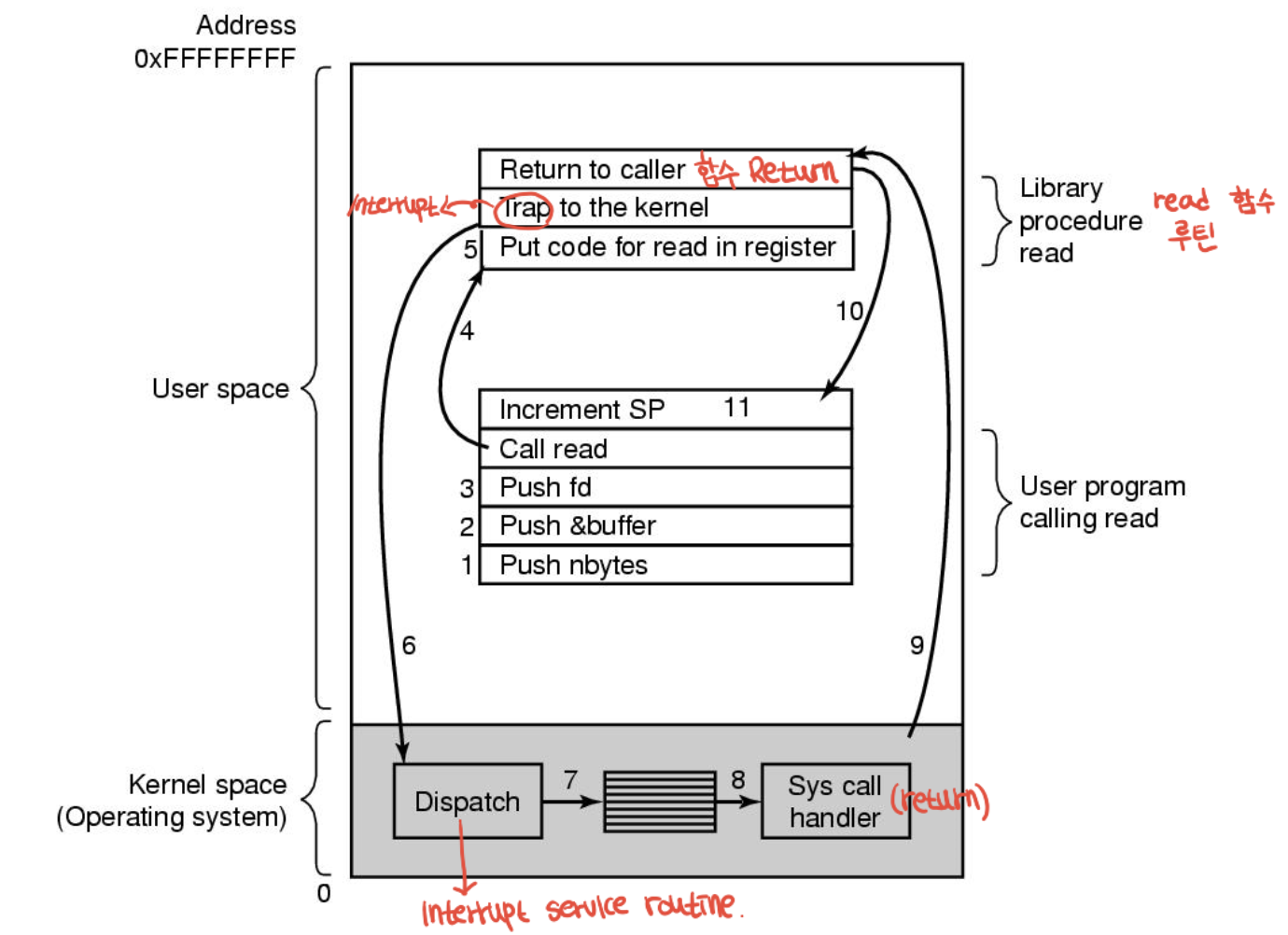
1~3 : 인자들을 스택에 푸시
4 : 라이브러리 함수 호출 5 : 어셈블리어 라이브러리 함수는 운영체제가 예상하는 위치(특정 레지스터 등)에 호출 번호 기입
6 : Trap명령 실행, 커널모드로 전환하여 실행 시작
7 : 시스템 호출 번호 확인(핸들러 가리키는 포인터를 담은 테이블을 시스템 호출 번호로 인덱스해서 사용)
8 : 커널 코드가 시스템 호출 핸들러 실행 9 : 완료시 라이브러리 함수에서 트랩 다음 명령으로 제어권 넘김
10 : 프로그램에게 반환 11 : 스택 정리
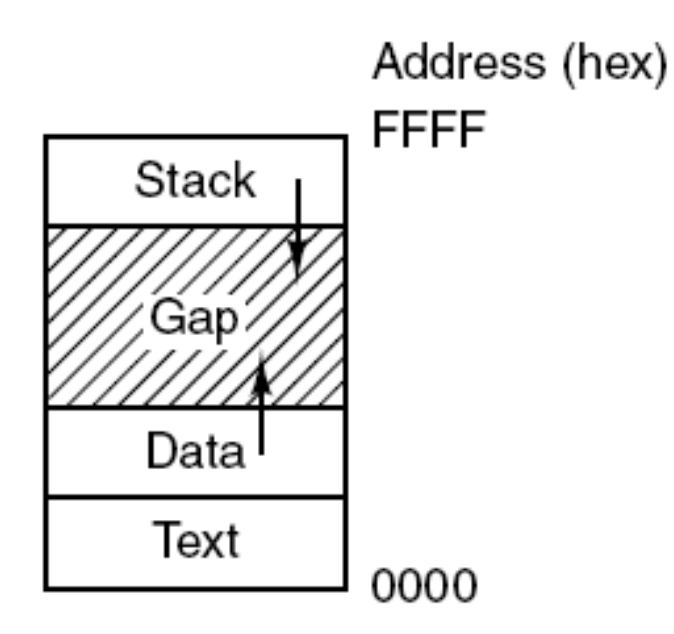
메모리 레이아웃. 모든 프로세스는 이미지와 같은 형태를 지님. gap은 동적 메모리영역(힙)
유닉스는 파일을 아이노드로 저장. 각 파일마다 번호를 할당하고, 아이노드만 가지고 모든 연산을 처리할 수 있음.
그래서 디렉토리를 만들고, 아이노드와 파일 이름 쌍을 만들어서 디렉토리 데이터로 저장. 이것이 계층구조를 나타냄.
링크는 왜 만들었냐. 유닉스는 여러명이서 쓰던 것. 이런 시분할 운영체제에서는 다중 사용자가 시스템에 로그인하여 서비스를 바꿈.
한 쪽이 지워도 다른쪽에 살아 있는 것이 하드 링크.
이걸 보완하기 위해 소프트 링크도 존재.
'UOS > UOS@운영체제' 카테고리의 다른 글
| [운영체제] 3. 프로세스 & 스레드(4.8/5) (0) | 2023.04.16 |
|---|---|
| [운영체제] 3. 프로세스 & 스레드(4/5) (0) | 2023.04.16 |
| [운영체제] 3. 프로세스 & 스레드(3/5) (0) | 2023.04.15 |
| [운영체제] 3. 프로세스 & 스레드(2/4) (0) | 2023.04.15 |
| [운영체제] 1. 운영체제 서론(2/2), 프로세스 & 스레드(1/2) (0) | 2023.04.13 |